这算是一个整合性得文章,主要记录下深度学习模型部署情况。
目前部署推理得框架较多,如opencv、tensorrt、openvino、onnxruntime、darknet,paddlepaddle、libtorch 用到的最多的应该是trt和openvino,接下来进行一一部署。
1、opencv
opencv作为一个开源的视觉库,想必大家都十分得了解了,再次不进行过多的解释,opencv部署深度学习框架主要是有dnn模块完成。
其中opencv部署也分cpu和gpu区别,其中GPU部署需要进行cmake编译,
接下来我们使用yolov3进行cpu部署:
cpu的部署723ms,这时间确实很长的了,gpu需要编译,选择gpu推理的时候将DNN_TARGET_CPU改为DNN_TARGET_CUDA即可 DNN_BACKEND_OPENCV改为DNN_BACKEND_CUDA
Net net = readNetFromDarknet(yolo_tiny_cfg, yolo_tiny_model);
net.setPreferableBackend(DNN_BACKEND_OPENCV);
net.setPreferableTarget(DNN_TARGET_CPU);
std::vector<String> outNames = net.getUnconnectedOutLayersNames();
for (int i = 0; i < outNames.size(); i++) {
printf("output layer name : %s\n", outNames[i].c_str());
}
opencv+cuda:卧槽了个DJ 。这么快的吗????这特么的比trt还快。。。。yolov4。。。。
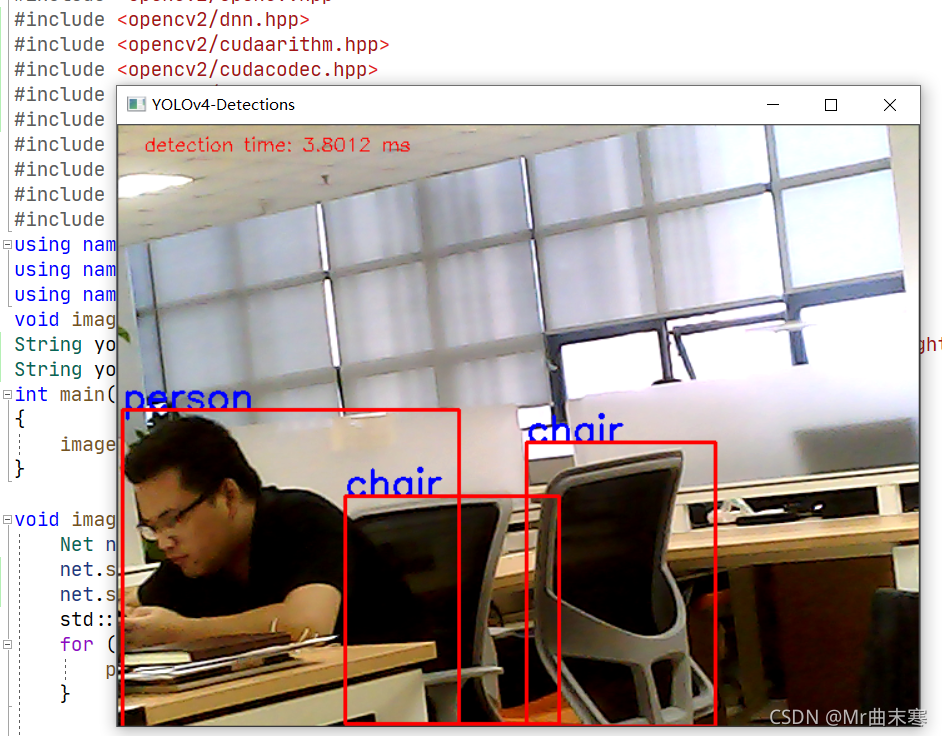
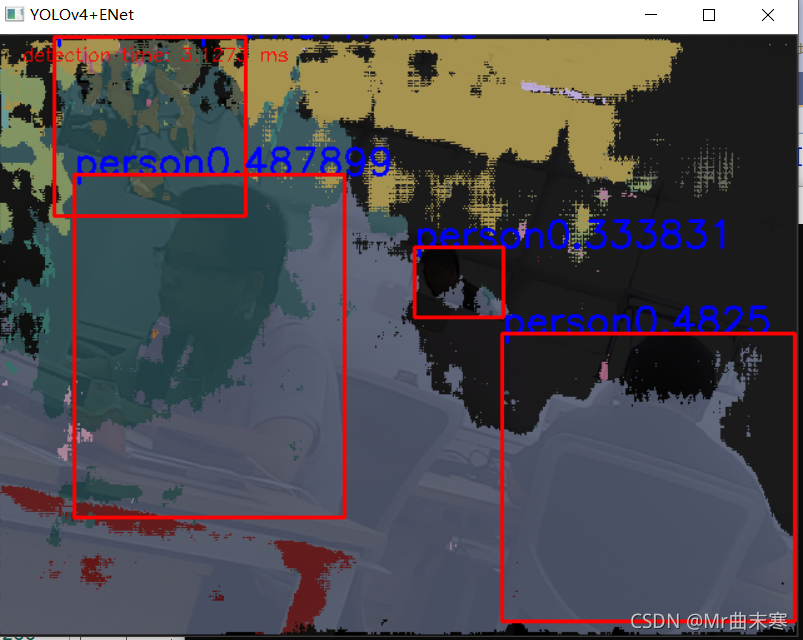
yolov4+enet分割网络:
yolov4作为目标检测网络,enet作为分割网络。(ennet是下载别人的。。。。。。)
添加了两个网络,,,,,,,检测还这么好?????
2、tensorrt
这个主要是针对GPU部署推理,速度极快,大概10ms一张图
TensorRT7.0+yolov5+win10+VS2019_zhangdaoliang1的博客-CSDN博客
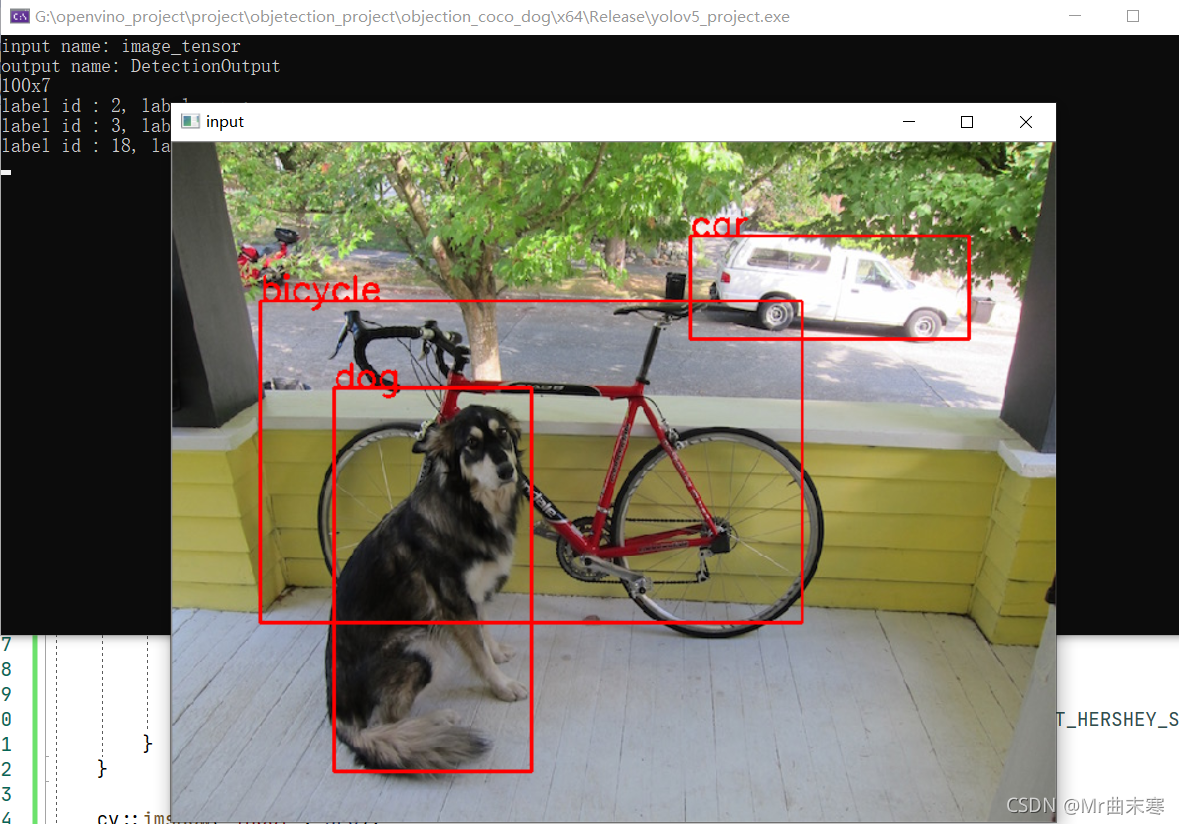
3、openvino
intel针对自家的cpu加速推理的框架,大家要是没有gpu,只能在cpu上部署的,建议采用openvino进行部署。
我使用的模型是fasterrcnn 大概500ms,fasterrcnn二阶段网络,这个时间确实有点长了,回头在试试v3吧
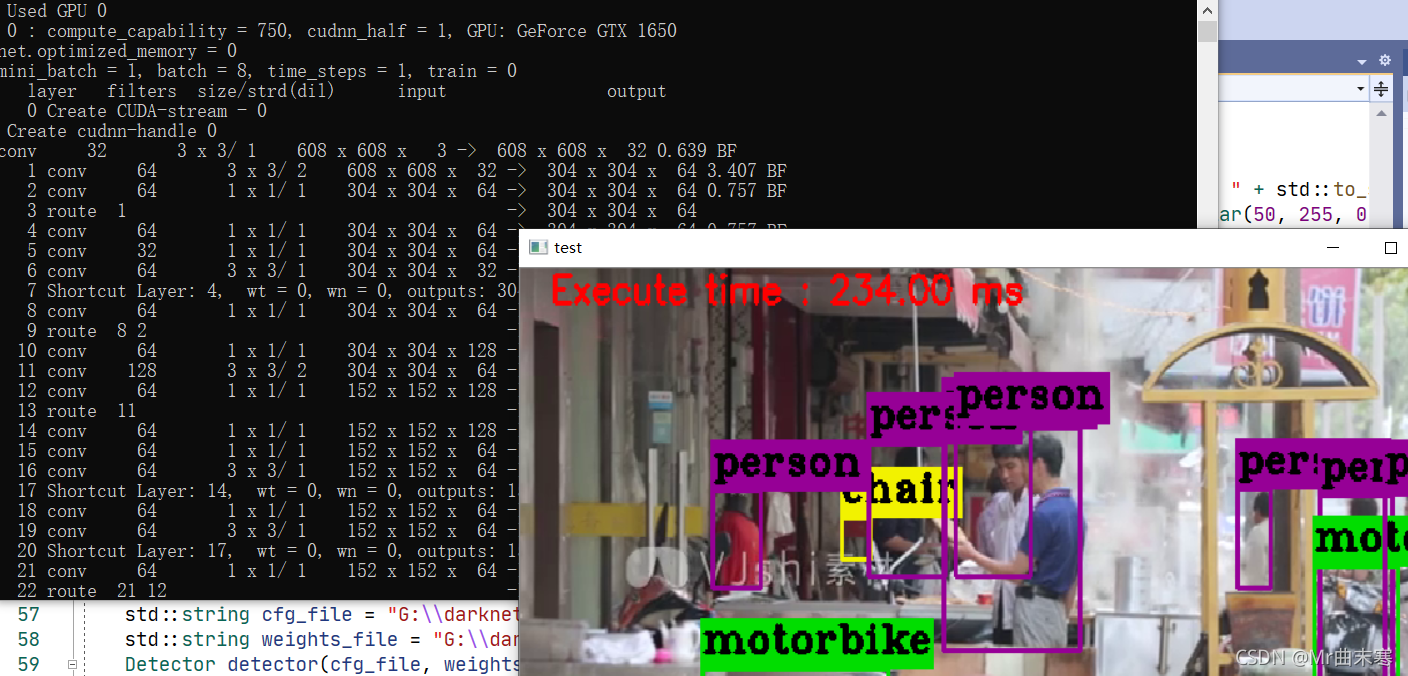
4、darknet
yolo系列的粉丝对darknet应该是非常熟悉的了,而且darknet也支持C++部署。
可以参考:
DarkNet+win10+编译dll+yolov3/yolov4_zhangdaoliang1的博客-CSDN博客
v3的速度大概是7帧每秒,但是确实使用了gpu加速,但是gpu的使用率并不高。

5、paddlepaddle
paddle是百度推出来,基于训练+部署一条龙服务,主要的好处在于文档比较详细,有问题直接与开发人员反应,而飞桨的部署也是基于飞桨自己的模型。之前也搞过很多飞桨的部署,详细的话可以看看我其他的博客。
基于paddlex训练的v3,编译的gpu版本,时间大概90ms,之前用官方的测试是30ms左右,不过我这个是没有进行裁剪与量化的,(计算的时间其实是将画线的时间都算进去了),paddle的部署基本上都是基于C#的 ,对于喜欢用C#做界面的小伙伴可以去尝试下飞桨的部署。
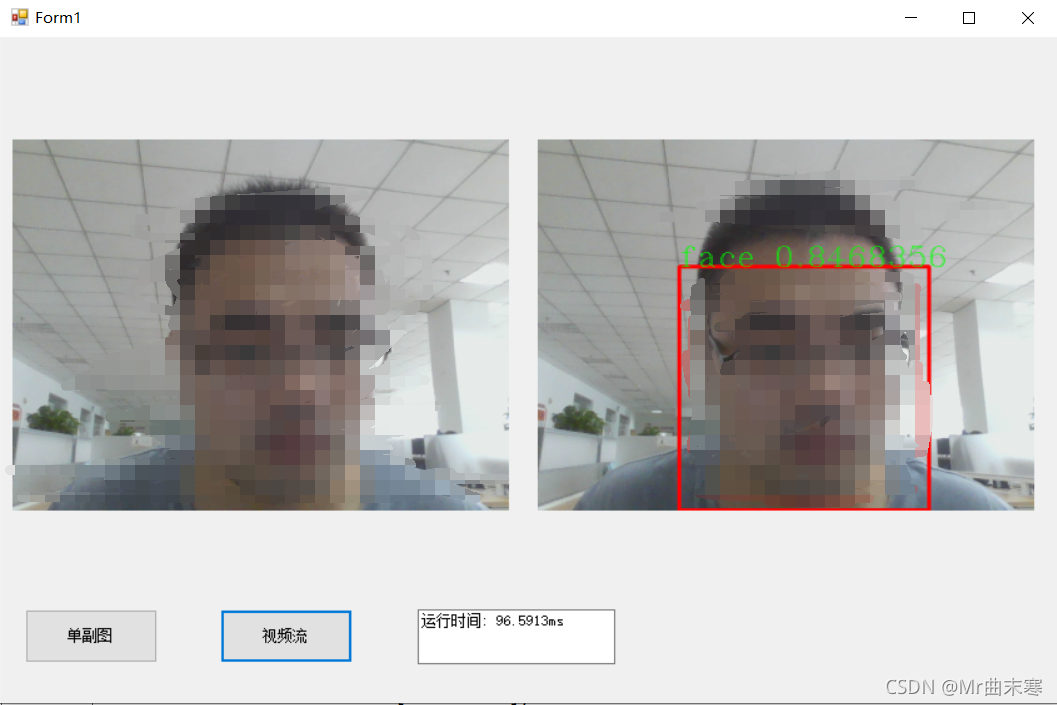
6、onnxruntime
这个框架 我接触的应该是最少的了,几乎没有用过,搞过最多的就是转.onnx格式,,最近用的一次是yolox的onnxruntime推理。

7、libtorch
libtorch是C++版本的pytorch,去官网下载对应的版本的libtorch
不过说实话 这精度下降的确实有些明显。。。。。。

总结:
GPU下的部署那肯定是优先trt的部署,速度很快,
CPU下的部署优先openvino,
喜欢C#的可以考虑下飞桨的部署。