机器学习科普
机器学习科普
一、什么是机器学习?
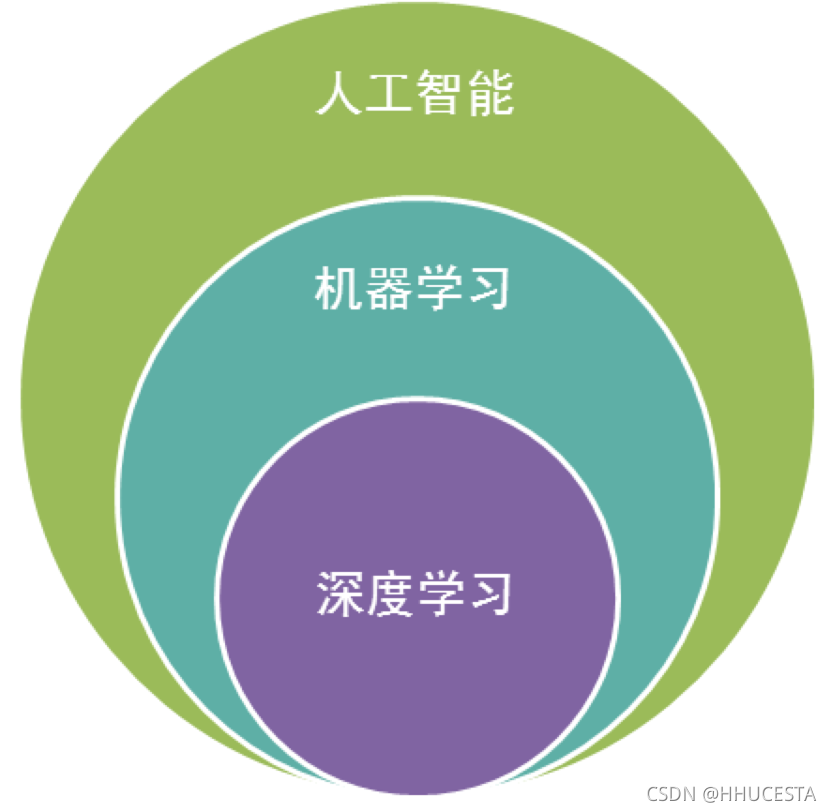
机器,一般指的就是我们的计算机;学习指的是我们通过一些算法使得计算机能够模拟或实现人的学习行为

传统上,咱们的电脑程序在我们写下后,我们就知道他们是干啥的,一行行代码逐步执行,他的作用已经被我们写死了,没有自己成长的空间和机会。
那么机器学习中呢,机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法。这听起来非常不可思议,但结果上却是非常可行的。“统计”思想将在你学习“机器学习”相关理念时无时无刻不伴随,相关而不是因果的概念将是支撑机器学习能够工作的核心概念。我们写下的代码不是让他们做固定的工作,而是教他们沿着某一途径学习。
我们通过一个问题来引入

要想解决这个问题,有好几种方法。第一种方法是采用知识:我搜寻能够解决这个问题的知识。但很遗憾,没有人会把如何等人这个问题作为知识传授,因此我不可能找到已有的知识能够解决这个问题。第二种方法是问他人:我去询问他人获得解决这个问题的能力。但是同样的,这个问题没有人能够解答,因为可能没人碰上跟我一样的情况。第三种方法是准则法:我问自己的内心,我有否设立过什么准则去面对这个问题?例如,无论别人如何,我都会守时到达。但我不是个死板的人,我没有设立过这样的规则。那么还有一种方法可能比这三种方法更可靠,如下:
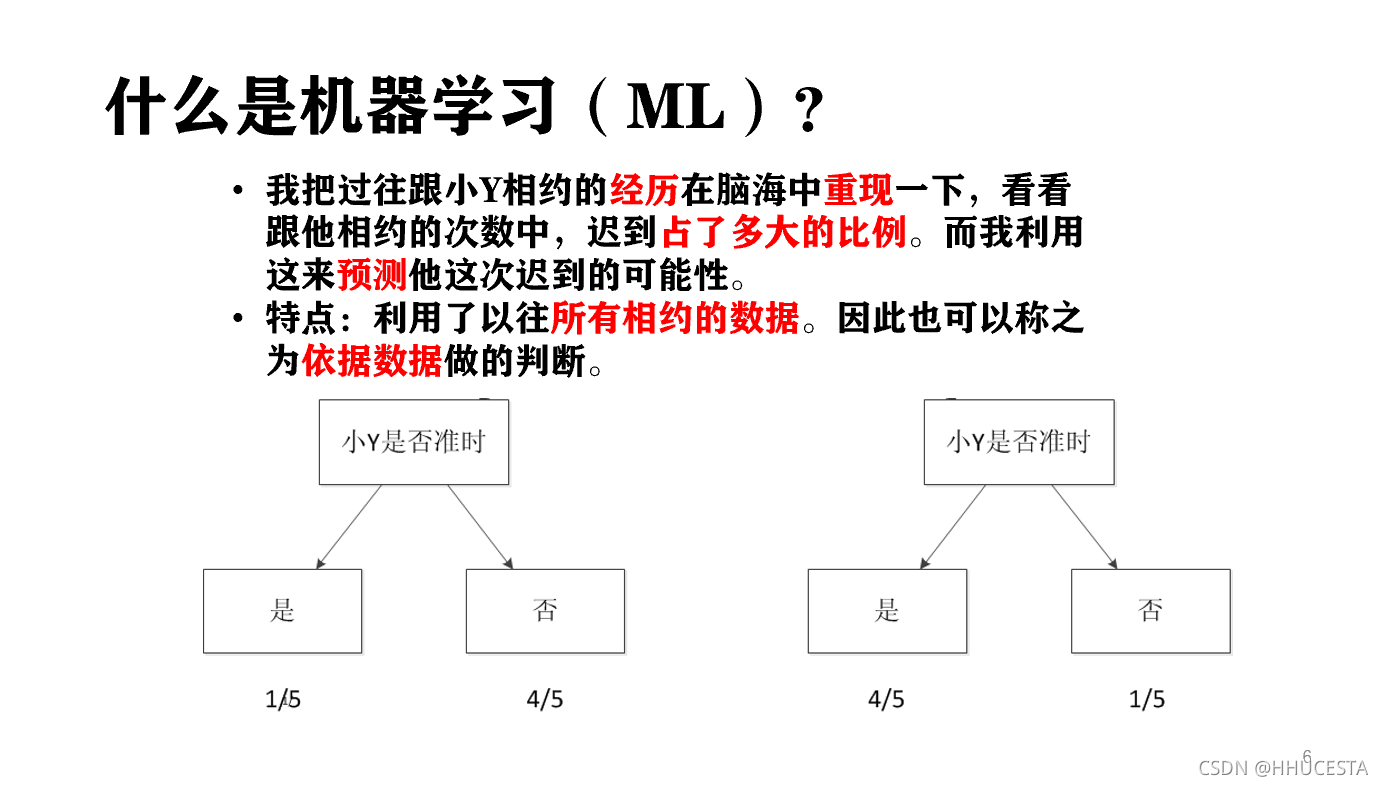
假如说我在心中设置了某个界限,如果小Y准时的可能性这个值低于了我心里的某个界限,那我选择等一会再出发。假设我跟小Y约过5次,他迟到的次数是1次,那么他按时到的比例为80%,我心中的阈值为70%,我认为这次小Y应该不会迟到,因此我按时出门。如果小Y在5次迟到的次数中占了4次,也就是他按时到达的比例为20%,由于这个值低于我的阈值,因此我选择推迟出门的时间。这个方法从它的利用层面来看,又称为经验法。在经验法的思考过程中,我事实上利用了以往所有相约的数据。因此也可以称之为依据数据做的判断。
刚才的思考过程我只考虑“频次”这种属性。一般的机器学习模型至少考虑两个量:一个是因变量,也就是我们希望预测的结果,在这个例子里就是小Y迟到与否的判断。另一个是自变量,也就是用来预测小Y是否迟到的量。假设我把时间作为自变量,譬如我发现小Y所有迟到的日子基本都是星期五,而在非星期五情况下他基本不迟到。于是我可以建立一个更复杂的模型,来模拟小Y迟到与否跟日子是否是星期五的概率。见下图:

那么下面这些数据能就是我们把我们收集到的数据喂给这个模型,这里实际上有点以频率近似概率的意思
这样的图就是一个机器学习模型,称之为决策树。
机器学习也可以根据现实情况提供我们该迟多久出门的建议,但这可能就需要用到线性回归或者其他算法了,决策树不能很好的支持非离散值的决策。
做个总结,机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型预测未来(是否迟到)的一种方法。

通过上面的分析,可以看出机器学习与人类思考的经验过程是类似的,不过它能考虑更多的情况,执行更加复杂的计算。事实上,机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。经过计算机得出的模型能够以近似于人的方式解决很多灵活复杂的问题。
二、机器学习的定义
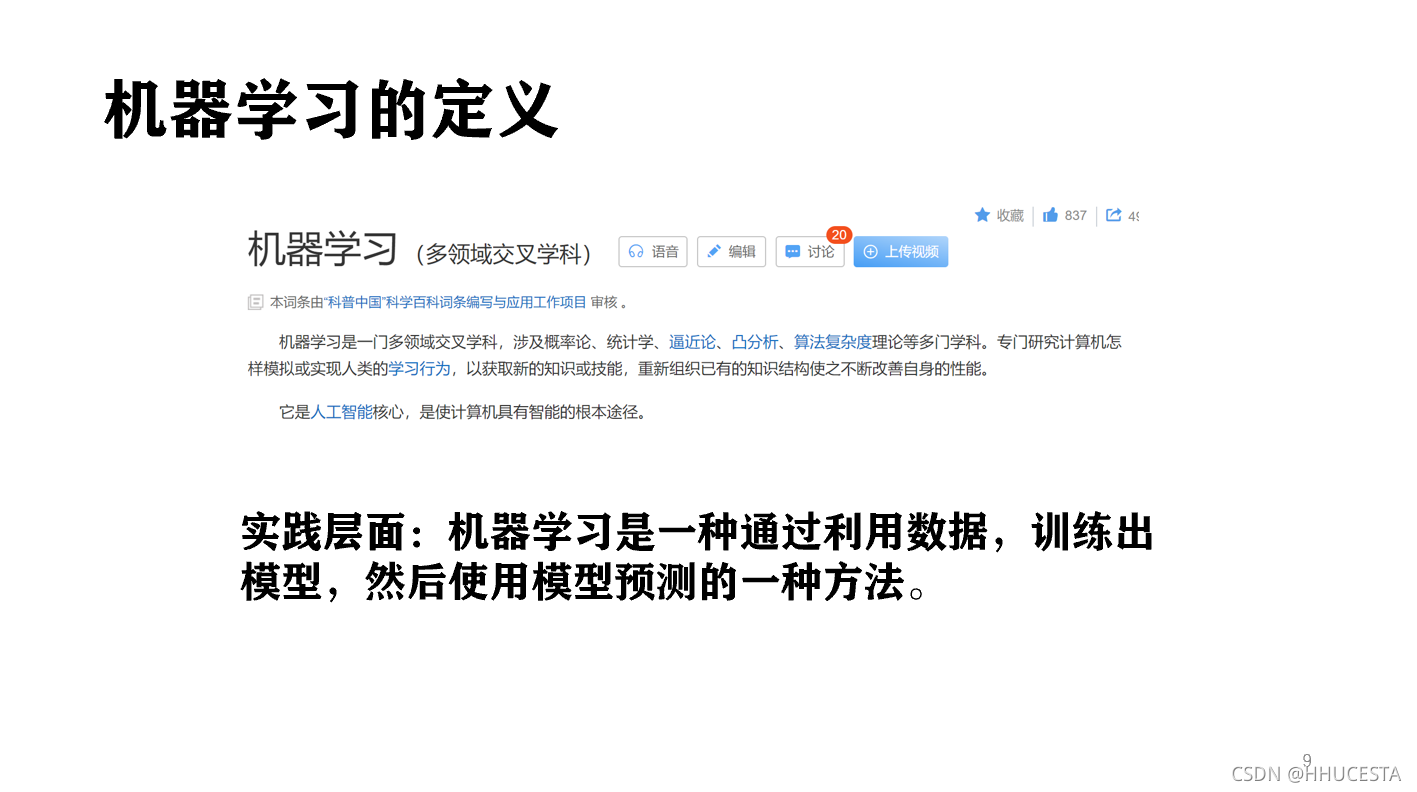
那么机器学习的定义究竟是什么呢?下面给出了百度定义
实践层面:机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
我们再来看一个例子,假如说现在我手里有一栋房子需要售卖,我应该给它标上多大的价格?房子的面积是100平方米,价格是100万,120万,还是140万?
很显然,我希望获得房价与面积的某种规律。那么我该如何获得这个规律?用报纸上的房价平均数据么?还是参考别人面积相似的?无论哪种,似乎都并不是太靠谱。
我现在希望获得一个合理的,并且能够最大程度的反映面积与房价关系的规律。于是我调查了周边与我房型类似的一些房子,获得一组数据。这组数据中包含了大大小小房子的面积与价格,如果我能从这组数据中找出面积与价格的规律,那么我就可以得出房子的价格。
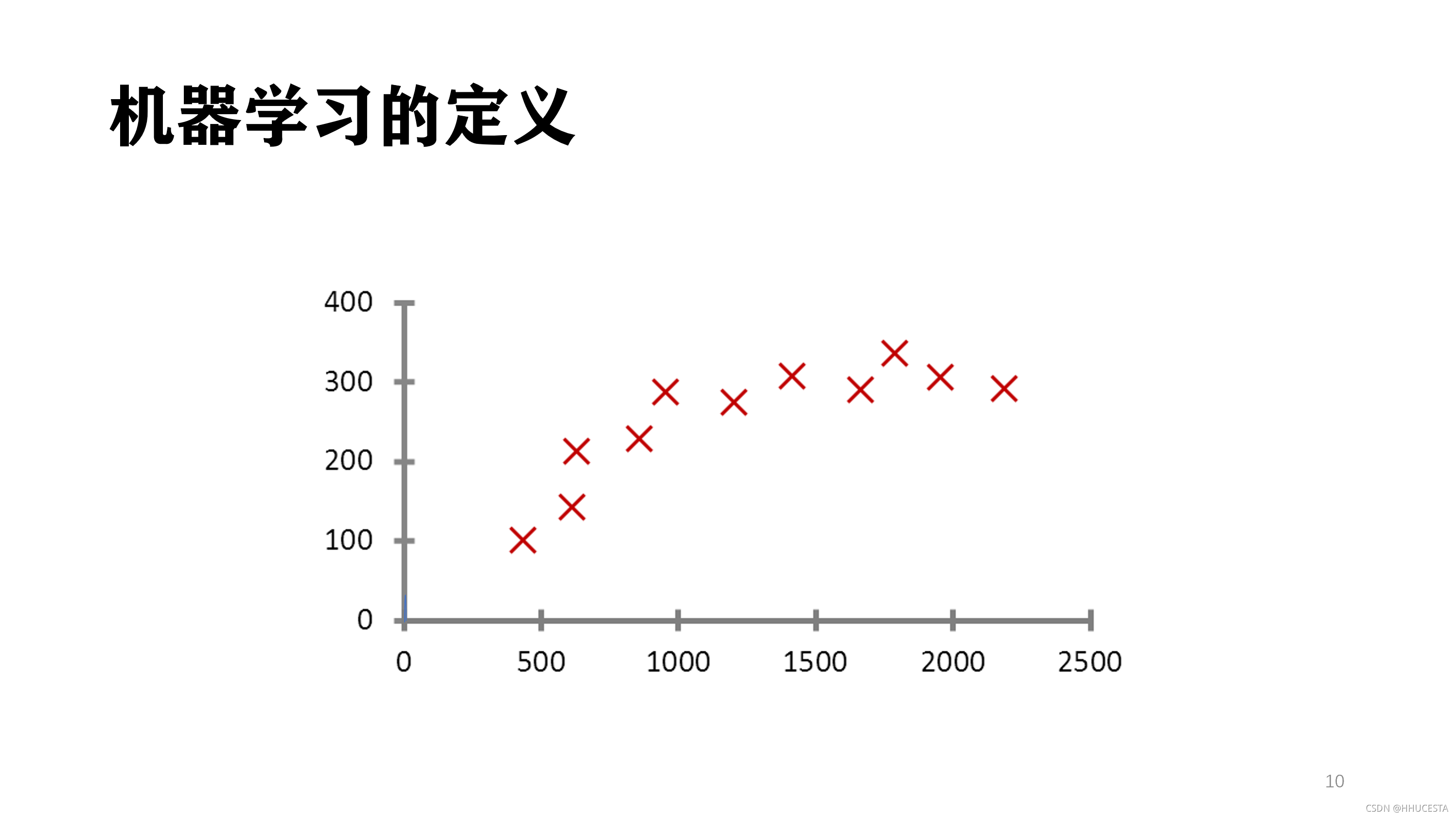
对规律的寻找很简单,拟合出一条直线,让它“穿过”所有的点,并且与各个点的距离尽可能的小。
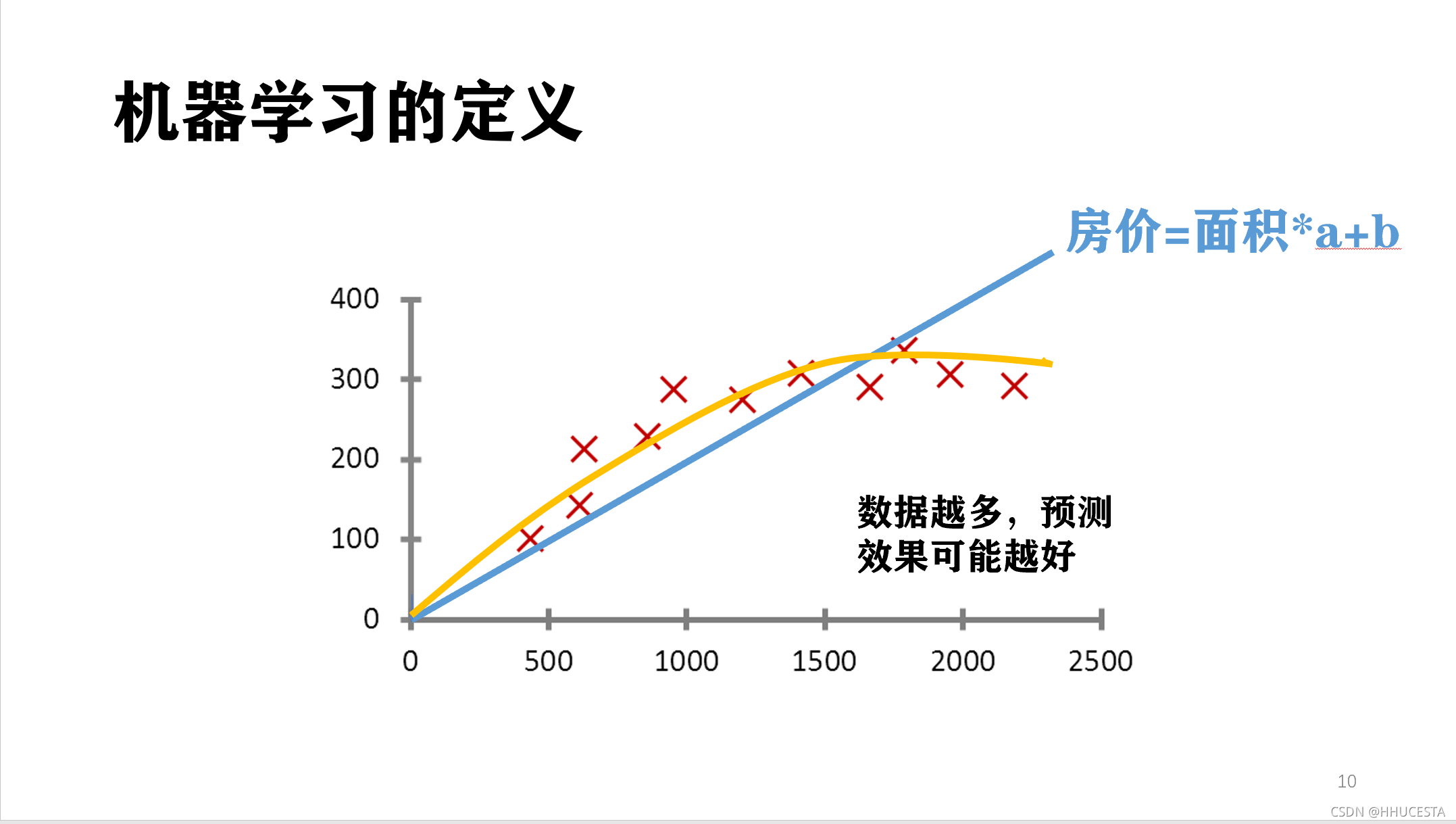
通过这条直线,我获得了一个能够最佳反映房价与面积规律的规律。比如下图中这条直线。
当然我们也可以用抛物线来拟合,在本情况中拟合程度肯定是比直线好的。
机器学习中有一些强力算法可以拟合出复杂的非线性模型,用来反映一些不是直线所能表达的情况。
我们还可以知道的是如果我的数据越多,我的模型就越能够考虑到越多的情况,由此对于新情况的预测效果可能就越好。这是机器学习界“数据为王”思想的一个体现。一般来说(不是绝对),数据越多,最后机器学习生成的模型预测的效果越好。这个其实好理解,你比如这个图中如果就两个点,两点一连,就完事了。可是这样的模型根本不靠谱。
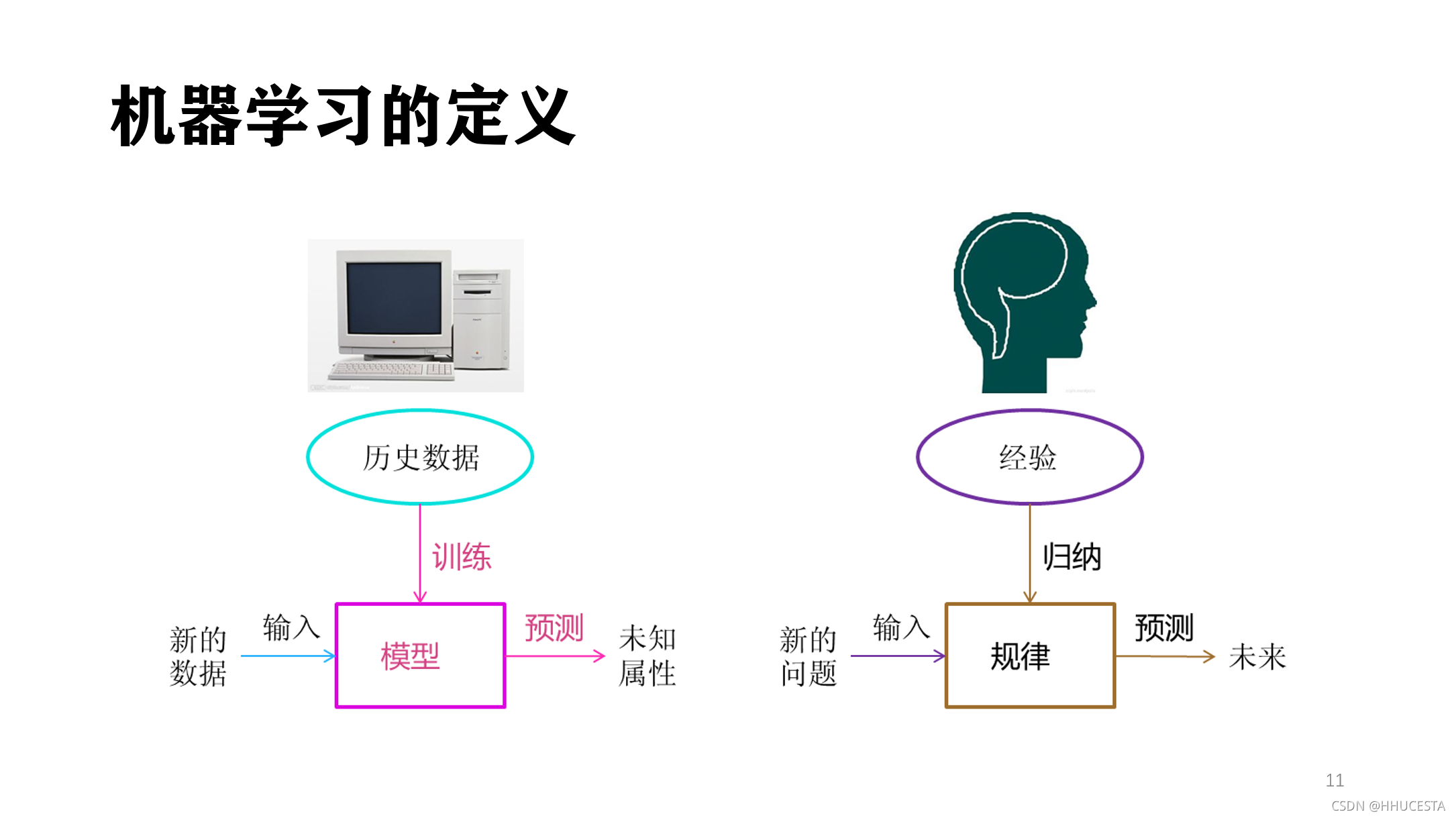
通过我拟合直线的过程,我们可以对机器学习过程做一个完整的回顾。首先,我们需要在计算机中存储历史的数据。接着,我们将这些 数据通过机器学习算法进行处理,这个过程在机器学习中叫做“训练”,处理的结果可以被我们用来对新的数据进行预测,这个结果一般称之为“模型”。对新数据 的预测过程在机器学习中叫做“预测”。“训练”与“预测”是机器学习的两个过程,“模型”则是过程的中间输出结果,“训练”产生“模型”,“模型”指导 “预测”。让我们把机器学习的过程与人类对历史经验归纳的过程做个比对。人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。
机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
三、机器学习在一些领域中的应用

1.机器视觉

计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。特别是随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果。
2、语音识别

语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
3、自然语言处理

自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。这个领域呢目前是没有计算机视觉发展的成熟的,成长空间还是非常大的。
4.小结
可以看出机器学习在众多领域的外延和应用。机器学习技术的发展促使了很多智能领域的进步,改善着我们的生活。那么我也很期待未来什么时候人工智能能由弱智能真正走向强智能,机器人或许能和我们面对面的交谈,但面对面的交谈需要的基础是机器能够视听说。那么怎么让电脑或者机器人学会视听说,就是我们机器学习努力的一个方向。
四、机器学习的方法
机器学习的方法即机器用来学习它自己的算法的方法,是机器学习的基础之一。
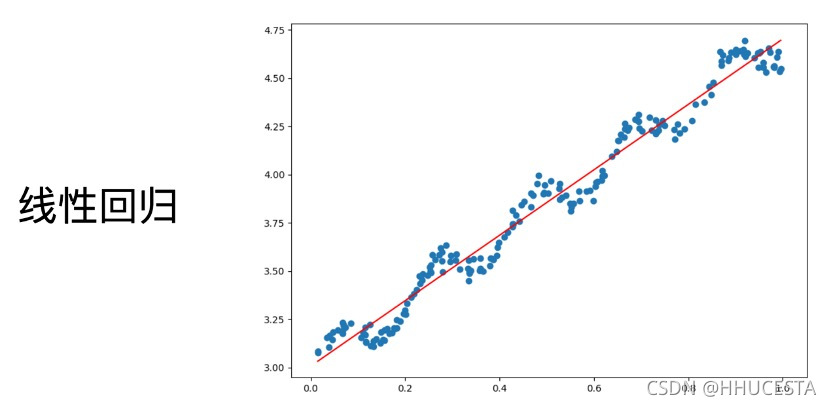
回归算法
回归算法比较简单,但十分重要,它是许多更强大算法的基石。
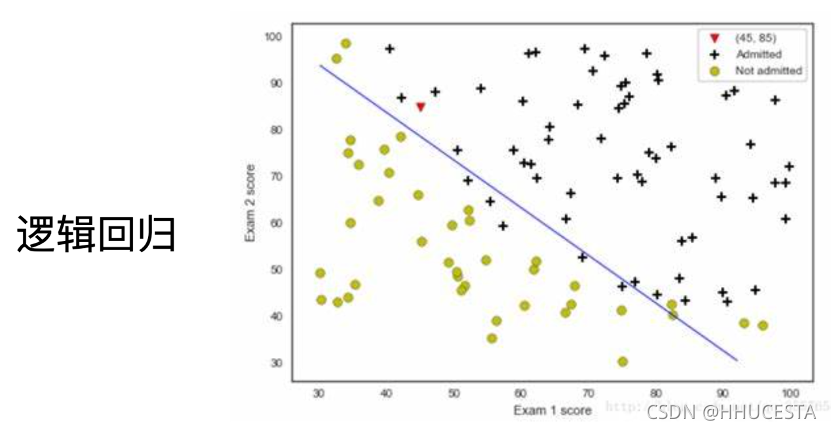
决策树
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
决策树是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
简单的例子:
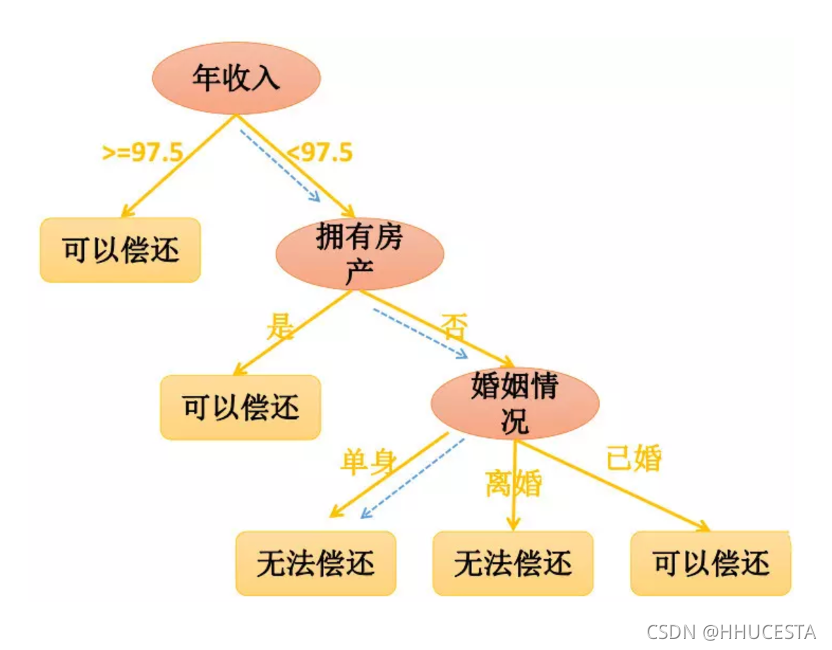
神经网络
人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
支持向量机
支持向量机可以看作是逻辑回归的强化版,它使超平面距离要分类的点尽可能远。
特点是数学理论成熟,求解快。
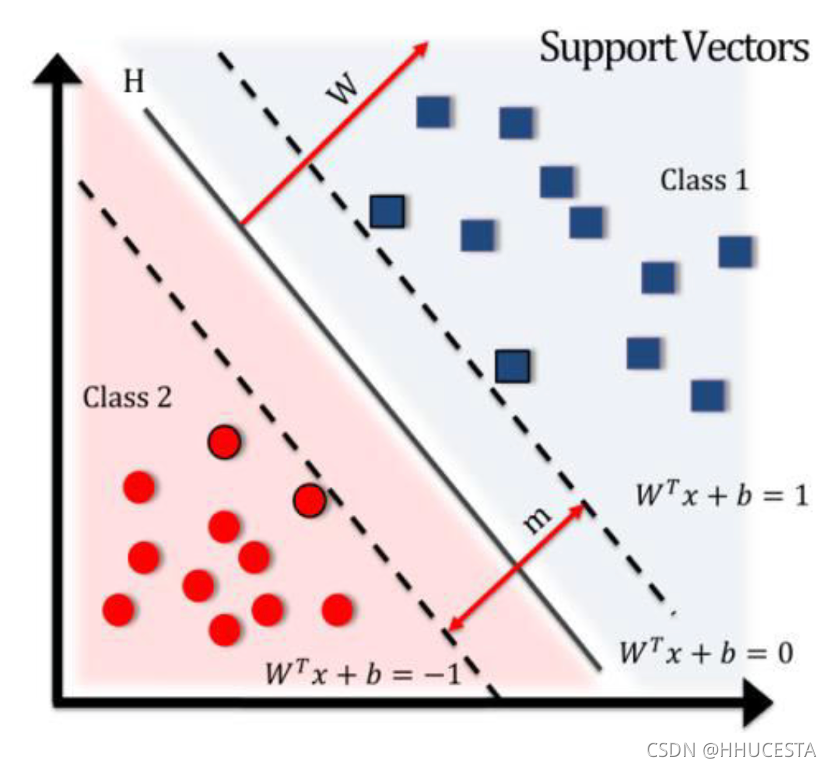
加上核方法,可以表达出非常复杂的分界线。
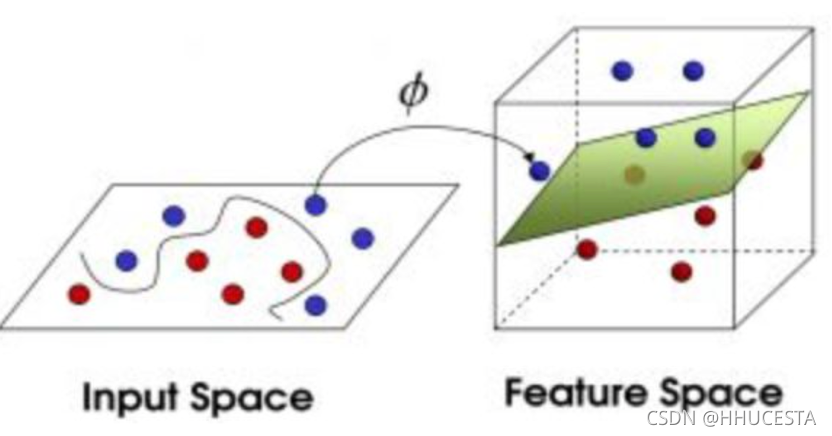
例子:
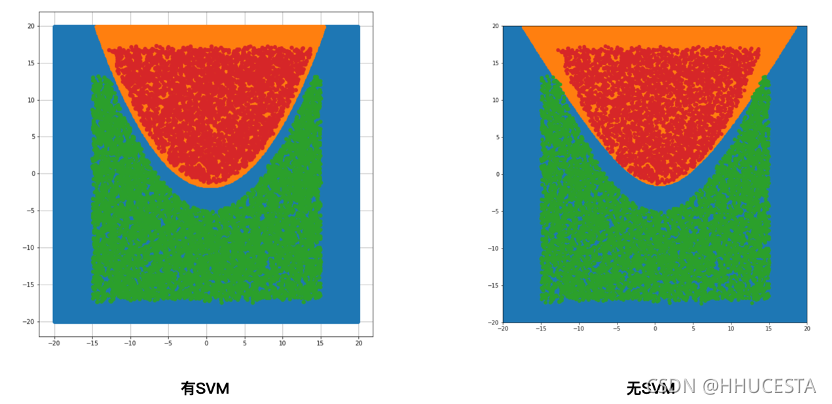
左边为支持向量机,右边为普通的逻辑回归。显然有SVM的效果更加好。
聚类算法、降维算法
聚类算法算法中的一个显著特征就是我的训练数据中包含了标签,训练出的模型可以对其他未知数据预测标签。
降维算法也是一种无监督学习算法,其主要特征是将数据从高维降低到低维层次。
五、机器学习的应用
下棋、语言识别、自动驾驶、翻译等(大大提高了我们的生活质量)

深度学习——机器学习的子类
深度学习(DL, Deep Learning)是机器学习(Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。
特点:深 神经网络 参数多
常见的网络:
CNN:多用于图像处理
RNN:多用于处理序列数据
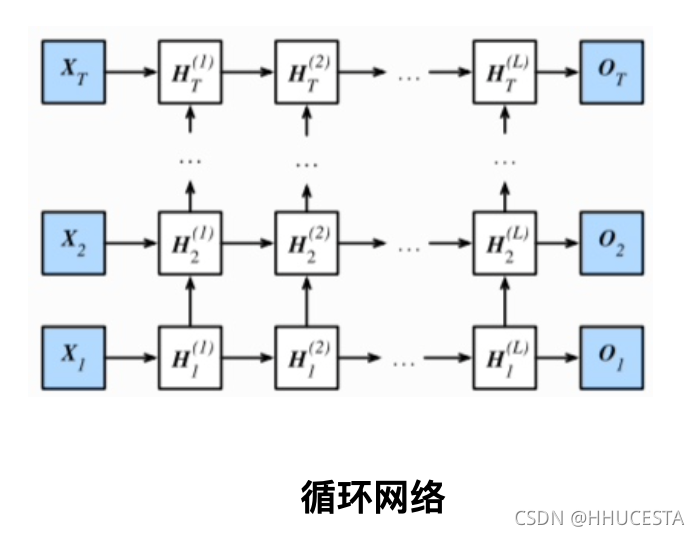
人工智能——机器学习的父类
人工智能是一门极富挑战性的科学,从事这项工作的人必须懂得计算机知识,心理学和哲学。人工智能是包括十分广泛的科学,它由不同的领域组成,如机器学习,计算机视觉等等,总的说来,人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作。但不同的时代、不同的人对这种“复杂工作”的理解是不同的。