一.前言
最近博主在梳理yolov5的源码,这块相信很快就能和大家见面了。与此同时我也觉得这个系列应该也配上一点实战的内容。尤其是目前端到端的实战篇真的是太少了,大部分都是讲训练的过程,但是yolov5更多的是要用到端上,比如安卓手机或者ios手机。
本篇教程就是完成这样一件事,从数据集开始完整的阐述训练+部署的详细过程,相信大家只要跟着走一遍,就能对完整的项目流程有更为清晰的认识。同时为了阅读的生动有趣,我这里打算做一个小浣熊识别的App,放到安卓手机上去识别小浣熊的照片。
二.环境、数据准备
环境:
- GPU服务器(不用很好,数据量很小)
- 开发笔记本电脑
- 安卓或者IOS手机,用于安装App
- 软件:Android Studio、FileZilla、Xshell
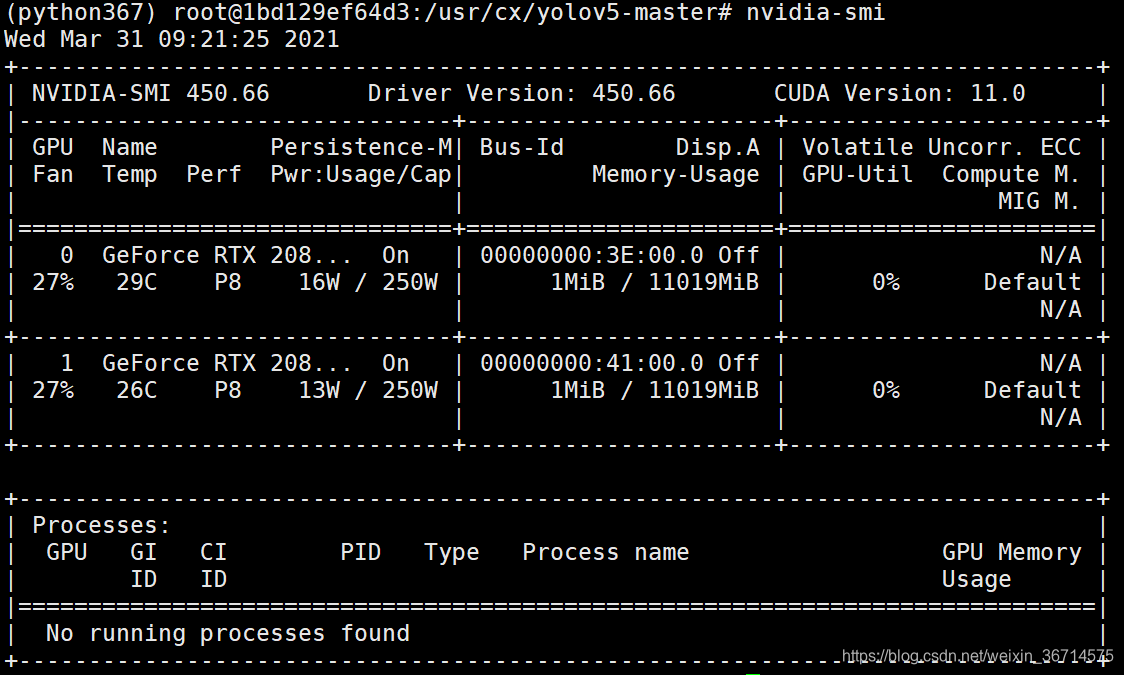
使用watch -n 0.1 nvidia-smi动态查看显卡情况:
数据:
这里推荐一个很好的数据网站,这里可以下载到各种常见目标检测数据集:
我们使用的就是这个Raccoon的小浣熊数据集,包含196张图片。
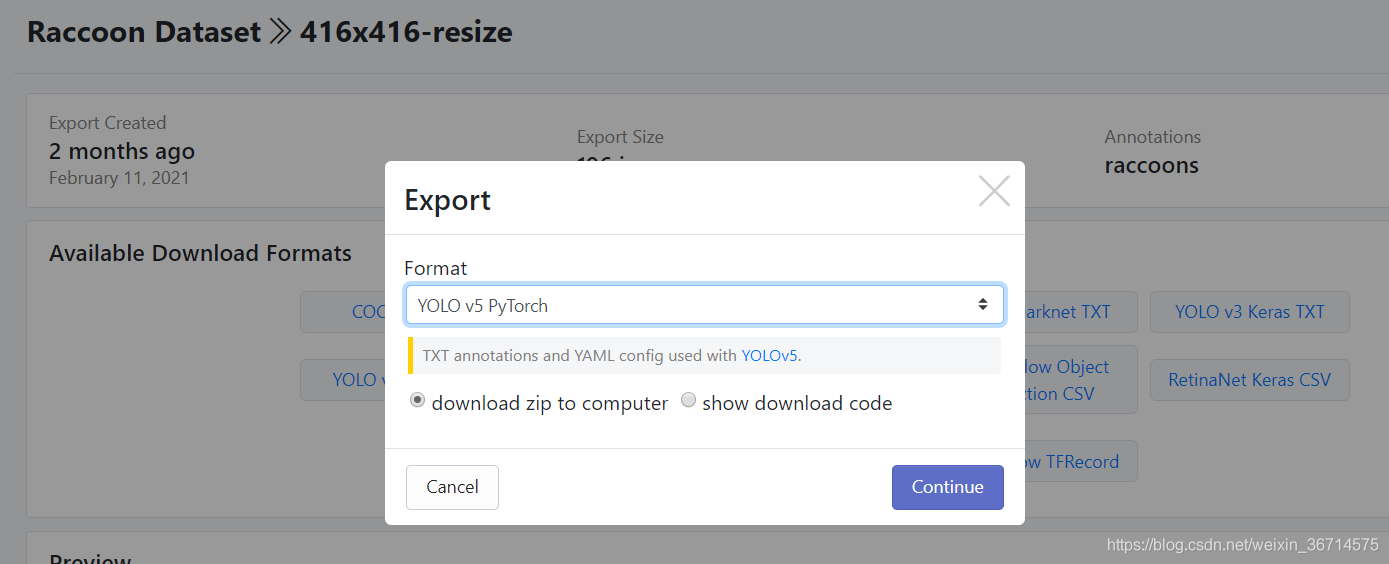
在下载页面我选择的是416*416 resize的图片。直接选择yolov5可以识别的label txt形式。
下载数据集后,划分train/val数据集。我这里是150:46。
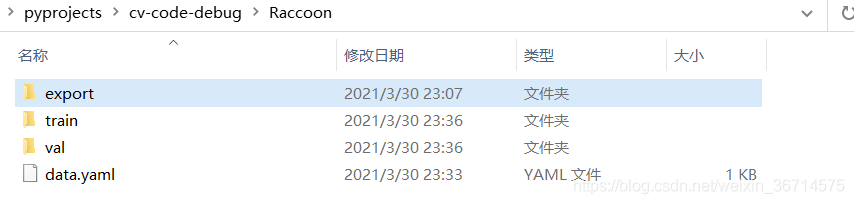
准备好数据,我们就可以上传到GPU服务器。
框架代码:
把源码也clone到服务器上。

然后安装requiremens.txt,yolov5 4.0版本要求如下:
# base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# logging -------------------------------------
tensorboard>=2.4.1
# wandb
# plotting ------------------------------------
seaborn>=0.11.0
pandas
# export --------------------------------------
# coremltools>=4.1
# onnx>=1.8.1
# scikit-learn==0.19.2 # for coreml quantization
# extras --------------------------------------
thop # FLOPS computation
pycocotools>=2.0 # COCO mAP
安装依赖建议使用清华源或者其他国内第三方源。
此外yolov5的预训练权重可以直接通过FileZilla上传到weights目录下。
安装完后执行python detect.py,遇到如下问题:
traceback (most recent call last):
File "detect.py", line 5, in <module>
import cv2
File "/root/anaconda3/envs/python367/lib/python3.6/site-packages/cv2/__init__.py", line 5, in <module>
from .cv2 import *
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
解决方法:
sudo apt update
sudo apt install libgl1-mesa-glx

detect成功,说明yolov5的部署是成功了的。
整个目录如图所示:

三.训练
- 训练命令
python train.py --data ./Raccoon/data.yaml --cfg models/yolov5s.yaml --weights 'weights/yolov5s.pt' --batch-size 48 --multi-scale --deivce 0,1 --sync-bn --epochs 200
参数含义
1. --data:数据的配置文件,里面包含train、val的images和labels的位置。
2. --cfg:model的配置文件,用于动态加载模型。
3. --weights:预训练权重,用于transfer learning。
4. --batch-size:批大小。
5. --multi-scale:多尺度训练,开启后每个batch自动缩放图像+-50%。
6. --device:使用的GPU服务器,我这里是2块2080Ti的卡。所以填0,1,单卡可以不填。
7. --sync-bn:同步bn,单卡可以不填。
8. --epochs:迭代轮数
训练200个epoch,验证集[email protected]有0.875。
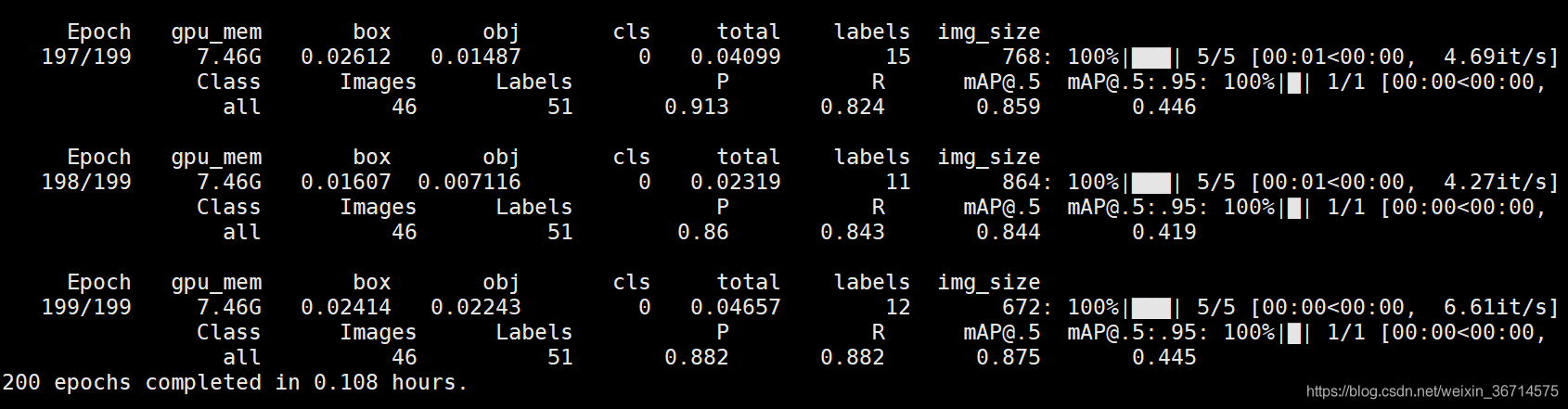
分析结果
在"runs/train"文件夹里面,存储了默认生成的结果。我们来看下:
原始的test label:

我们预测的情况:

发现大部分预测还可以,也有部分漏标错标的情况。
整体训练的learning curves:
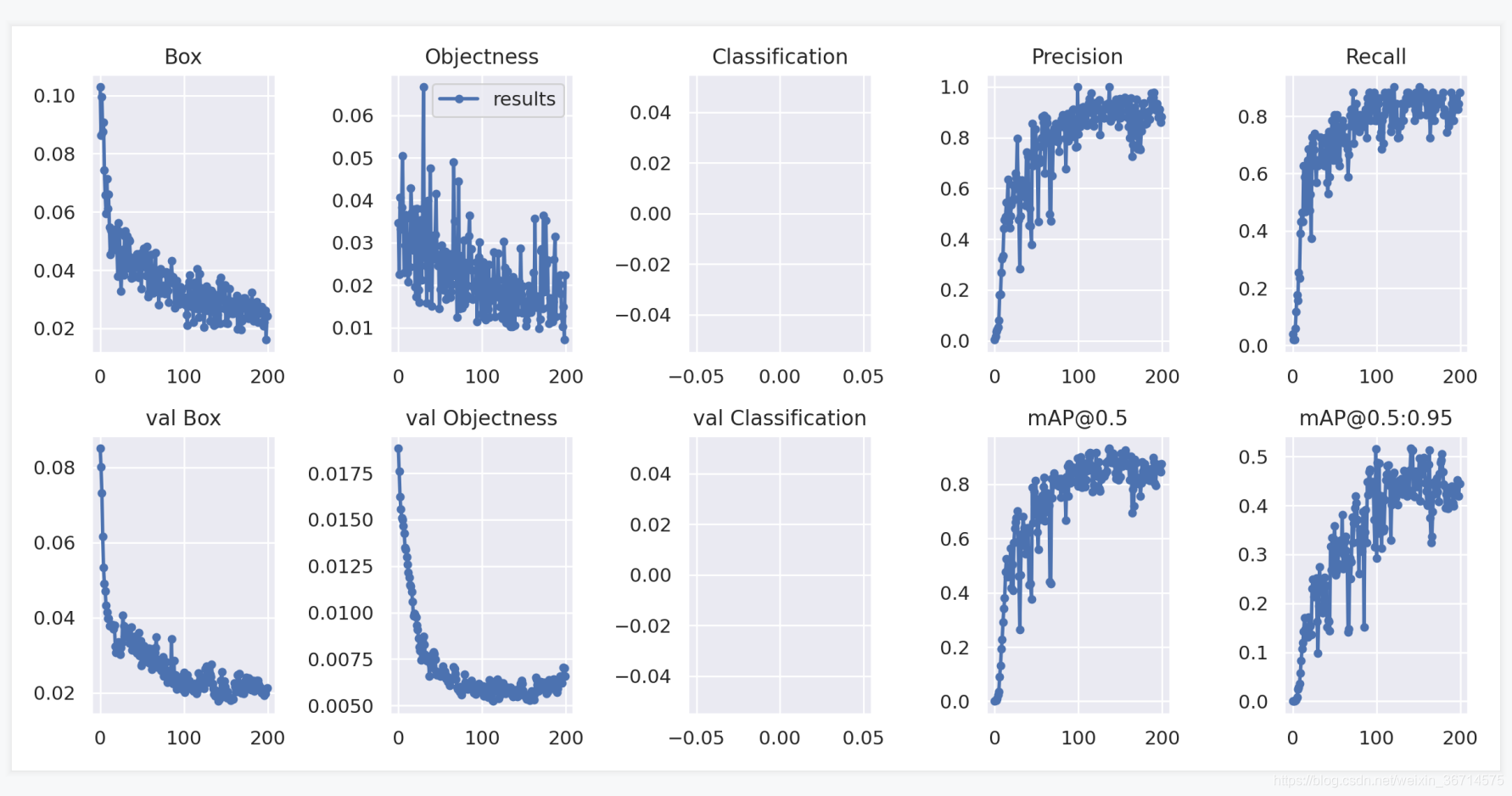
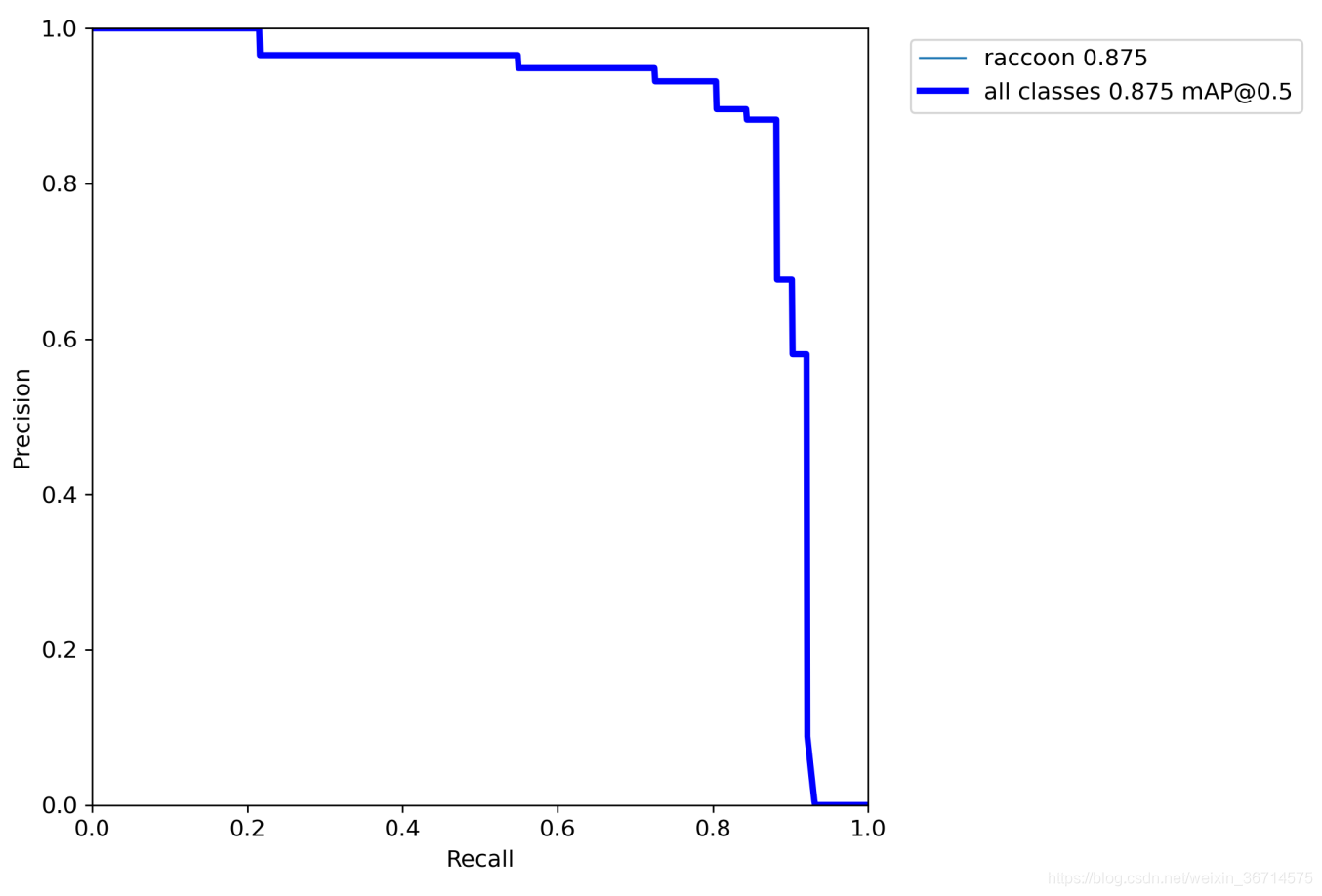
PR曲线情况:
混淆矩阵:
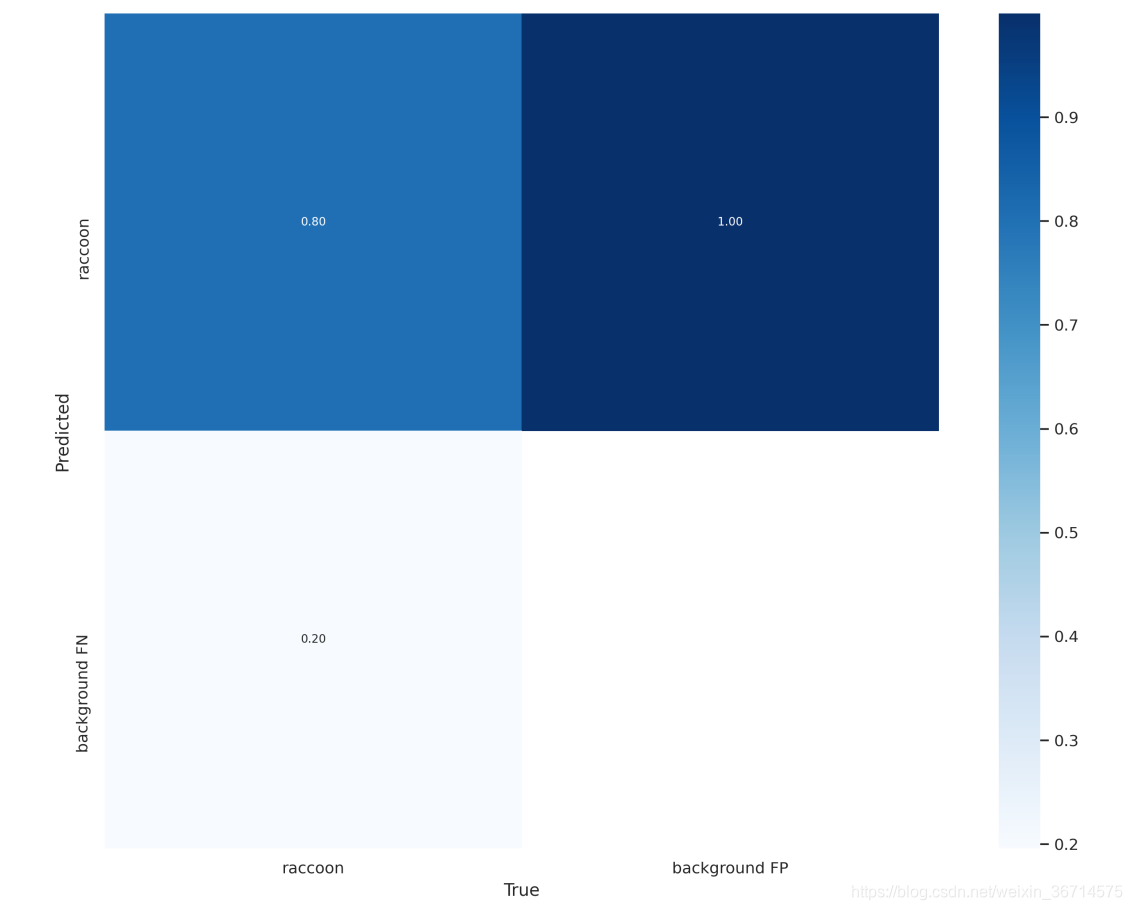
这里我们只作为演示,精度的增加,大家自行尝试。
得到了最终的参数结果best.pt。后面我们就把他部署到端上。
四.部署
现在我们得到了pytorch的.pt模型,现在我们要把它放到端上,博主这里是用的一台oneplus8T手机。整体pytorch模型放到安卓上的转换思路是pt=>onnx=>ncnn。所以我们来逐步操作下:
1.安装onnx依赖库
pip install onnx coremltools onnx-simplifier
安装成功:
Successfully installed attr-0.3.1 attrs-20.3.0 coremltools-4.1 mpmath-1.2.1 onnx-1.8.1 onnx-simplifier-0.3.3 onnxoptimizer-0.2.5 onnxruntime-1.7.0 packaging-20.9 sympy-1.7.1
2.转换刚刚训练好的best.pt文件到onnx文件。
python models/export.py --weights weights/runs/train/ex8/weights/best.pt
得到了best.onnx文件。
(python367) root@1bd129ef64d3:/usr/cx/yolov5-master# ls runs/train/exp8/weights/
best.mlmodel best.onnx best.pt best.torchscript.pt last.pt
3.使用onnx-simplier简化模型
python -m onnxsim best.onnx best-sim.onnx

得到简化后的模型:best-sim.onnx。
4.使用ncnn工具转化.onnx为.bin文件
这里需要编译ncnn,下面给出编译流程。当然也可以不编译用prebuild包:
- 准备编译环境:
sudo apt install build-essential libopencv-dev cmake
- 编译protobuf
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git submodule update --init --recursive
./autogen.sh
./configure
make
make install
sudo ldconfig
- 编译ncnn,生成onnx2ncnn工具
git clone https://github.com/Tencent/ncnn.git
cd ncnn
git submodule update --init
mkdir build
cd build
cmake ..
make -j8
make install
编译的痛大家都懂,所以也可以使用prebuild的安装包:
ncnn历史releases:https://github.com/Tencent/ncnn/releases
大家自行对应好自己的linux os版本,我这里是ubuntu18。
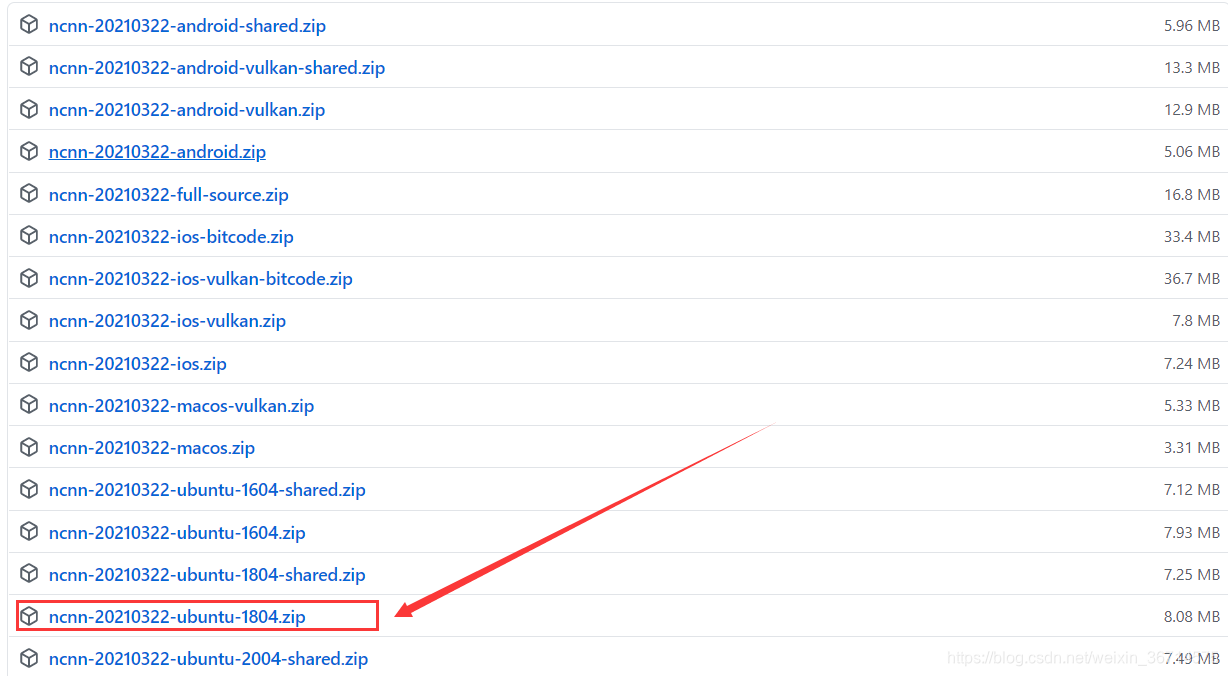
下载到服务器上,获得onnx2ncnn转换工具:

- 转换.onnx为.bin文件
/usr/cx/ncnn-20210322-ubuntu-1804/bin/onnx2ncnn best-sim.onnx yolov5s.param yolov5s.bin
报如下错:
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
这里的问题是onnx不支持slice操作需要修改为Focus:
我们在如下网址可视化刚刚生成的yolov5s.param文件:
模型可视化

看到我们的模型是这样的:
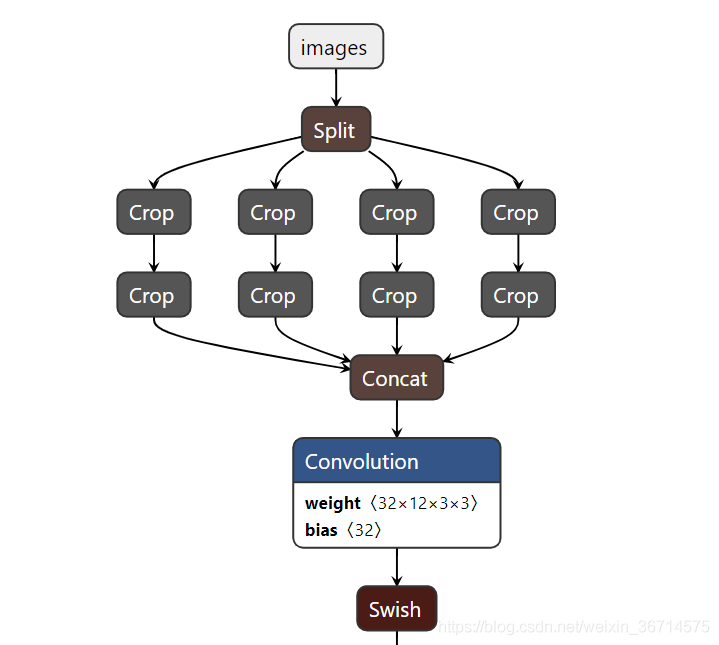
这里我们对应修改yolov5s.param文件:
原始如下:需要把从Split到Concat这10层替换成Focus层:
7767517
185 212
Input images 0 1 images
Split splitncnn_input0 1 4 images images_splitncnn_0 images_splitncnn_1 images_splitncnn_2 images_splitncnn_3
Crop Slice_4 1 1 images_splitncnn_3 131 -23309=1,0 -23310=1,2147483647 -23311=1,1
Crop Slice_9 1 1 131 136 -23309=1,0 -23310=1,2147483647 -23311=1,2
Crop Slice_14 1 1 images_splitncnn_2 141 -23309=1,1 -23310=1,2147483647 -23311=1,1
Crop Slice_19 1 1 141 146 -23309=1,0 -23310=1,2147483647 -23311=1,2
Crop Slice_24 1 1 images_splitncnn_1 151 -23309=1,0 -23310=1,2147483647 -23311=1,1
Crop Slice_29 1 1 151 156 -23309=1,1 -23310=1,2147483647 -23311=1,2
Crop Slice_34 1 1 images_splitncnn_0 161 -23309=1,1 -23310=1,2147483647 -23311=1,1
Crop Slice_39 1 1 161 166 -23309=1,1 -23310=1,2147483647 -23311=1,2
Concat Concat_40 4 1 136 146 156 166 167 0=0
Convolution Conv_41 1 1 167 168 0=32 1=3 11=3 2=1 12=1 3=1 13=1 4=1 14=1 15=1 16=1 5=1 6=3456
替换后:

注意中间只能用空格,不能用tab键,否则后面app会崩溃。
对应还需要修改总的层数,185改为176,因为我们减少了9层。
注意改完后应该保证Netron的呈现是连贯的:
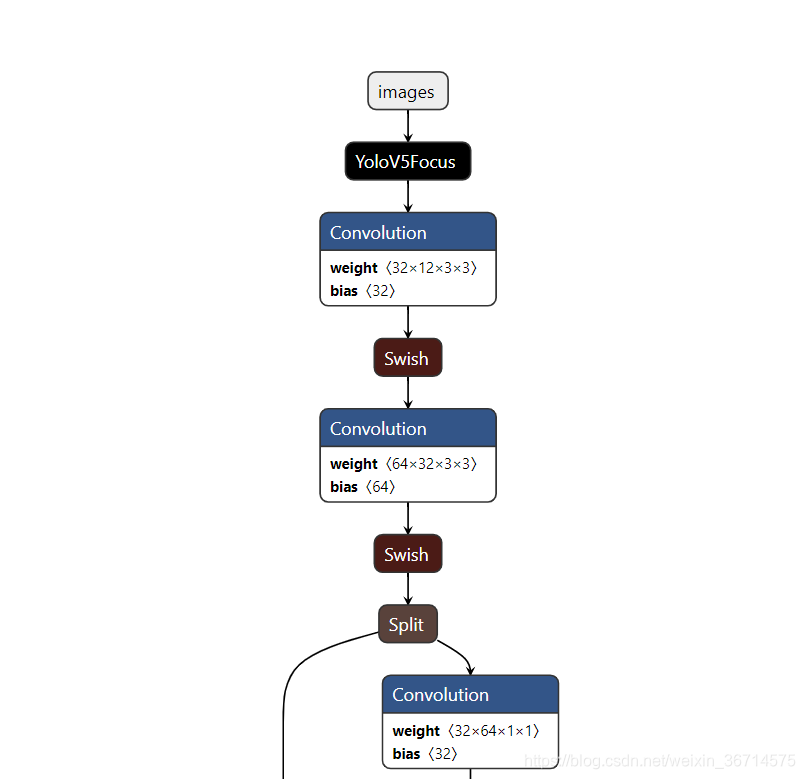
5.模型压缩、半精度转化
ncnnoptimize yolov5s.param yolov5s.bin yolov5s-opt.param yolov5s-opt.bin 65536
得到最终的yolov5s-opt.param以及yolov5s-opt.bin,我们重新命名为yolov5s.param和yolov5s.bin。
6.使用android studio打包
1.下载example源码
我们基于ncnn官方的example进行打包测试:
example地址如下:
我们下载这个example code:
https://github.com/nihui/ncnn-android-yolov5.git
解压后用android studio打开,用gradle自动构建工程。
2.下载ncnn安卓开发环境的依赖
打开ncnn的releases网址

下载如图的安卓版本,vulkan是加速版本。
解压后得到四个文件夹:
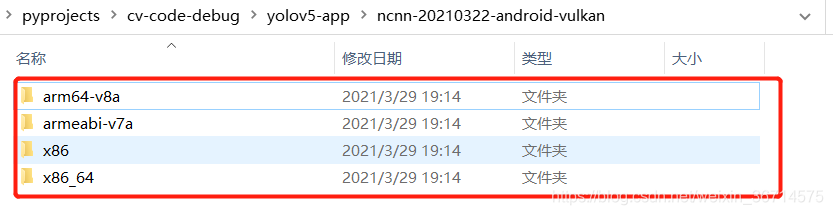
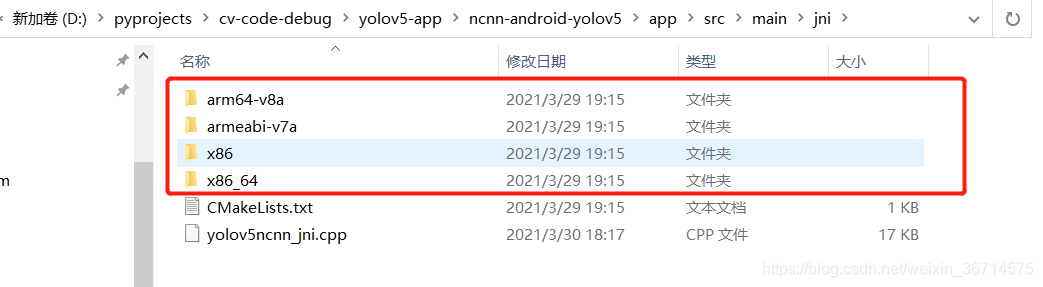
把他们拷贝到刚刚的example code的对应位置 (app/src/main/jni/):
3.修改文件
- yolov5s.param
需要修改三个Reshape的输出:

全部修改为0=-1,自动判断输出大小。如果不修改这里,直接跑小图,会发现检测框密密麻麻布满整个画面,或者根本检测不到东西。
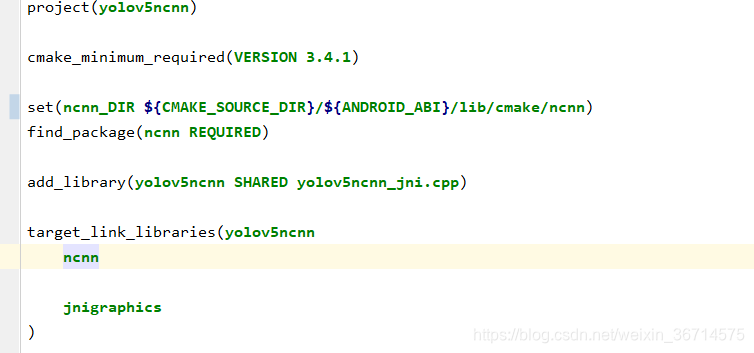
- CMakeLists.txt
然后修改同级目录下的CMakeLists.txt,将其中的ncnn_DIR变量值修改成:
set(ncnn_DIR ${
CMAKE_SOURCE_DIR}/${
ANDROID_ABI}/lib/cmake/ncnn)
- 修改yolov5ncnn_jni.cpp
搜索"output"关键字,定位到几个FPN的输出:
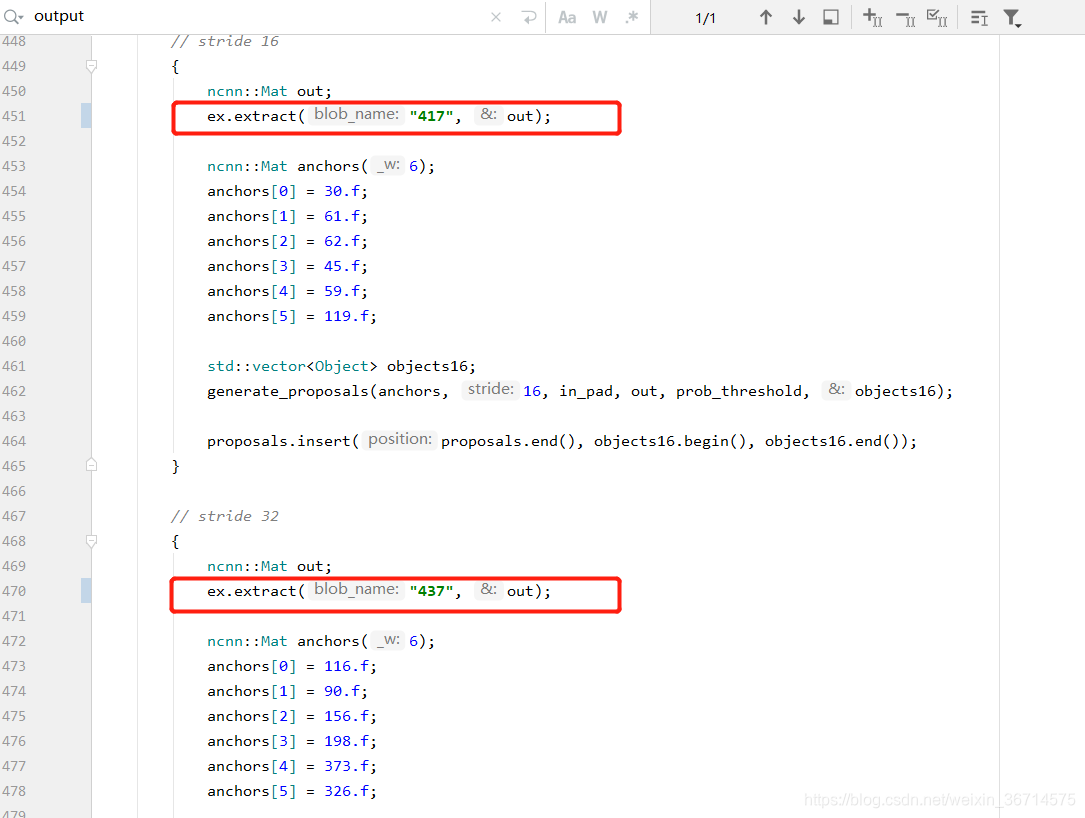
这里需要根据yolov5s.param里的实际编号填写,在yolov5s.param里搜索Permute关键字:
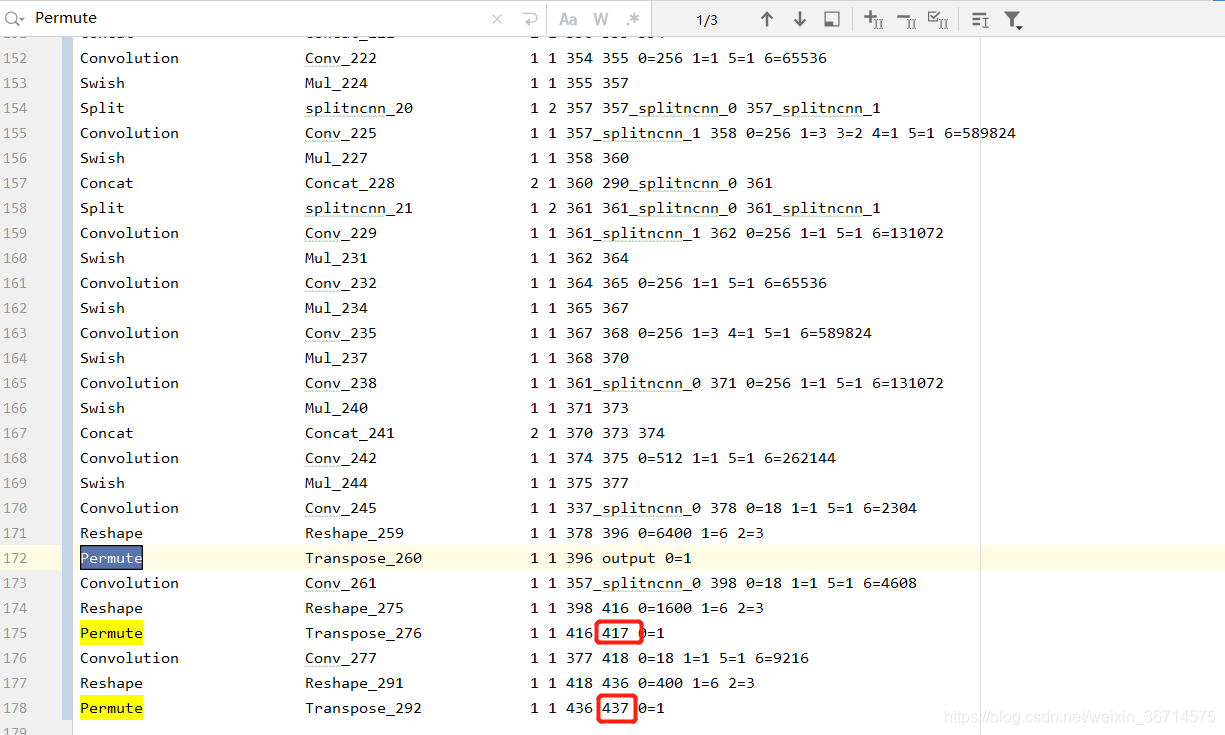
将真实输出(红框)里的值填进刚刚output的位置。
最后注释掉coco数据集的标签,改为我们的,我们只有一个"raccon"类:

7.安装Apk测试效果
用数据线连接手机,打开开发者模式。
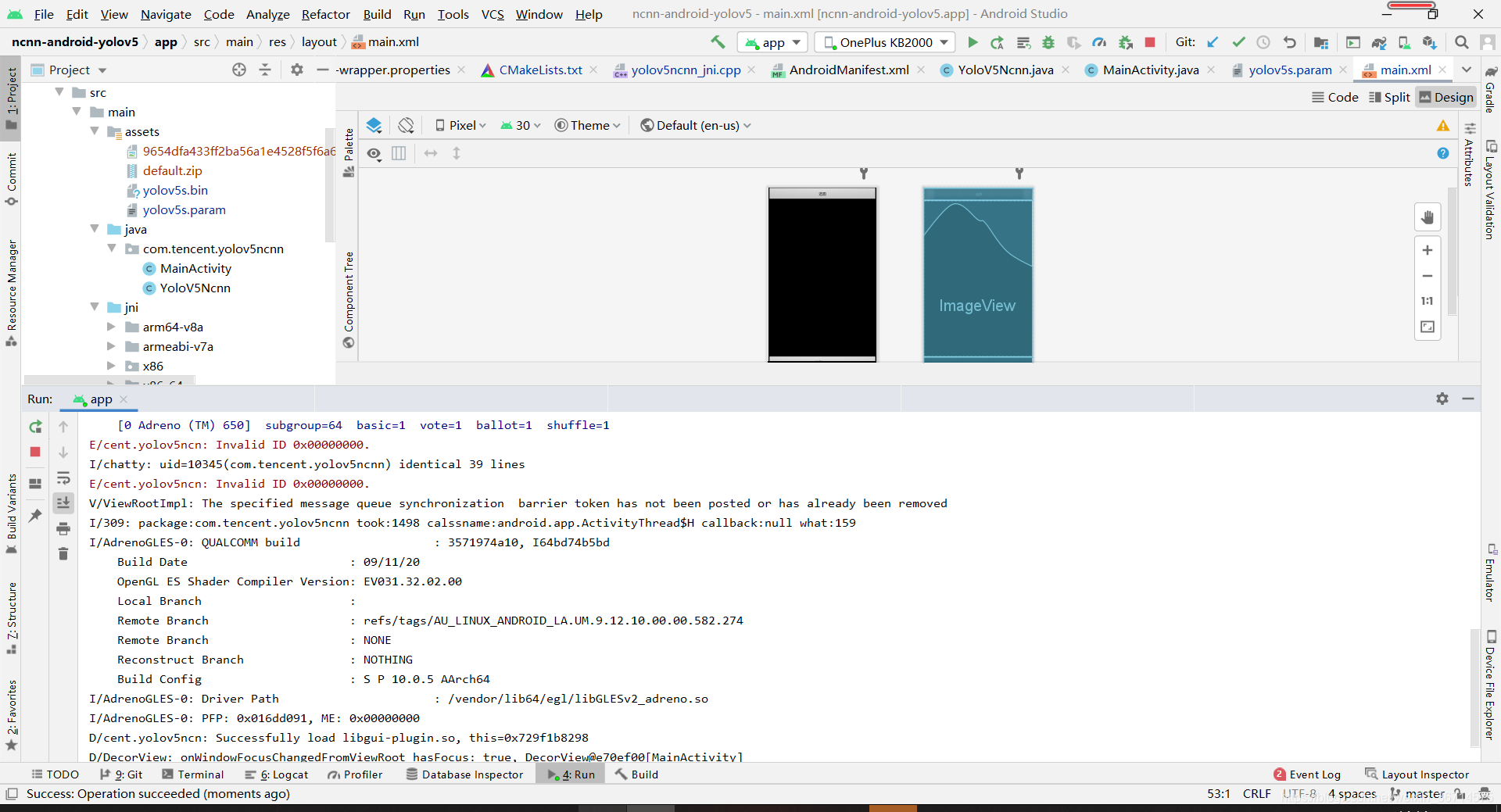
在android studio点击绿色按钮,安装apk。同时android studio会打印调试信息。
同时手机上生成了apk:

我们点击"选图"选择一张小浣熊的图片。

然后使用GPU或者CPU识别,投掷大师球:

干脆面君,哦不,小浣熊被大师球抓住了!!
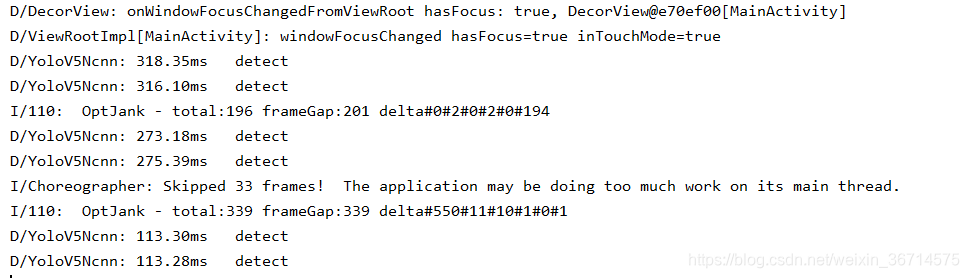
客户端打印信息,在我的手机GPU识别大概要100ms的样子。
8.结语
通过这篇教程的我们手把手完成了一个基于yolov5训练的模型,再到安卓apk部署的完整流程。后面我们将继续深入yolov5的源码。
最后致谢过程种帮助我的大佬和收获知识的博客:
如果大家觉得有收获,就点赞关注支持博主吧!