B+树主键索引图解
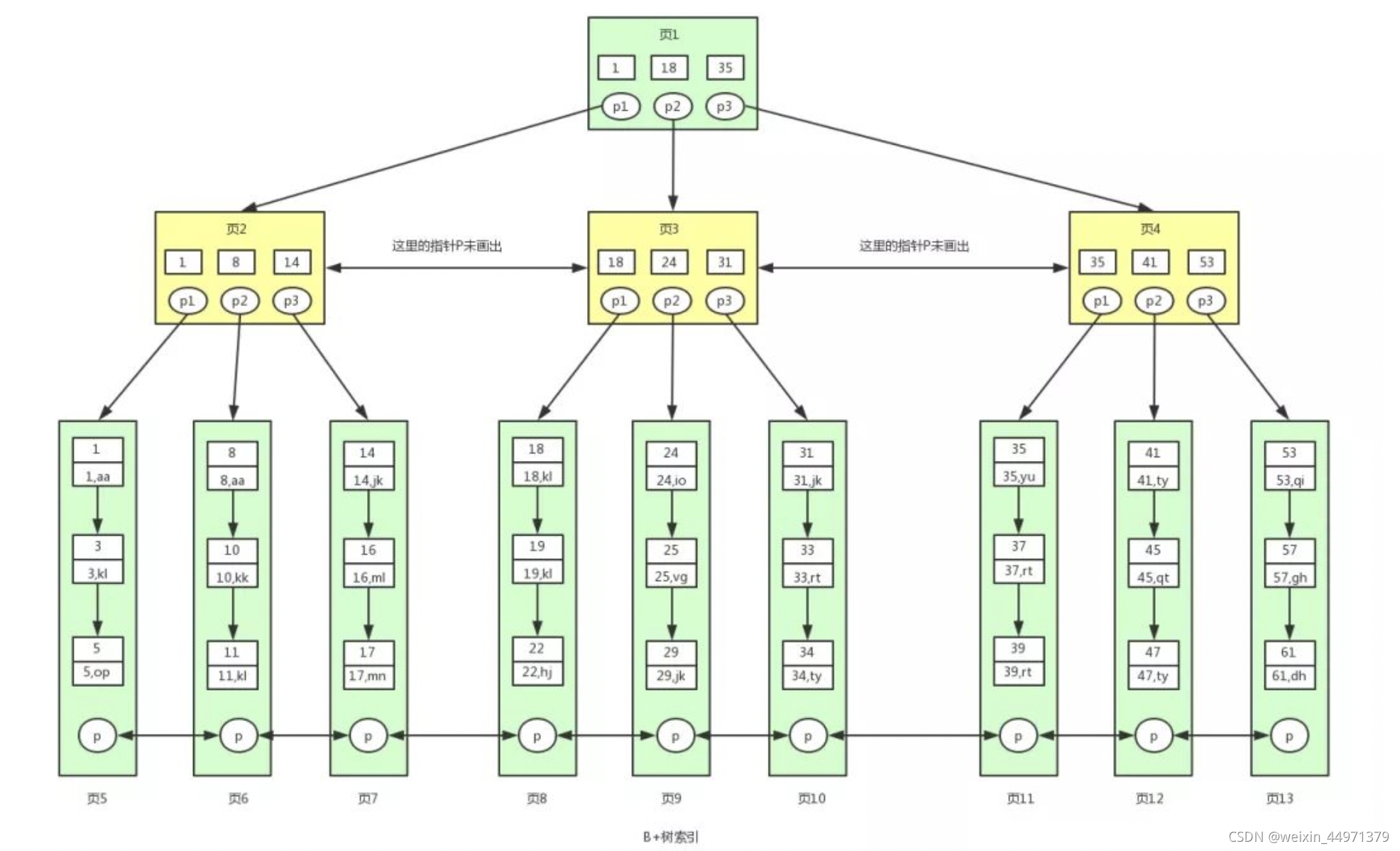
查询流程:select * from user where id>=18
1. 一般根节点都是常驻内存的,也就是说页1已经在内存中了,此时不需要到磁盘中读取数据,直接从内存中读取即可。
从内存中读取到页1,要查找这个id>=18或者范围值,我们首先需要找到id=18的键值。
从页1中我们可以找到键值18,此时我们需要根据指针p2,定位到页3。
2. 要从页3中查找数据,我们就需要拿着p2指针去磁盘中进行读取页3。
从磁盘中读取页3后将页3放入内存中,然后进行查找,我们可以找到键值18,然后再拿到页3中的指针p1,定位到页8。
3. 同样的页8页不在内存中,我们需要再去磁盘中将页8读取到内存中。
将页8读取到内存中后。
因为页中的数据是链表进行连接的,而且键值是按照顺序存放的,此时可以根据二分查找法定位到键值18。
此时因为已经到数据页了,此时我们已经找到一条满足条件的数据了,就是键值18对应的数据。
因为是范围查找,而且此时所有的数据又都存在叶子节点,并且是有序排列的,那么我们就可以对页8中的键值依次进行遍历查找并匹配满足条件的数据。
我们可以一直找到键值为22的数据,然后页8中就没有数据了,此时我们需要拿着页8中的p指针去读取页9中的数据。
4. 因为页9不在内存中,就又会加载页9到内存中,并通过和页8中一样的方式进行数据的查找,直到将页13加载完毕,则获得所有记录.
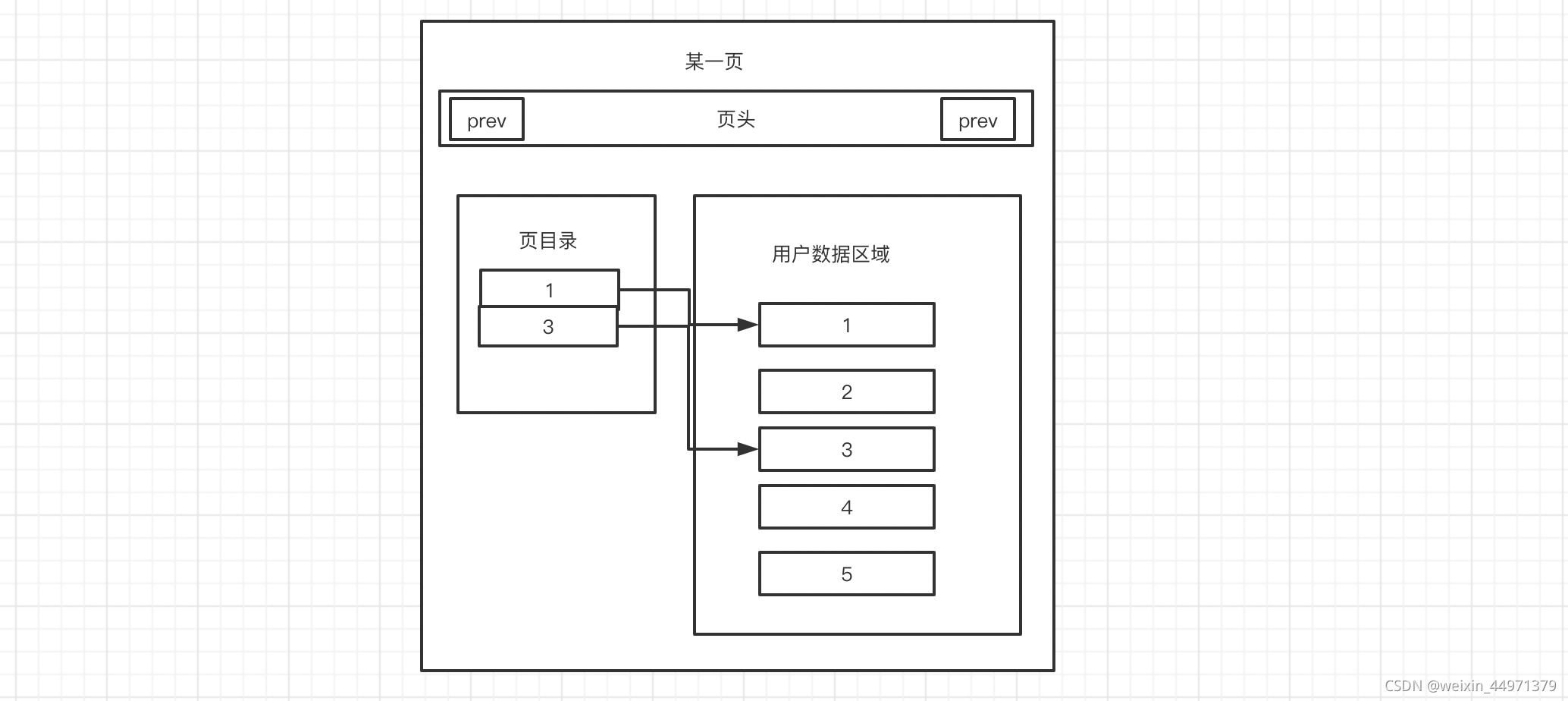
数据页详解
辅助索引
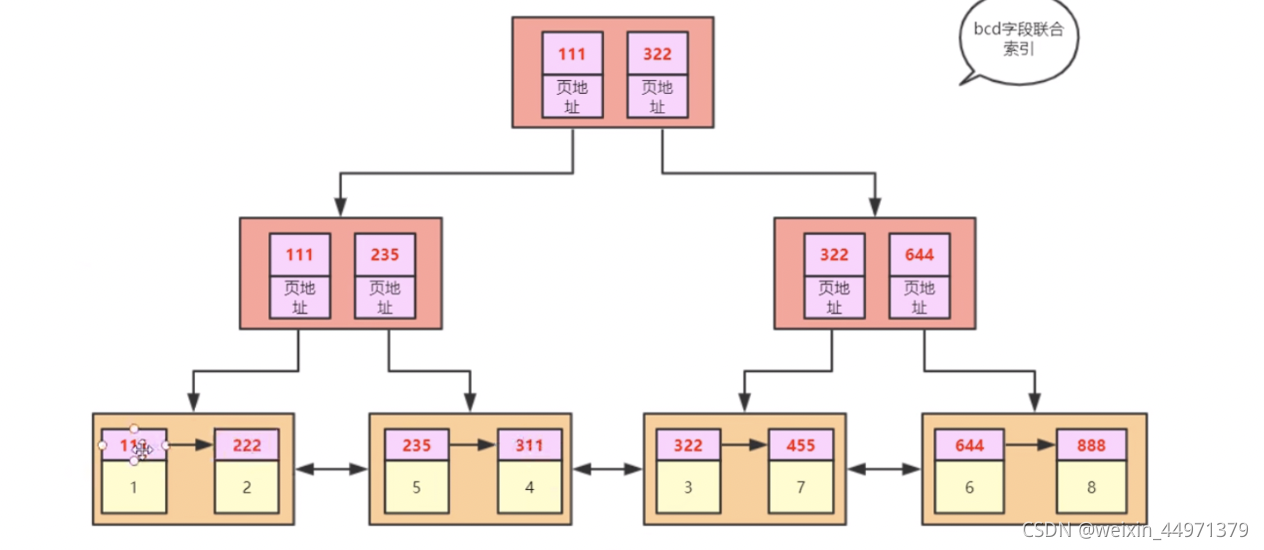
索引本质
索引本身是一种数据结构,存放着每条数据在磁盘上对应的地址
数据结构
1:数组
需要进行扩容,插入慢,查找快
2:单向链表
由多个节点组成,每个节点存储数据和下个节点的地址,插入快,查找慢,增加数据不需要扩容,修改节点的指针域即可
3:双向链表
解决单向链表只能向前不能向后的问题,由多个节点组成。每个节点存储数据以及上个节点,下个节点的指针
4:二叉树
如果插入元素是有序的二叉树会退化成链表(斜树)
5:平衡二叉树(AVL)
每个节点存放节点元素,左下节点指针,右下节点指针,通过左旋右旋控制树的平衡
6:多路平衡查找树:B树
节点可以拥有多个子节点数量,减少深度,减少IO
节点关键数为n,子节点数量n+1
7:b+树->加强版的多路平衡查找树
节点的关键数为n,子节点数量也为n,只有叶子节点才存放数据
数据表引擎
1:Myism
索引和数据分别存放
2:Innob
索引和数据存放在同一个文件中,主键索引为聚集索引,其他索引(二级索引,辅助索引)都为非聚集索引
聚集索引
1:如果一个表有主键,则主键就是聚集索引
2:无主键,则选用索引为Unique且列不含null值的字段
3:否则使用内置的可自增的rowid
列的离散度
计算公式:SELECT COUNT(DISTINCT(colum))/COUNT(*) from table
数据重复度越高,离散度越低,扫描越慢,不适合建索引
索引查看
show indexes from table;
Cardinality表示对应索引字段不重复的行数
执行计划查看
通过explain + sql 可以查看sql 的执行情况
聚合索引(遵循最左原则)
联合索引建立以后索引如何会被使用:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(48) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`email` varchar(48) DEFAULT NULL,
`address` varchar(48) DEFAULT NULL,
`sex` varchar(4) DEFAULT NULL,
`crt_time` varchar(50) DEFAULT NULL,
`upd_time` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `unit` (`name`,`age`,`email`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8;
WHERE name=‘slave’ and age=‘10’ and
email=‘158970’
重点:从左开始,且不可跳过
覆盖索引:Using index
显示列所需要的字段,建有索引,没有其他非索引字段,则不需要回表,会使用覆盖索引
创建索引:
1:where判断条件,order排序,join连接的on字段
2:索引个数不宜太多,本身也是数据结构,太多会造成写入的性能变差
3:列散列度太低,不要建索引
4:频繁更新的值,不作为主键或者是索引
5:联合索引,将散列度高的字段放在前面
6:复合索引存在以后,不需要再建立单例索引
7:无序的字段不建立索引(身份证号,UUID)
索引失效
1:索引列进行函数计算
2:字符串where条件未加引号,会发生隐式的转换
3:like 条件以%起始
操作系统从磁盘取数据最小单位为页,1页=4kb
局部性原理:操作系统从某个地址获取数据时,会把周围的数据同时获取到(操作系统会认定周围的数据也会马上被使用到)