学习自《自己动手写Docker》
京东购买链接:https://item.jd.com/10033552355433.html
其他链接:
- https://learnku.com/articles/42072
- https://stackoverflow.com/questions/28348627/echo-tasks-gives-no-space-left-on-device-when-trying-to-use-cpuset
- https://www.cnblogs.com/charlieroro/p/10281469.html
第一节了解了基础知识,下面开始实战
文章目录
一、构造实现run命令版本的容器引擎
本节代码获取方式:
git clone https://github.com/xwjahahahaha/myDocker.git
1.1 Linux proc文件系统
开始之前,还是再补充一点基本知识。/proc文件系统是由内核提供的,不是一个真正的文件系统,它只包含了系统运行时的信息(系统内存、mount设备信息、一些硬件配置等)。它只存在于内存中而不占用系统的外存空间。**它以文件系统的形式为访问内核数据的操作提供借接口。**实际上很多工具都是简单的去读取这个文件系统中的文件内容。
遍历/proc目录:
$ ls /proc/
1 15 215 28 4 529 728 89 crypto irq meminfo slabinfo version_signature
10 15445 22 2812 485 546 729 9 devices kallsyms misc softirqs vmallocinfo
11 16 23 2856 486 550 7668 916 diskstats kcore modules stat vmstat
115 164 23064 29 489 575 78 921 dma keys mounts swaps zoneinfo
11638 17 24 2962 490 6 79 98 driver key-users mtrr sys
12 18 249 2995 491 617 799 acpi execdomains kmsg net sysrq-trigger
1230 184 25 30 495 678 8 buddyinfo fb kpagecgroup pagetypeinfo sysvipc
13 185 25393 31836 497 679 80 bus filesystems kpagecount partitions thread-self
13253 19 255 34 498 680 81 cgroups fs kpageflags sched_debug timer_list
1343 2 26 35 499 688 82 cmdline interrupts loadavg schedstat tty
1344 20 2680 36 500 7 83 consoles iomem locks scsi uptime
14 21 27 399 501 707 8565 cpuinfo ioports mdstat self versio
这些数字都是为每个进程创建的空间,数字就是他们的PID
对于一个进程N比较重要的部分文件解释:

1.2 实现Run命令
首先实现一个简单版本的run命令,类似于docker run -it [command]。后面会逐步添加network、mount filesystem等功能。该版本参考书中的版本实现,但是使用了go mod模式,并对一些工具包的选择做了替换
1. 非linux系统goland的配置
在实现之前,需要对编译器goland进行一些配置,否则syscall会报错:
因为在不同的环境中,go 导入的文件也是不同,如果我们的环境使用的 Windows,那么使用 os/exec 包时,导入的将是 exec_windows.go,而如果我们的环境是 Linux,那么将会导入 exec_linux.go 文件,因为只有 Linux 才会给创建进程时提供这个隔离参数,所以我们需要把环境改成 Linux。
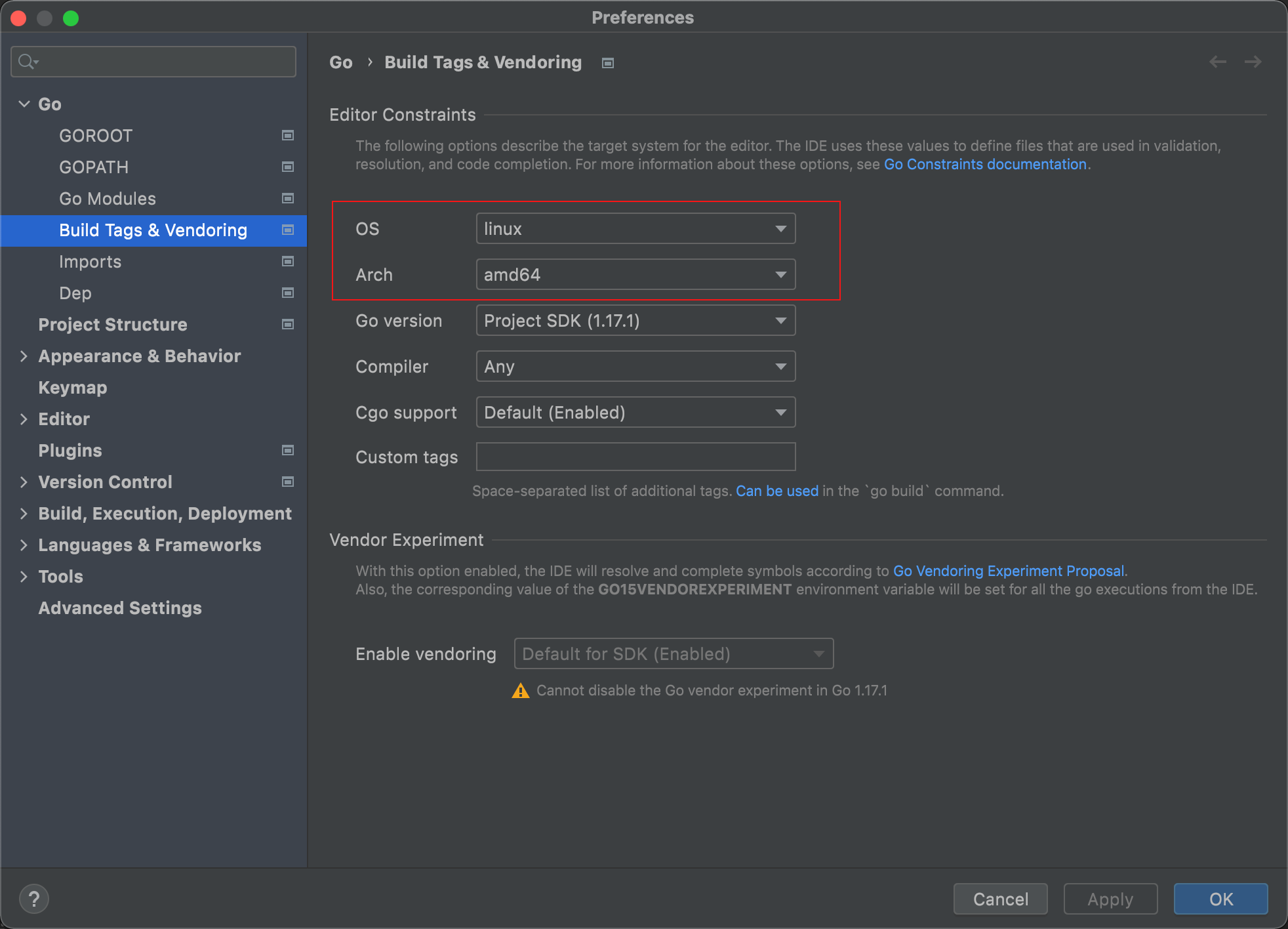
在非linux环境下编译也需要交叉编译,在go build之前设置这样两个参数即可:
GOOS=linux GOARCH=amd64 go build ./
然后上传到linux上运行
2. Run-version1
本版本代码切换:
$ git clone https://github.com/xwjahahahaha/myDocker.git
$ git checkout 1e545
1. 实现
代码目录结构:
.
├── README.md
├── cmd
│ ├── commands.go
│ ├── init.go
│ └── root.go
├── container
│ ├── initContainer.go
│ └── run.go
├── go.mod
├── go.sum
├── log
│ ├── init.go
│ └── log.go
├── main.go
入口main文件:
书本中使用的是github.com/urfave/cli实现的命令行,我采用cobra实现,所以在main中只需要执行我们的根命令即可:
package main
import "xwj/mydocker/cmd"
func main() {
cmd.Execute()
}
命令行cmd文件夹下,我们需要实现的两个命令init和run都在commands.go下:
package cmd
import (
"github.com/spf13/cobra"
"xwj/mydocker/container"
)
const (
initUsage = `Init container process run user's process in container.Do not call it outside.`
runUsage = `Create a container with namespace and cgroups limit: myDocker run -t [command]`
)
var (
tty bool // 是否交互式执行
)
var initDocker = &cobra.Command{
Use: "init [command]",
Short: initUsage,
Long: initUsage,
Args: cobra.ExactArgs(1),
RunE: func(cmd *cobra.Command, args []string) error {
// 获取传递的command参数,执行容器的初始化操作
return container.RunContainerInitProcess(args[0], nil)
},
}
var runDocker = &cobra.Command{
Use: "run [command]",
Short: runUsage,
Long: runUsage,
Args: cobra.ExactArgs(1),
Run: func(cmd *cobra.Command, args []string) {
// 获取交互flag值与command, 启动容器
container.Run(tty, args[0])
},
}
先看run命令,其核心就是container.Run函数,该函数在container包下的run.go,具体的解释与代码如下:
// NewParentProcess
// @Description: 创建新的命令进程(并未执行)
// @param tty
// @param command
// @return *exec.Cmd
func NewParentProcess(tty bool, command string) *exec.Cmd {
// 调用init初始化一些进程的环境和资源
args := []string{
"init", command}
// 设置/proc/self/exe的命令就是调用自己
cmd := exec.Command("/proc/self/exe", args...)
// 使用Clone参数设置隔离环境
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
// 如果设置了交互,就把输出都导入到标准输入输出中
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
return cmd
}
// Run
// @Description: 执行命令
// @param tty
// @param cmd
func Run(tty bool, cmd string){
parent := NewParentProcess(tty, cmd)
// 执行命令但是并不等待其结束
// 执行后会clone出一个namespace隔离的进程,然后在子进程中调用/proc/self/exe即自己,
// 发送init参数调用init方法初始化一些资源
if err := parent.Start(); err != nil {
log.Log.Error(err)
}
// 等待结束
if err := parent.Wait(); err != nil {
log.Log.Error(err)
}
os.Exit(1)
}
我们在命令中的第一个参数就是init,即克隆了一个子进程调用了自己,使用init命令初始化一些资源,那么init命令的container.RunContainerInitProcess是怎么实现的呢?在container包下initContainer:
// RunContainerInitProcess
// @Description: 容器内部执行的函数
// @param cmd
// @param args
// @return error
func RunContainerInitProcess(cmd string, args []string) error {
log.Log.Infof("command %s", cmd)
// 首先设置/proc为私有模式,防止影响外部/proc
if err := syscall.Mount("", "/proc", "proc", syscall.MS_REC | syscall.MS_PRIVATE, ""); err != nil {
log.Log.WithField("method", "syscall.Mount").Error(err)
return err
}
// 挂载/proc文件系统
// 设置挂载点的flag
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
if err := syscall.Mount("", "/proc", "proc", uintptr(defaultMountFlags), ""); err != nil {
log.Log.WithField("method", "syscall.Mount").Error(err)
return err
}
argsv := []string{
cmd}
if err := syscall.Exec(cmd, argsv, os.Environ()); err != nil {
log.Log.WithField("method", "syscall.Exec").Error(err)
return err
}
return nil
}
我们初始化一个隔离进程的资源,需要使用mount挂载/proc,但是在之前的基础知识中我们了解到挂载/proc默认都是共享模式,因为mount的传播机制子进程的挂载会导致父进程/proc的失效,所以我们需要设置给mount设置一些默认的flag, 其解释如下:
(注:如果想查看所有的flag,可查看mount手册)
syscall.MS_NOEXEC:不允许从这个文件系统执行程序。syscall.MS_NOSUID:当从这个文件系统执行程序时,不可使用set-user-ID和set-group-IDsyscall.MS_NODEV:不允许访问该文件系统上的设备(特殊文件)syscall.MS_REC:对于所有子文件递归的绑定挂载syscall.MS_PRIVATE:将这个挂载的文件设置为私有模式,不会影响外部
其中syscall.MS_REC 与syscall.MS_PRIVATE的结合使用就是实现了类似于之前在容器内部mount --make-rprivate mountpoint的指令。这里还需要注意的一点是,必须分两步来执行Mount,即先设置私有模式然后再挂载/proc,如果将所有flag集中到一个Mount执行会报错:Invalid argument
这段程序中还有一个注意点/重点是:syscall.Exec
正是这个系统调用实现了完成初始化动作并将用户进程运行起来的操作(参数cmd就是用户分配的容器中的第一个执行命令)。我们知道,在run命令下复制了一个隔离的进程,并且调用了自身执行init命令,这个进程的PID为1,但是这个进程并不是用户进程。在之前也说过,容器启动起来的第一个进程不是用户进程,因为init进程的PID为1,不能直接kill否则容器就会直接退出,所以我们需要把init这个PID为1的进程进行覆盖
syscall.Exec这个系统调用方法实质上调用的是内核中的int execve(const char *filename, char *const argv[], char *const envp[])这个系统函数,它的作用是**执行当前filename对应的程序,它会覆盖当前进程的镜像、数据、堆栈、PID等信息。**所以,通过这个命令可以将用户的进程命令执行起来并将init进程覆盖掉,这样到容器内部就会发现第一个程序就是我们制定的进程了。
2. 工作流程
总体的工作流程如下:
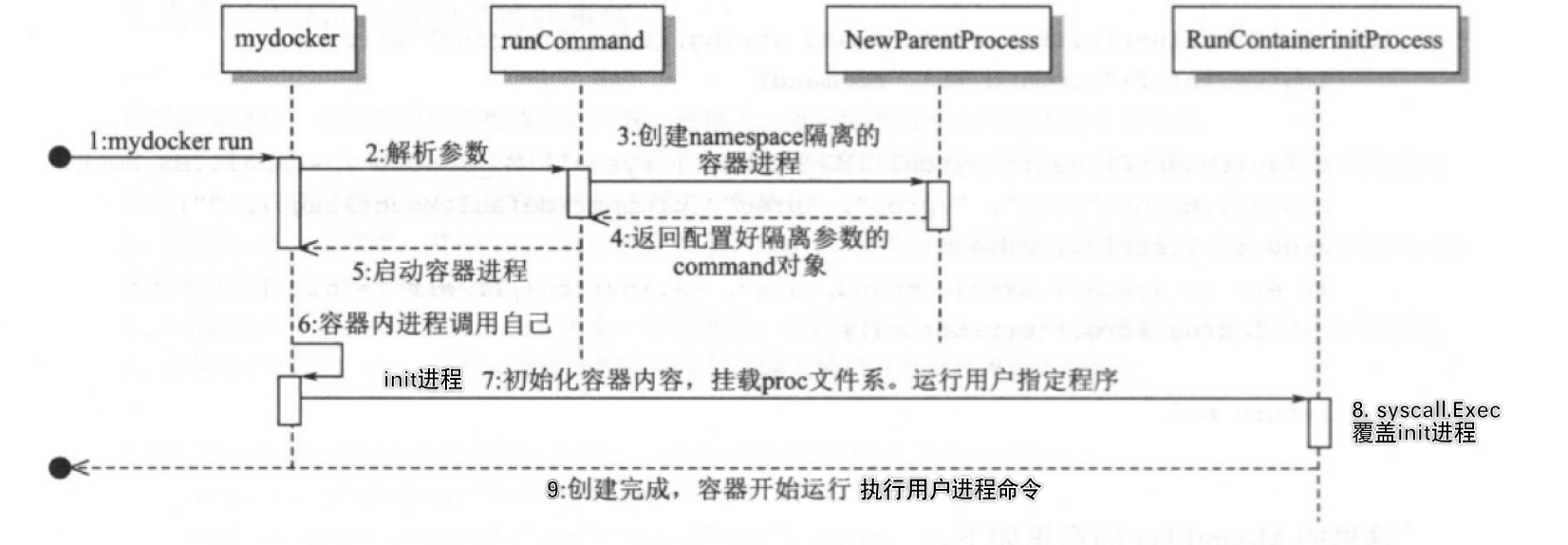
3. 测试
# 如果本身就是linux就直接编译
$ GOOS=linux GOARCH=amd64 go build ./
# 将编译好的可执行文件上传到linux上执行:
$ ./mydocker run -t /bin/sh
# 进入容器后,查看进程
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:02 pts/1 00:00:00 /bin/sh
root 5 1 0 11:02 pts/1 00:00:00 ps -ef
# 退出容器,查看宿主机的/proc是否收到影响
$ exit
$ ls /proc
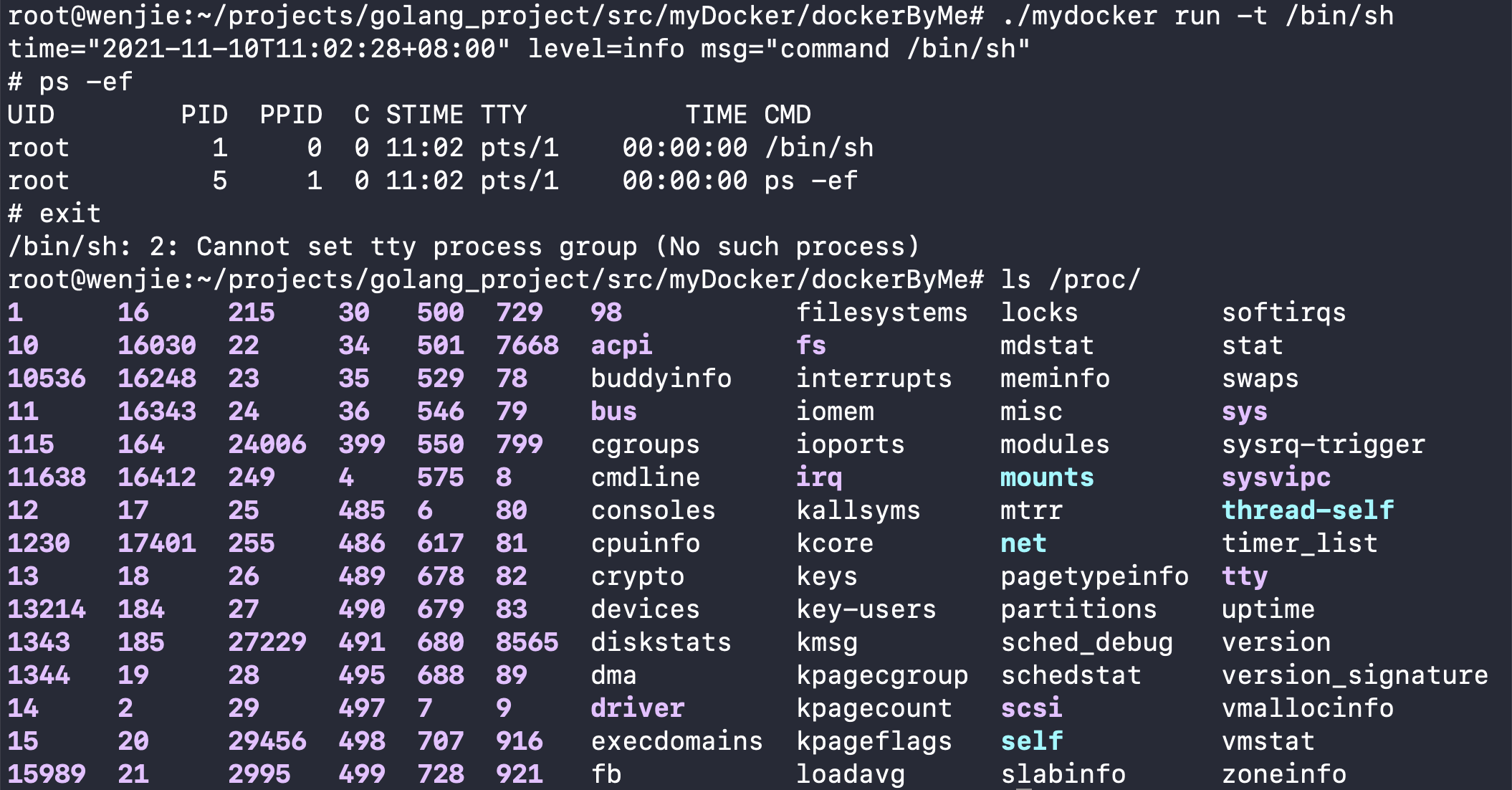
可以发现进程为1的进程运行的命令是/bin/sh , 实现了我们的需求。并且宿主机的/proc并没有受到影响。
可以尝试将初始命令设置为运行后结束的命令: mydocker run -t /bin/ls
$ ./mydocker run -t /bin/ls
time="2021-11-10T11:10:15+08:00" level=info msg="command /bin/ls"
mydocker
可以看到输出的就是当前宿主机的目录信息,因为我们没有设置chroot,所以目前的文件系统还是继承自父进程的.
3. Run-version2
在第二个版本,我们将利用cgroup加入资源限制,实现./mydocker run -t -m 100m --cpu-mems 0 --cpu-set 0 --cpu-shares 2048 /bin/sh实现容器启动时的资源限制条件。
本版本代码切换:
$ git clone https://github.com/xwjahahahaha/myDocker.git
$ git checkout c25e7
1. 实现
项目结构:
├── README.md
├── cgropus
│ ├── cgroup_manager.go
│ └── subsystems
│ ├── cpu.go
│ ├── cpuset.go
│ ├── memory.go
│ ├── subsystem.go
│ └── utils.go
├── cmd
│ ├── commands.go
│ ├── init.go
│ └── root.go
├── container
│ ├── initContainer.go
│ └── run.go
├── go.mod
├── go.sum
├── log
│ ├── init.go
│ └── log.go
├── main.go
其中与版本相比新增的文件就是cgroups文件夹,对于该文件的各个文件的解释如下:
├── cgropus
│ ├── cgroup_manager.go # 对新建的cgroup进行统一的管理
│ └── subsystems # 子系统
│ ├── cpu.go # cpu子系统的操作
│ ├── cpuset.go # cpuset子系统的操作
│ ├── memory.go # 内存子系统的操作
│ ├── subsystem.go # 子系统接口
│ └── utils.go # 一些工具方法
在开始之前,需要复习一下cgroups的三个核心概念:
- cgroup:控制组,包含组所有进程以及对应子系统限制关系。在系统中就表现为一个文件夹包含了众多的描述文件,
tasks文件制定组包含的所有进程,其他文件则是子系统的限制描述信息 - subsystem:子系统,对应于每一类系统资源的限制。例如系统中
/sys/fs/cgroup/目录下已经设置了很多子系统如cpu、内存等各类限制。(本节就在该目录下创建新的cgroup文件夹) - hierarchy:层级树,是控制组继承限制的树形结构。在系统文件中的表现就是父子目录的关系,联系着各个控制组。
在cgroups/subsystem.go文件中创建资源配置结构体与各个子系统的通用接口
package subsystems
import "strings"
type ResourceConfig struct {
MemoryLimit string // 内存限制
CpuShare string // CPU时间片权重
CpuSet string // CPU核心数
CpuMems string // CPU Node内存
}
// Subsystem 子系统统一接口,每个子系统都实现如下四个方法
// 这里cgroup抽象成为了path,因为cgroup在层级树的路径就是虚拟文件系统的路径
type Subsystem interface {
Name() string // 返回子系统的名字
Set(string, *ResourceConfig) error // 设置某个cgroup在这个子系统中的资源限制(设置子系统限制文件的内容)
Apply(string, int) error // 将进程添加到某个cgroup中
Remove(string) error // 移除某个cgroup
}
var (
// SubsystemsIns 通过不同的子系统初始化实例创建资源限制的处理链数组
SubsystemsIns = []Subsystem{
&CpuSetSubSystem{
},
&MemorySubSystem{
},
&CpuSubSystem{
},
}
)
func (r *ResourceConfig) String() string {
var line []string
line = append(line, "MemoryLimit:", r.MemoryLimit)
line = append(line, "CpuShare:", r.CpuShare)
line = append(line, "CpuSet:", r.CpuSet)
return strings.Join(line, " ")
}
因为memory、cpu、cpuset三个子系统都是类似的实现上面接口的方法,所以只以memory.go来描述,其他类似不在放代码(可以在github上clone的代码中查看)。
package subsystems
import (
"github.com/sirupsen/logrus"
"io/ioutil"
"os"
"path"
"strconv"
"xwj/mydocker/log"
)
const (
MemLimitFileName = "memory.limit_in_bytes"
TaskFileName = "tasks"
)
var memoryLogger = log.Log.WithFields(logrus.Fields{
"subsystem" : "memory",
})
type MemorySubSystem struct {
}
func (m *MemorySubSystem) Name() string {
return "memory"
}
func (m *MemorySubSystem) Set(cgroupPath string, res *ResourceConfig) error {
// GetCgroupPath获取当前子系统在虚拟文件系统中的路径
subsysCgroupPath, err := GetCgroupPath(m.Name(), cgroupPath, true)
if err != nil {
memoryLogger.WithFields(logrus.Fields{
"method" : "Set",
"errFrom" : "GetCgroupPath",
}).Error(err)
return err
}
// 设置这个cgrouop的内存限制,将内存限制写入cgroup对应目录的memory.limit_in_bytes文件中
if res.MemoryLimit != "" {
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, MemLimitFileName), []byte(res.MemoryLimit), 0644); err != nil {
memoryLogger.WithFields(logrus.Fields{
"method" : "Set",
"errFrom" : "WriteFile",
}).Error(err)
return err
}
}
return nil
}
func (m *MemorySubSystem) Apply(cgroupPath string, pid int) error {
subsysCgroupPath, err := GetCgroupPath(m.Name(), cgroupPath, false)
if err != nil {
memoryLogger.WithFields(logrus.Fields{
"method" : "Apply",
"errFrom" : "GetCgroupPath",
}).Error(err)
return err
}
// 将进程的PID写入cgroup的虚拟文件系统对应的目录下的"task"文件夹
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, TaskFileName), []byte(strconv.Itoa(pid)), 0644); err != nil {
memoryLogger.WithFields(logrus.Fields{
"method" : "Apply",
"errFrom" : "WriteFile",
}).Error(err)
return err
}
return nil
}
func (m *MemorySubSystem) Remove(cgroupPath string) error {
subsysCgroupPath, err := GetCgroupPath(m.Name(), cgroupPath, false)
if err != nil {
memoryLogger.WithFields(logrus.Fields{
"method" : "Remove",
"errFrom" : "GetCgroupPath",
}).Error(err)
return err
}
// 删除掉cgroup的目录就是对整个cgroup的删除
if err := os.RemoveAll(subsysCgroupPath); err != nil {
memoryLogger.WithFields(logrus.Fields{
"method" : "Remove",
"errFrom" : "os.Remove",
}).Error(err)
return err
}
return nil
}
其他两个对应的set的文件名为:
- cpu:
CpuShareLimitFileName = "cpu.shares" - cpuset:
CpuSetCpusLimitFileName = "cpuset.cpus"CpuSetMemsLimitFileName = "cpuset.mems"
对于cpuset与cpu的基本做一些解释:
cpu用于对cpu使用率的划分;cpuset用于设置cpu的亲和性等,主要用于numa架构的os;cpuacct记录了cpu的部分信息。对cpu资源的设置可以从2个维度考察:cpu使用百分比和cpu核数目。前者使用cpu subsystem进行配置,后者使用cpuset subsystem进程配置。
cpuset主要是为了NUMA(非均匀访问存储模型)使用的,NUMA技术将CPU划分成不同的组(Node),每个Node由多个CPU组成,并且有独立的本地内存、I/O等资源(硬件上保证)。可以使用numactl查看当前系统的node
$ numactl -H
available: 1 nodes (0)
node 0 cpus: 0
node 0 size: 1993 MB
node 0 free: 117 MB
node distances:
node 0
0: 10
在配置cpuset的时候一定要注意:需要先配置cpuset.mems即给cpu node分配内存,因为我的机器只有一个node即node 0,所以填写0即可,然后再配置其他例如cpuset.cpus,否则会报错:no space left on device
详细见:stackoverflow
对于cpu、cpuset等具体参数的意义可见文章: cpuset(7) CPU
其中**GetCgroupPath是获得当前cgroup在以/sys/fs/cgroup/对应子系统下的绝对路径**,而获得/sys/fs/cgroup/对应子系统,则需要从当前进程的/proc/self/mountinfo中筛选/扫描出来。
例如44 32 0:39 / /sys/fs/cgroup/memory rw,nosuid,nodev,noexec,relatime shared:22 - cgroup cgroup rw,memory这些输出都是按空格分割开,最后一个rw,memory是选项option, 其中最后一个就是指定了当前的子系统名称,而每一条分割的第五个/sys/fs/cgroup/memory就是完整的系统对应子系统的根目录.
需要注意的是,我的Linux中还包含/sys/fs/cgroup/cpu,cpuacct这样的文件夹,所以在代码中也进行了特殊的处理,不然后面的路径拼接会导致错误
以上两个函数都是在utils.go中实现的:
package subsystems
import (
"bufio"
"fmt"
"github.com/sirupsen/logrus"
"os"
"path"
"strings"
"xwj/mydocker/log"
)
// FindCgroupMountpoint
// @Description: 找到某个子系统的层级树中cgroup根节点所在的目录
// @param subsystem
// @return string
func FindCgroupMountpoint(subsystem string) string {
// 根据虚拟文件系统/proc查询当前进程挂载信息
f, err := os.Open("/proc/self/mountinfo")
if err != nil {
return ""
}
defer f.Close()
// 扫描目录
scanner := bufio.NewScanner(f)
for scanner.Scan() {
txt := scanner.Text()
fields := strings.Split(txt, " ") // 按空格分割
for _, opt := range strings.Split(fields[len(fields)-1], ",") {
// 如果选项中有当前子系统。则返回第五项(下标4)即系统创建的子系统路径
if opt == subsystem{
// 在一些系统中, /sys/fs/cgroup/cpu改为了/sys/fs/cgroup/cpu,cpuacct,所以做一个判断
if fields[4] == "/sys/fs/cgroup/cpu,cpuacct" {
return "/sys/fs/cgroup/cpu"
}
return fields[4]
}
}
}
if err := scanner.Err(); err != nil {
log.Log.WithFields(logrus.Fields{
"method" : "FindCgroupMountpoint",
"errFrom" : "WithFields",
}).Error(err)
return ""
}
return ""
}
// GetCgroupPath
// @Description: 获得当前子系统下的cgroup在系统层级树的绝对路径, 如果这个cgroup文件夹没有,可以设置自动创建
// @param subsystem
// @param cPath
// @param autoCreate
// @return string
// @return error
func GetCgroupPath(subsystem string, cPath string, autoCreate bool) (string, error) {
cgroupRoot := FindCgroupMountpoint(subsystem)
absolutePath := path.Join(cgroupRoot, cPath)
// 如果有这个cgroup绝对路径的文件目录 或者 没有这个目录但是设置了自动创建
if _, err := os.Stat(absolutePath); err == nil || (autoCreate && os.IsNotExist(err)) {
if os.IsNotExist(err) {
// 创建文件夹
if err := os.Mkdir(absolutePath, 0755); err != nil {
return "", fmt.Errorf("error create cgroup dir %v", err)
}
return absolutePath, nil
}
return absolutePath, nil
}else {
// 如果os.Stat是其他错误或者不存在cgroup目录但是也没有设置自动创建,则返回错误
return "", fmt.Errorf("cgroup path error %v", err)
}
}
最后,需要将这些不同的子系统使用cgroup管理起来,并与容器建立关系,cgroup_manager.go
package cgroups
import (
"github.com/sirupsen/logrus"
"xwj/mydocker/cgroups/subsystems"
"xwj/mydocker/log"
)
type CgroupManager struct {
Path string // cgroup在层级树中的路径,就是相对于系统层级树根cgroup目录的路径
Resource *subsystems.ResourceConfig // 资源配置
}
// NewCgroupManager
// @Description: 新建一个cgroup
// @param path
// @return *CgroupManager
func NewCgroupManager(path string) *CgroupManager {
return &CgroupManager{
Path: path,
}
}
// Apply
// @Description: 将当前进程放入各个子系统的cgroup中
// @receiver c
// @param pid
// @return error
func (c *CgroupManager) Apply(pid int) error {
var errFlag bool
for _, subSystemIns := range subsystems.SubsystemsIns {
if err := subSystemIns.Apply(c.Path, pid); err != nil {
log.Log.Errorf("process[%d] apply subsystem %s err.", pid, subSystemIns.Name())
errFlag = true
}
}
if !errFlag {
log.Log.WithFields(logrus.Fields{
"method" : "Apply",
}).Infof("success apply process[%d] into cgroups", pid)
}
return nil
}
// Set
// @Description: 设置子系统限制
// @receiver c
// @param res
// @return error
func (c *CgroupManager) Set(res *subsystems.ResourceConfig) error {
var errFlag bool
for _, subSystemIns := range subsystems.SubsystemsIns {
if err := subSystemIns.Set(c.Path, res); err != nil {
log.Log.Errorf("subsystem %s set limit err.", subSystemIns.Name())
errFlag = true
}
}
if !errFlag {
log.Log.WithFields(logrus.Fields{
"method" : "Set",
}).Infof("success set limits:[%s] into those subsystems", res)
}
return nil
}
// Destroy
// @Description: 销毁各个子系统中的cgroup
// @receiver c
// @return error
func (c *CgroupManager) Destroy() error {
var errFlag bool
for _, subSystemIns := range subsystems.SubsystemsIns {
if err := subSystemIns.Remove(c.Path); err != nil {
log.Log.Errorf("subsystem %s remove cgroup err.", subSystemIns.Name())
errFlag = true
}
}
if !errFlag {
log.Log.WithFields(logrus.Fields{
"method" : "Destroy",
}).Infof("success destroy cgroup %s files.", c.Path)
}
return nil
}
然后,我们添加一些flag,cmd/init.go
package cmd
func init() {
rootCmd.AddCommand(initDocker, runDocker)
runDocker.Flags().BoolVarP(&tty, "tty", "t", false, "enable tty")
runDocker.Flags().StringVarP(&ResourceLimitCfg.MemoryLimit, "memory-limit", "m", "200m", "memory limit")
runDocker.Flags().StringVarP(&ResourceLimitCfg.CpuShare, "cpu-shares", "", "2048", "cpu shares")
runDocker.Flags().StringVarP(&ResourceLimitCfg.CpuSet, "cpu-set", "", "0", "cpu set")
runDocker.Flags().StringVarP(&ResourceLimitCfg.CpuMems, "cpu-mems", "", "0", "cpu memory")
}
cmd/commands.go
package cmd
import (
"github.com/spf13/cobra"
"xwj/mydocker/cgroups/subsystems"
"xwj/mydocker/container"
)
const (
initUsage = `Init container process run user's process in container.Do not call it outside.`
runUsage = `Create a container with namespace and cgroups limit: myDocker run -t [command]`
)
var (
tty bool // 是否交互式执行
ResourceLimitCfg = &subsystems.ResourceConfig{
} // 资源限制配置
CgroupName = "myDockerTestCgroup" // 新建的cgroup的名称
)
var initDocker = &cobra.Command{
Use: "init [command]",
Short: initUsage,
Long: initUsage,
Args: cobra.ExactArgs(1),
RunE: func(cmd *cobra.Command, args []string) error {
// 获取传递的command参数,执行容器的初始化操作
return container.RunContainerInitProcess(args[0], nil)
},
}
var runDocker = &cobra.Command{
Use: "run [command]",
Short: runUsage,
Long: runUsage,
Args: cobra.ExactArgs(1),
Run: func(cmd *cobra.Command, args []string) {
// 获取交互flag值与command, 启动容器
container.Run(tty, args[0], ResourceLimitCfg, CgroupName)
},
}
最后修改容器的启动命令Run函数(contianer/run.go):
...
// Run
// @Description: 执行命令
// @param tty
// @param cmd
func Run(tty bool, cmd string, res *subsystems.ResourceConfig, cgroupName string){
parent := NewParentProcess(tty, cmd)
// 执行命令但是并不等待其结束
// 执行后会clone出一个namespace隔离的进程,然后在子进程中调用/proc/self/exe即自己,
// 发送init参数调用init方法初始化一些资源
if err := parent.Start(); err != nil {
log.Log.Error(err)
}
// 创建cgroup manager并通过调用set和apply设置资源限制并在容器上生效
cgroupManager := cgroups.NewCgroupManager(cgroupName)
// 设置资源限制
cgroupManager.Set(res)
// 将容器进程加入到各个子系统中
cgroupManager.Apply(parent.Process.Pid)
// 等待结束
if err := parent.Wait(); err != nil {
log.Log.Error(err)
}
cgroupManager.Destroy()
os.Exit(1)
}
2. 工作流程
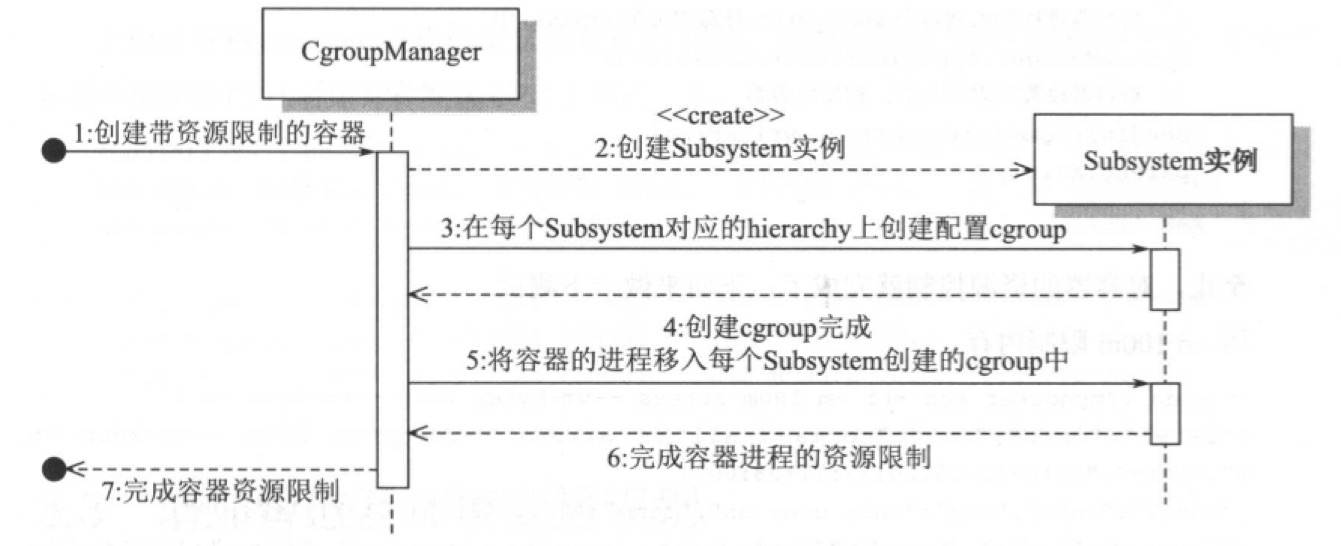
3. 测试
编译,执行
$ ./mydocker run -t -m 100m --cpu-mems 0 --cpu-set 0 --cpu-shares 2048 /bin/sh
INFO[0000]/Users/xwj/projects/go_projects/src/myDocker/dockerByMe/cgroups/cgroup_manager.go:61 xwj/mydocker/cgroups.(*CgroupManager).Set() success set limits:[MemoryLimit: 100m CpuShare: 2048 CpuSet: 0] into those subsystems method=Set
INFO[0000]/Users/xwj/projects/go_projects/src/myDocker/dockerByMe/container/initContainer.go:15 xwj/mydocker/container.RunContainerInitProcess() command /bin/sh
INFO[0000]/Users/xwj/projects/go_projects/src/myDocker/dockerByMe/cgroups/cgroup_manager.go:40 xwj/mydocker/cgroups.(*CgroupManager).Apply() success apply process[19503] into cgroups method=Apply
在容器内的交互窗口下执行压力测试:
$ stress --vm-bytes 200m --vm-keep -m 1
因为我们设置了100m的限制,所以无法启动会被kill掉
当调整启动的内存<100m(留一些给容器其他进程)例如stress --vm-bytes 90m --vm-keep -m 1则可以成功运行
最为直接的,我们可以查看/sys/fs/cgroup/cpu/myDockerTestCgroup 、 /sys/fs/cgroup/cpuset/myDockerTestCgroup、/sys/fs/cgroup/memory/myDockerTestCgroup
其下的一众文件,可以发现pid被加入到了tasks文件,并且一些相应文件值也得到了设置。同时在容器exit后再观察这些文件,可以发现myDockerTestCgroup文件夹都被删除了。
4. Run-version3
本节的版本主要是给run命令增加一些功能,添加管道和环境变量的识别功能:
- 建立父子进程之间的通信管道传递命令
- 识别容器中执行的命令的绝对路径,从而不用写完整命令
本版本代码切换:
$ git clone https://github.com/xwjahahahaha/myDocker.git
$ git checkout 94249
项目结构变化:
.
├── README.md
├── cgroups
│ ├── cgroup_manager.go
│ └── subsystems
│ ├── cpu.go
│ ├── cpuset.go
│ ├── memory.go
│ ├── subsystem.go
│ └── utils.go
├── cmd
│ ├── commands.go
│ ├── init.go
│ └── root.go
├── container
│ ├── initContainer.go
│ ├── process.go
│ └── run.go
├── go.mod
├── go.sum
├── log
│ ├── init.go
│ └── log.go
├── main.go
1. 管道
进程之间通信就会使用管道的机制。管道就是连接两个进程的通道,它是linux进程间通信即支持IPC的其中一种方式。一般来说管道都是半双工的,一端写、另一端读。
常用的管道分类为:
-
无名管道
一般用于有亲缘关系的进程之间
-
有名管道/FIFO管道
一种存在于文件系统的管道,可以被两个没有任何亲缘关系的进程访问。一般可以通过
mkfifo()函数创建
本质上,管道也是文件的一种,但是它和文件通信的区别在于管道有一个固定大小的缓冲区(一般是4KB)
当管道被写满时,写进程就会被阻塞,直到有读进程读出。同样,如果管道内是空的读进程也会阻塞,等待写进程的写入。
之前实现的简单版本的run命令有缺点在于传递参数。在父进程与子进程之间传递参数使用的是后面跟着参数,也就是/proc/self/exe init args然后在init中解析这个参数,执行命令。如果用户输入的命令很长或者带有特殊字符,那么这种方案就无法使用了。runC实现的方案是通过匿名管道来实现父子进程之间的通信的。
2. 实现
首先修改代码实现上面的功能,contianer/process.go (将原来的run.go中的NewParentProcess函数转移到了这里)
实现创建一个匿名管道,并返回读写两端
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
下面修改创建父进程的函数:
// NewParentProcess
// @Description: 创建新的命令进程(并未执行)
// @param tty
// @return *exec.Cmd
// @return *os.File 管道写入端
func NewParentProcess(tty bool) (*exec.Cmd, *os.File) {
// 创建匿名管道
readPipe, writePipe, err := NewPipe()
if err != nil {
log.LogErrorFrom("NewParentProcess", "NewPipe", err)
return nil, nil
}
// 调用init初始化一些进程的环境和资源
// 设置/proc/self/exe的命令就是调用自己
cmd := exec.Command("/proc/self/exe", "init")
// 使用Clone参数设置隔离环境
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
// 如果设置了交互,就把输出都导入到标准输入输出中
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
// 在这里传入管道文件读取端的句柄
// ExtraFiles指定要由新进程继承的其他打开文件。它不包括标准输入、标准输出或标准错误。
cmd.ExtraFiles = []*os.File{
readPipe}
return cmd, writePipe
}
其中我们核心要处理的问题就是如何将父进程创建的管道的读取端给子进程
好在,有封装好的方法可以实现:cmd.ExtraFiles
标准包注释:
ExtraFiles指定要由新进程继承的其他打开文件。它不包括标准输入、标准输出或标准错误。如果不为空,那么实体 i i i对应的文件描述符就是 3 + i 3+i 3+i
意思就是让执行的子进程继承一些文件,用[]*os.File类型设置,将读取端继承给子进程。对于标准输入、输出、错误在创建子进程的时候都是默认带着的/继承的, 所以前三个文件描述符就是这三个占用了(也解释了 3 + i 3+i 3+i)。
下面来看子进程的改动:
func readUserCommand() []string {
// 读取文件描述为3的文件, 也就是传递过来的管道的读取端
pipeReader := os.NewFile(uintptr(3), "pipe")
// 读取管道中的所有数据
cmds, err := ioutil.ReadAll(pipeReader)
if err != nil {
log.LogErrorFrom("readUserCommand", "ioutil.ReadAll", err)
return nil
}
cmdStrs := string(cmds)
// 按空格分割命令
return strings.Split(cmdStrs, " ")
}
这里直接通过管道读取父进程的命令,但是父进程可能还没有写入,所以此时就会在此阻塞等待
func RunContainerInitProcess() error {
// 从管道中读取用户的所有命令
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
return fmt.Errorf(" Run container get user command error, user cmd is nil.")
}
// 首先设置/proc为私有模式,防止影响外部/proc
if err := syscall.Mount("", "/proc", "proc", syscall.MS_REC | syscall.MS_PRIVATE, ""); err != nil {
log.Log.WithField("method", "syscall.Mount").Error(err)
return err
}
// 挂载/proc文件系统
// 设置挂载点的flag
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
if err := syscall.Mount("", "/proc", "proc", uintptr(defaultMountFlags), ""); err != nil {
log.Log.WithField("method", "syscall.Mount").Error(err)
return err
}
// 寻找在系统PATH下该命令的绝对路径 cmdArray[0]就是命令,后面的都是flag或其他参数
path, err := exec.LookPath(cmdArray[0])
if err != nil {
return fmt.Errorf(" Exec look path error : %v", err)
}
log.Log.Infof("Find path %s", path)
if err := syscall.Exec(path, cmdArray, os.Environ()); err != nil {
log.Log.WithField("method", "syscall.Exec").Error(err)
return err
}
return nil
}
exec.LookPath可以帮助我们从PATH中获取命令的绝对路径,所以我们在写需要执行命令的时候就不用写完全了。例如之前/bin/sh就可以写成sh
最后,我们将父进程发送命令的代码加上: container/run.go
// Run
// @Description: 执行命令
// @param tty
// @param cmd
func Run(tty bool, cmdArray []string, res *subsystems.ResourceConfig, cgroupName string){
// 获取到管道写端
parent, pipeWriter := NewParentProcess(tty)
if parent == nil {
log.LogErrorFrom("Run", "NewParentProcess", fmt.Errorf(" parent process is nil"))
return
}
// 执行命令但是并不等待其结束
// 执行后会clone出一个namespace隔离的进程,然后在子进程中调用/proc/self/exe即自己,
// 发送init参数调用init方法初始化一些资源
if err := parent.Start(); err != nil {
log.Log.Error(err)
}
// 发送用户的命令
sendUserCommand(cmdArray, pipeWriter)
// 创建cgroup manager并通过调用set和apply设置资源限制并在容器上生效
cgroupManager := cgroups.NewCgroupManager(cgroupName)
// 设置资源限制
cgroupManager.Set(res)
// 将容器进程加入到各个子系统中
cgroupManager.Apply(parent.Process.Pid)
// 等待结束
if err := parent.Wait(); err != nil {
log.Log.Error(err)
}
cgroupManager.Destroy()
os.Exit(1)
}
// sendUserCommand
// @Description: 想子进程管道中发送命令
// @param cmdArray
// @param pipeWriter
func sendUserCommand(cmdArray []string, pipeWriter *os.File) {
command := strings.Join(cmdArray, " ")
log.Log.Infof("First execute cmd is %s", command)
if _, err := pipeWriter.WriteString(command); err != nil {
log.LogErrorFrom("sendUserCommand", "WriteString", err)
return
}
err := pipeWriter.Close()
if err != nil {
log.LogErrorFrom("sendUserCommand", "Close", err)
return
}
}
3. 工作流程
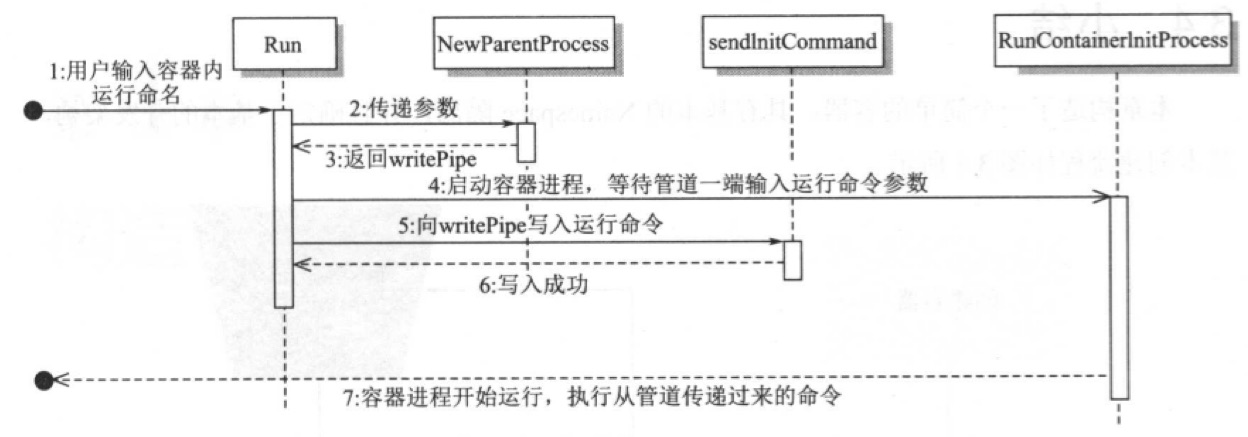
4. 测试
$ ./mydocker run -t "ls -l"
$ ./mydocker run -t "sh"

问题:
不知道cobra怎样只识别自己设置的flag,对于没有设置的flag不去判断其错误?
例如
$ ./mydocker run -t ls -l如果去掉引号就会报错:
Error: unknown shorthand flag: 'l' in -l如果加上引号,其实和version2直接传递一个string没有什么太大的功能差别
1.3 总结
目前实现了了一个简单的容器,具有基本的Namespace隔离、cgroups资源限制以及进程间的管道通信
总体逻辑如下:
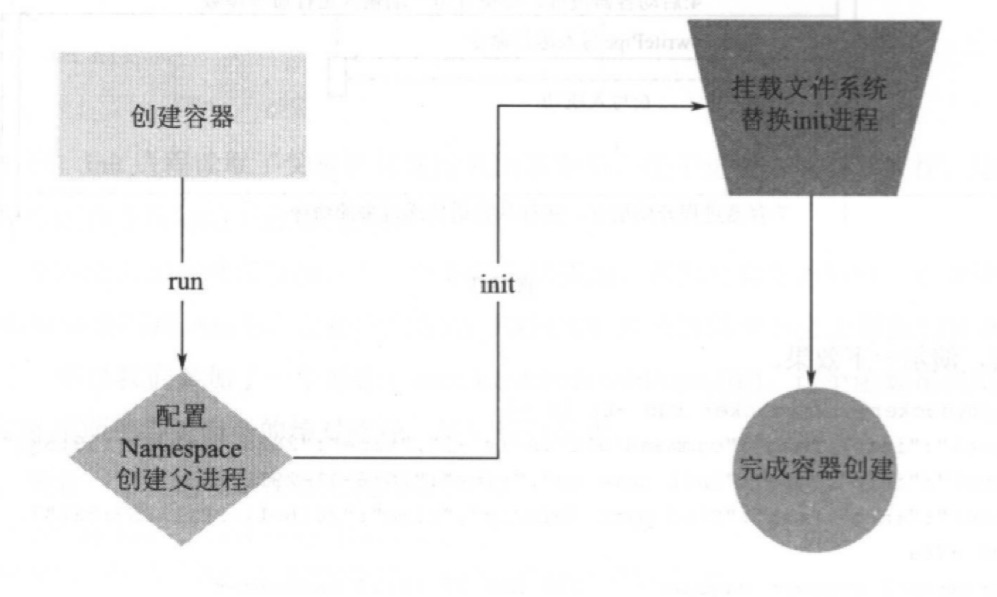
觉得不错的话,请点赞关注呦~~你的关注就是博主的动力
关注公众号,查看更多go开发、密码学和区块链科研内容: