一、多表联合查询
通过连接可以建立多表查询,多表查询的数据可以来自多个表,但是表之间必须有适当的连接条件。。一般N个表进行连接,需要至少N-1个连接条件,才能够正确连接
二、 相等连接
两个表具有相同意义的列,建立相等连接条件。使用相等连接进行两个表的查询时,只有连接列上在两个表中都出现且值相等的行才会出现在查询结果中。
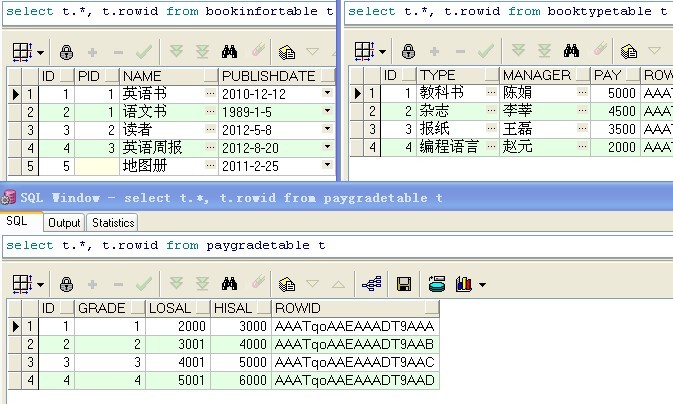
2.1 建表:
sql: CREATE TABLE bookInfortable (id int NOT NULL primary key,pid int null,name varchar(50) NULL,publishdate date NOT NULL);
(id,pid对应 bookTypetable 的id所属类型,name书名, publishdate出版日期 )
sql: CREATE TABLEbookTypetable (id int NOT NULL primary key,type varchar(50) NOT NULL,manager varchar(50) NOT NULL,payint NOT NULL );
(id,type类型,manager 管理员 ,)
sql: CREATE TABLEpayGradeTable (id int NOT NULL primary key,Grade int NOT NULL,LOSAL NUMBER NOT NULL,HISAL NUMBER NOT NULL);
(id,Grade 等级,LOSAL 最低标准 ,HISAL 最高标准)

2.2 相等连接
sql: SELECT a.id,a.name,a.publishdate,a.pid,b.id,b.type,b.manager FROMbookinfortable a ,booktypetable b WHERE a.pid=b.id ;

说明: 在FROM从句中依次列出两个表的名称,在表的每个列前需要添加表名,用“.”分隔,表示列属于不同的表。在WHERE条件中要指明进行相等连接的列。如果表名很长,可以为表起一个别名,进行简化,别名跟在表名之后,用空格分隔。( bookinfortable a 指 bookinfortable 别名 a)
2.3 相等连接附加判断条件
sql: SELECT a.id,a.name,a.publishdate,a.pid,b.id,b.type,b.manager FROMbookinfortable a ,booktypetable b WHEREa.pid=b.id and a.name != '读者' ;

三、外连接
除了显示满足相等连接条件的记录外,还显示那些不满足连接条件的行,不满足连接条件的行将显示在最后。外连操作符为(+),它可以出现在相等连接条件的左侧或右侧。出现在左侧或右侧的含义不同,
sql: SELECT a.id,a.name,a.publishdate,a.pid,b.id,b.type,b.manager FROMbookinfortable a ,booktypetable b WHEREa.pid(+)=b.id ;

sql: SELECT a.id,a.name,a.publishdate,a.pid,b.id,b.type,b.manager FROMbookinfortable a ,booktypetable b WHEREa.pid=b.id(+) ;

说明: 左 连接 显示后表 中不满足连接条件的行;右 链接 显示前表 中不满足连接条件的行
四、不等连接
sql: SELECT b.id, b.type,b.manager,b.pay,p.grade,p.losal,p.hisal FROM booktypetable b,paygradetable p WHERE b.pay BETWEEN p.losal AND p.hisal;
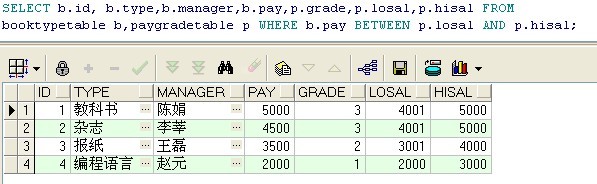
说明: 查询管理员的工资所在等级,通过将 管理员工资与不同的工资上下限范围相比较,取得工资的等级,并在查询结果中显示出雇员的工资等级。
五、自连接
自连接就是一个表,同本身进行连接。对于自连接可以想像存在两个相同的表(表和表的副本),可以通过不同的别名区别两个相同的表。
5.1建表
sql: CREATE TABLE workertable(id int NOT NULL primary key,name varchar(50) NOT NULL,manageridint NULL);

5.2 显示雇员名称和雇员的经理名称
sql: SELECT worker.id,worker.name||' 的经理是 '||manager.name AS 雇员的经理 FROM workertable worker, workertable manager WHERE worker.managerid = manager.id order by worker.id;

说明: 为 workertable 表分别起了两个别名worker和manager,可以想像,第一个表是雇员表,第二个表是经理表,因为经理也是雇员。然后通过worker 表的 managerid 字段同manager 表的id字段建立连接
六、统计查询
Oracle提供了一些函数来完成统计工作,这些函数称为组函数 ,组函数不同于前面介绍和使用的函数(单行函数)。组函数可以对分组的数据进行求和、求平均值等运算。组函数只能应用于SELECT子句、HAVING子句或ORDER BY子句中。组函数也可以称为统计函数。
| 函 数 | 说 明 |
| AVG | 求平均值 |
| COUNT | 求计数值,返回非空行数,*表示返回所有行 |
| MAX | 求最大值 |
| MIN | 求最小值 |
| SUM | 求和 |
| STDDEV | 求标准偏差,是根据差的平方根得到的 |
| VARIANCE | 求统计方差 |
分组函数中SUM和AVG只应用于数值型的列,MAX、MIN和COUNT可以应用于字符、数值和日期类型的列。组函数忽略列的空值。使用GROUP BY 从句可以对数据进行分组。所谓分组,就是按照列的相同内容,将记录划分成组,对组可以应用组函数。如果不使用分组,将对整个表或满足条件的记录应用组函数。在组函数中可使用DISTINCT或ALL关键字。ALL表示对所有非NULL值(可重复)进行运算(COUNT除外)。DISTINCT 表示对每一个非NULL值,如果存在重复值,则组函数只运算一次。如果不指明上述关键字,默认为ALL。
6.1 COUNT
sql: SELECT COUNT(*) FROM bookinfortable t; 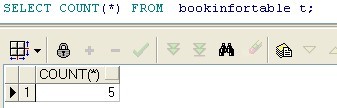
说明: 使用组函数COUNT统计记录个数;*代表返回所有行数,否则返回非NULL行数。
sql: SELECT COUNT(pid) FROM bookinfortable t;

说明: 返回pid非空的数量
sql: SELECT COUNT( DISTINCT pid) FROM bookinfortable ;
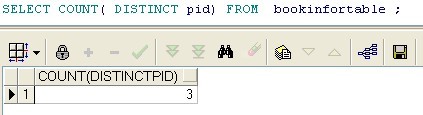
说明: 该查询返回bookinfortable 表中不同pid个数,不包括空的。如果不加DISTINCT,则返回的是非空的个数。
6.2 AVG
sql: SELECT AVG(t.pay) FROM booktypetable t WHERE t.pay>2000;

说明: 增加了WHERE条件,WHERE条件先执行,在进行均分
6.3 MAX(),MIN()
sql: SELECT MAX(publishdate) 最大日期,MIN(publishdate) 最小日期 FROM bookinfortable;

6.4 分组统计
前提:对booktypetable增加一行相同type的数据

sql: SELECT type,SUM(pay) FROM booktypetable GROUP BY type;

说明: 按类型分组,有多少种不同类型就分多少组,并将相同组的工资进行求和。分组查询允许在查询列表中包含分组列,在查询列中,不能使用分组列以外的其他列,否则会产生错误信息。
6.5 HAVING
重点:区分 having 与 where
1、having子句与where都是设定条件的语句。
2、优先 执行顺序:where子句 >(sum,min,max,avg,count)>having子句
3、 对分组数据再次判断时要用having。如果不用这些关系就不存在使用having。直接使用where就行了。
where sql : select t.type,t.manager, max(t.pay) from booktypetable t where t.manager!='李莘' group by( t.type,t.manager ) ;

having sql: select t.type, max(t.pay) from booktypetable t group by t.type having max(t.pay)>3500;

where and having sql: select t.type,t.manager, max(t.pay) from booktypetable t where t.manager!='李莘' group by ( t.type,t.manager ) having max(t.pay)>3500;
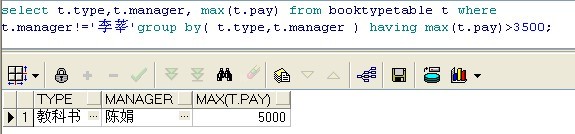
说明: HAVING从句的限定条件中要出现组函数。如果同时使用WHERE条件,则WHERE条件在分组之前执行,HAVING条件在分组后执行。
6.6 order by 排序
sql: select t.type 类型, t.manager 管理员,t.pay 工资 from booktypetable t order by 工资;
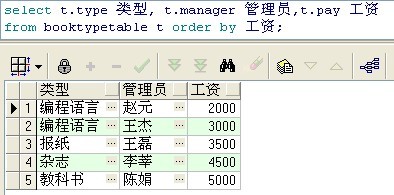
说明: order by后面可以跟别名也可以跟数据库字段
6.7 组函数的嵌套使用
sql: select min(avg(t.pay)) from booktypetable t GROUP BY t.type;

错误: select t.type ,min(avg(t.pay)) from booktypetable t GROUP BY t.type;这个语句是错误的,因为各类型平均工资的最低值不是属于某个部门的
说明: 该查询先统计各部门的平均工资,然后求得其中的最大值。虽然在查询中有分组列,但在查询字段中不能出现分组列。
6.8 子查询
通过把一个查询的结果作为另一个查询的一部分,可以实现这样的查询功能。。子查询比主查询先执行,结果作为主查询的条件,在书写上要用圆括号扩起来,并放在比较运算符的右侧。子查询可以嵌套使用,最里层的查询最先执行。子查询可以在SELECT 、INSERT 、UPDATE 、DELETE等语句中使用。
sql: SELECT b.* FROM booktypetable b WHERE b.pay>(SELECT t.pay FROM booktypetable t WHERE t.manager='王磊');

sql: SELECT b.* FROM booktypetable b WHERE b.pay>(SELECT t.pay FROM booktypetable t WHERE t.manager='赵元') and b.type=(SELECT t.type FROM booktypetable t WHERE t.manager='赵元');

说明: 两个子查询出现在两个条件中,用AND连接表示需要同时满足。在子查询中也可以使用组函数。
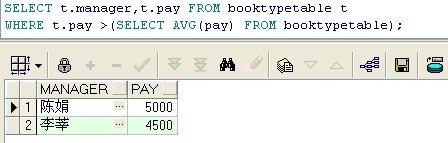
sql: SELECT t.manager,t.pay FROM booktypetable t WHERE t.pay >(SELECT AVG(pay) FROM booktypetable);
6.9 多行子查询
原表中增加数据

sql: SELECT b.* FROM booktypetable b WHERE b.pay < ANY (SELECT t.pay FROM booktypetable t WHERE t.type ='杂志') AND b.type <> '杂志';
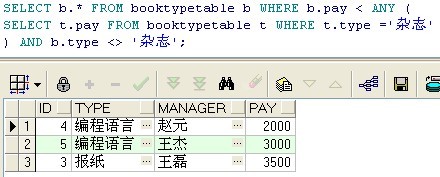
说明: 如果子查询返回多行的结果,则我们称它为多行子查询。多行子查询要使用不同的比较运算符号,它们是IN、ANY和ALL。
6.10 多列子查询
如果子查询返回多列,则对应的比较条件中也应该出现多列,这种查询称为多列子查询。
例:查询职务和部门与SCOTT相同的雇员的信息。
* 再次强调rownum的查询
6.10 集合运算
| 操 作 | 描 述 |
| UNION | 并集,合并两个操作的结果,去掉重复的部分 |
| UNION ALL | 并集,合并两个操作的结果,保留重复的部分 |
| MINUS | 差集,从前面的操作结果中去掉与后面操作结果相同的部分 |
| INTERSECT | 交集,取两个操作结果中相同的部分 |