Visual Dialog 论文阅读笔记
根据图像和历史对话推断语境回答问题对比:VQA只有一轮问答,没有储存历史信息如果下一个问题和上一个问题相关如存在指代,就非常有用与机器人讲话有两种情况:一是目的驱使,二是随便说
相关工作
视觉图灵测试:这个只有模式化的问答,我们是开放的回答,而且我们的数据库更加丰富基于文本的问答:融合了这个方面的研究以及图像,问题的答案不能出现在之前的对话中对话机器人 自由的对话和视觉对话的区别是视觉对话问答关系明确。所以视觉对话的任务是帮助人建立完整的模型
数据库
1 COCO2
2 人物对话基于COCO
让两个人一问一答 收集他们问答的数据这样的问答要求像自然的交谈 不是简洁的问答。 提问者看到字幕,回答者看到字幕和图像。也尝试了提问者看到模糊的图像。不过完整的数据库还是采用的字幕,因为应用更广,更接近实际
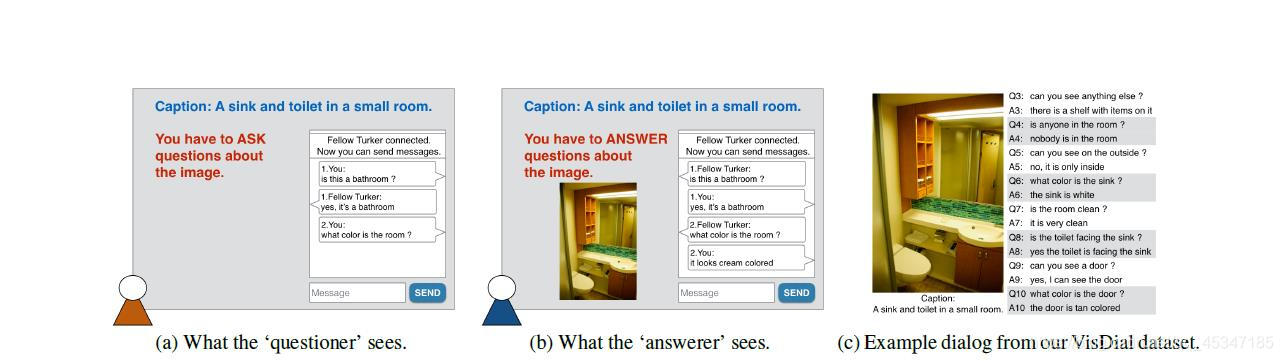
3两人对话基于AMT
因为AMT不支持两人对话的任务 所以自行设计了前端后端界面。同时遇到一个问题没答完给另一个人接着答得情况,自动识别丢弃并根据图像重新建立对话
视觉数据库分析
问题分析
1视觉初偏见
视觉对话没有视觉启动偏见。因为之前得工作都是:受试者看着图像问问题,导致问的东西图像里面大概率是存在的,所以VQA只用基于语言的就可以回答得很好,不需要看之前的历史信息和有关的图像情况下
2词汇分配
统计了一下VQA和visdial的问题使用词汇 发现VQA最常用what visdial常用is 另一格式上的不同 VQA能看到图像 所以倾向于刁难机器人,常问背景里的东西。visdial是为建立整体模型 问题有一定的模式
回答分析
1统计答案长度,发现更长。并且有更多独立的答案
2回答的种类。出现了无法回答的情况。因为提问者不能看到图像所以可能问出缺少信息的问题。这使机器人更像人
3在一般疑问句中 机器人不仅回答是否 还会增加额外的信息
分析视觉对话
问题和回答都包含了指代关系
对话主题的时间连续性 visdial 比VQA的问题更有连续性
视觉对话评估
协议评价自由格式的回答很难
不是采用自由聊天的整体评价模式,而是对一轮对话中的每一个回答进行评估
测试的时候,视觉对话系统被给与字幕和前面t-1个问题和答案。根据第t个问题,对所有候选回答进行排序
通过检索度量评估,
1将人类回应排名
2人类回答在前k个是否存在 测试的时候是对100组对话 存在的记1,不存在的记0,加起来看结果
3人类回答的MRR指数(平均交互排名)
该协议可以兼容两种模型 一是softmax对候选的答案排序 二是用循环网络产生一个答案序列
ground truth 在机器学习中ground truth表示有监督学习的训练集的分类准确性,用于证明或者推翻某个假设。有监督的机器学习会对训练数据打标记,试想一下如果训练标记错误,那么将会对测试数据的预测产生影响,因此这里将那些正确打标记的数据成为ground truth。
候选答案:从四组中抽选一组
1 correct
2 plausible 看似可信 是50个相近问题的答案,相近的判断方法是语句开始相同(使用tri-gram),剩余部分提到同样的语义含义。 方法:所有问题嵌入一个向量空间,向量的构造就是连结问题前三个次Glove模型产生的嵌入向量和剩余部分平均Glove模型产生的嵌入向量,用欧式距离计算。
3 popular 30个最常见的回答 机器有可能会选择最常见的而不是最适合的,增加难度
*N-gram 介绍
添加链接描述
*https://blog.csdn.net/songbinxu/article/details/80209197N-gram
模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。
一个词的出现依赖其他词可用于词性标注 垃圾短信分类 分词器 机器翻译和语音识别

Glove
添加链接描述
(https://blog.csdn.net/coderTC/article/details/73864097)
用于进行词的向量化表示
神经视觉对话模型
用一个编码器一个译码器,编码器将输入的I,H, Qt转换成一个向量空间,然后译码器将嵌入的向量转换为一个输出
两种译码器
1 Generative LSTM
编码得到的向量作为LSTM RNN的初始状态,训练时最大化 通过给与对应的编码表示 正确标记答案的对数似然值。 这个方法没有利用选择产生中的偏差因为没有给选择打分, 但是这种偏差是否对训练有用还存在争议
2 Discriminative softmax
计算编码向量和LSTM得到的向量的点积 然后移到softmax里,得到概率。训练中最大化正确选择的对数似然值
三个编码器
归一化https://blog.csdn.net/qq_37469992/article/details/77923005
归一化介绍
Image 使用VGG16的最后两层进行表示
1、Late Fusion (LF) Encoder:
融合编码器
H看成是多行索引,Qt和H用两个不同的LSTMs编码
2、Hierarchical Recurrent Encoder (HRE):
分层次循环编码问答对 (Qt,At)
提出HRE
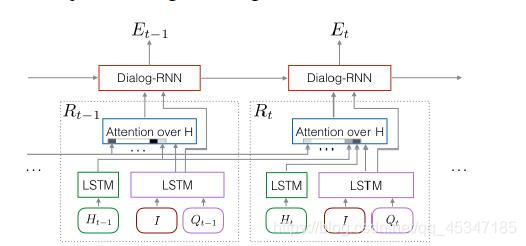
Image和question通过一次LSTM进行融合,然后和history传入attention 这一部分属于循环块Rt,然后其中几个结果通过对话RNN 得到一个编码和下一个编码的语境。attention块是用于使Rt循环块选择并注意与现有问题提相关的过去历史,将问题向量和历史向量做点积得到过去回合分数,再传入一个softmax得到概率,然后每个历史向量乘上概率加在一起得到情景向量,再通过一个全连接层,添加到问题向量中 用于构建MN
3、Memory Network (MN) Encoder: 记忆网路模块
存储过去问答
用一个LSTM编码Qt得到512维向量,用另一个LSTM编码过去回合历史 得到t*512矩阵
凸组合
每一项系数加起来等于1
https://baike.baidu.com/item/凸组合/18999826?fr=aladdin
凸组合介绍
6、实验
基准
1 回答优先 对测试问题进行编码 线性分类,使用训练集中回答的频率进行排名
2、NN-Q 给一个问题,找到训练中k个相似的问题。通过k个问题答案与训练得出的答案的平均相似度进行评分
3、NN-QI 给一个测试问题,找到K个相似问题 然后从这K个中根据图像相似性取子集为k=20,K=100,再像上一个一样进行评分
找到几个VQA的模型,砍掉最后一层分类的softmax,添加上译码编码器