Jetpack Compose近日终于迈入了Beta阶段,API也逐渐趋于稳定,所以我们也能对于Compose的设计进行初步的解读和评价了。
Compose从整体技术风格上来说是这样一个产物:在语法上激进模仿SwiftUI,编译/运行过程充满Svelte风格,同时也综合了各方包括Android开发组自身对UI框架的思考结果。
使用Compose时,最值得关注的就是Compose的编译器插件。可以这么说,Compose的runtime、api都是依附于编译器插件的,那个巨大而无所不包的编译器插件才是Compose的本体。
Compose插件强势的入侵了原版Kotlin的语法,导致包含了Compose的Kotlin基本上可以算作新语言(算成个新虚拟机都不过分)。初次了解的时候确实让我很困惑,因为这与React,Flutter推崇的趋势简直是背道而驰。但是了解了Svelte,SwiftUI之后,Compose显得没有那么突兀了。
高性能UI与通用编程语言的冲突
很久以前代码与UI都是分开用不同语言写的,React改变了UI,"Code in one language"的呼声越来越高,再到后来,他们又改了回去。
Svelte, SwiftUI, Vue3.0的趋势揭示出通用编程语言并不能很好的满足高性能UI的需求。这些语言都不约而同地选择在编译期优化上下功夫,这些优化需要大量关于代码的元信息来实现,当通用编程语言默认提供的元信息不足之后,只剩下开发者手动标注和发明新的编译流程两个选项。
(代码本身执行会产生返回值和副作用,大部分时候人们只关心返回值和副作用,但是代码本身包含的信息远多于返回值和副作用。代码是怎么写的、什么逻辑,都是编译期优化感兴趣的内容。有些语言默认携带了更多的元信息,比如如果某个函数式语言语法自带了依赖收集,那么就相当于这个语言的每个变量自己就携带了这个元信息,那么写React的useMemo时就能省略手动标注依赖项的操作。但是“通用”编程语言一般默认携带的元信息少得可怜,一般每个变量可挖掘的信息只有值、编译期类型和运行期类型。有些语言甚至后两个都是残废甚至不存在。)
Svelte
Svelte试图解决的问题是:如何用声明式的代码书写风格,一对一直接翻译成纯粹命令式的DOM操作,从而达到无额外开销+极小runtime的效果。最终Svelte选择发明一套自制的模板语法来翻译到Javascript上。这个好理解,因为大家很熟悉,显然javascript以及其工具链没有任何实现这个目标的可能。
Vue3.0
Vue3.0使用的模板则是为了另一个目的:在编译期收集UI布局的静态信息。模板的编译器可以在编译器自动识别模板里出现的那些值和节点是不变的,哪些值和节点是开发者传入的可变的变量,从而在编译结果中跳过对于不变值的Diff过程。Vue3.0的模板优化远不止这些,但从根本上来说,这些优化都是基于收集代码的元信息而实现的(或者说是在编译期实现的),基于纯javascript并不足以很好的实现这些需求,所以才产生了对于模板语法的需求。
另一方面,Vue3.0的Reactivity API倒是成功的通过hack的方式实现了类似依赖收集的特性,基本不需要手动标注,Javascript各种奇怪的特性总能带来惊喜。
SwiftUI
SwiftUI解决方案则更加夸张。由于设计目标导致SwiftUI必须由Swift单语言完成而不能搞自制语法,SwiftUI采用了两个举措来获取代码元信息:第一个是对编译器开洞,搞了黑箱式的FunctionBuilder注解,第二个是利用FunctionBuilder提供的操作空间,将感兴趣的元信息编码进编译期类型中,通过对编译期类型的解读实现类似于vue3.0的编译期优化。
具体来说,SwiftUI的FunctionBuilder能把对于表面上一个闭包调用了两个构造函数
{
Text("Hello")
Text("World")
}
转化为一个TupleView<(Text,Text)>的编译期类型,从而告知runtime:“子节点数量写死的只有两个”+“类型也是写死的”。 也能够把表面上if控制的一个构造函数
{
if something {
Text("Hello")
}
}
转化为一个Text?,告知runtime:“这个子节点是有条件出现的” 甚至连扩展方法
{
Text("Hello")
.background(Color.red)
}
返回的都是ModifiedContent<Text, _BackgroundModifier<Color>>,告知runtime代码中究竟是怎么修改的Text,修改了什么属性。
总之Swift选择用复杂的编译期类型嵌套来描述UI的绝大部分细节,相当于把代码AST中感兴趣的部分,在黑箱内转译成一个符合语言规范的表达方式(编译期类型),再传递给框架的其他部分。这个方法相对较通用,而且侵入性较低(否则直接拿着AST在框架里传来传去就相当于是在魔改编译器了)。
React
React选择**all in javascript",jsx都是直接展开成React.createElement,所以没有编译期优化。同样的useMemo后面得手动声明一堆依赖项。
Flutter
Flutter同为Google的项目,很适合与Compose进行对比。Flutter很显然对于编译期优化缺乏兴趣(同样也对很多其他高层次优化缺乏兴趣),Flutter的目的只是提供一个贴近乃至暴露底层渲染流程的跨平台app自绘引擎,提供的上层封装很浅。Flutter关心的只有运行期的各种机制,对编译期细节基本是毫无兴趣,也符合其偏向底层的风格。所以Dart这种缺乏特性的语言对Flutter来说并无大碍。(多嘴一句,Dart的趋势估计是要逐渐的成为带GC的增甜C++,更适合开发Flutter这种引擎)
Compose
Compose在框架设计方面的野心明显超越Flutter。Compose团队多次表示Compose就是对Android SDK的重写。Compose对自身的定位估计类似于SwiftUI在苹果系生态中的定位,那就是高层次、生态内通用、外加依靠自身定位尽可能挖掘以及定制工具链以实现先进的开发模式。Compose使用了语法上和Swift神似的Kotlin,也面临相似的问题,于是Compose(出于一些原因)选择了简单粗暴的魔改Kotlin编译器,而不是模仿SwiftUI玩类型系统杂耍。
Compose团队解释过Compose的出发点:构建一个通用的、描述树状结构渲染过程的框架,不管是是手机UI组件树或者是浏览器HTML Element。
Compose一不做二不休,直接把Kotlin编译器魔改到底。最后利用编译器魔改实现了几大功能。
Svelte风格的指令式翻译
Compose对于@Composable函数的翻译很有Svelte的风格,基本上做到了将声明式的函数语句一对一的翻译为针对composer的指令。这个翻译过程目前官方放出的资料很少,而且演示性质居多,一般只是针对某个特定的翻译模式来撰写简单的例子,而没有准确的、成体系的说明,真正的翻译产物远复杂于官方示例。
最简单的Counter示例
@Composable
fun Counter() {
var count by remember { mutableStateOf(0) }
Button(
text="Count: $count.",
onPress={ count += 1 }
)
}
翻译为
fun Counter($composer: Composer) {
$composer.start(123)
var count = remember($composer) { mutableStateOf(0) }
Button(
$composer,
text="Count: ${count.value}",
onPress={ count.value += 1 },
)
$composer.end()?.updateScope { nextComposer ->
Counter(nextComposer)
} // 为重渲染注册钩子
}
Button函数也是一个@Composable函数,内部也会被编译器处理。可以看到这段最简单的示例被翻译成了composer上start了一个group,执行了remember和Button的操作(Button也将被进行类似的展开,直到展开为最基础的画布操作),在end的时候注册了一个为了重渲染准备的钩子。接下来的优化,也都是基于这种指令式翻译的风格展开的。
实质上各种vdom,widget,HTML Element,Swift View结构的存在,无非都是用面向对象的方式储存基础画布操作,方便声明式编程而已。这也是Svelte风格的指令式翻译的突破点:取消掉中间层,直接编译阶段翻译为基础操作。
Positional Memoization进行状态持久化与运行期优化
Compose团队口中的“描述通用的树状结构渲染过程”很大程度上指的就是Positional Memoization。声明式编程常常遇到的问题是如何在重渲染过程中保存部分状态,从而1.实现状态管理2.方便进行Diff从而避免不必要开销。类React的方案是在组件层背后再增加一层v-dom层,这样v-dom层自然保持了状态,同时也能进行Diff,Flutter的Element层同理。但是Compose团队表示连这一层的开销他们都想省......
跳脱出面向对象,换成指令式的思路之后,这事就变得可行了。反正计算机到头来都是纸带加上读写头,纸带就是状态,读写头移到哪就在哪里Diff不就行了。Compose团队最后实现了这个暴力美学的方案,Compose的runtime还真的就是一个composer(读写头)工作在一个slot table(纸带)上。
代码的执行流程本质上就是深度遍历一棵树的过程,于是在Compose的思想里,@Composable函数代码里所有感兴趣的细节可以视为一棵AST树(不仅@Composable函数的嵌套关系被记录下来了,开发者传的每一个参数、调用的某些函数也被视为节点),然后composer执行时就相当于按照深度遍历的顺序把这棵树事无巨细的记在slot table里。如果这棵树的结构不发生变化(UI结构不发生变化),那么无论怎么重渲染,节点在纸带上的位置一定不会变化,所以composer读到相应的位置,就相当于找到了相应节点在上一轮执行时留下的状态,就叫做Positional Memoization。
以下示例来自于Google演示文档
@Composable
fun Counter() {
var count by remember { mutableStateOf(0) }
Button(
text="Count: $count",
onPress={ count += 1 }
)
}
对应在slot table上的执行结果为
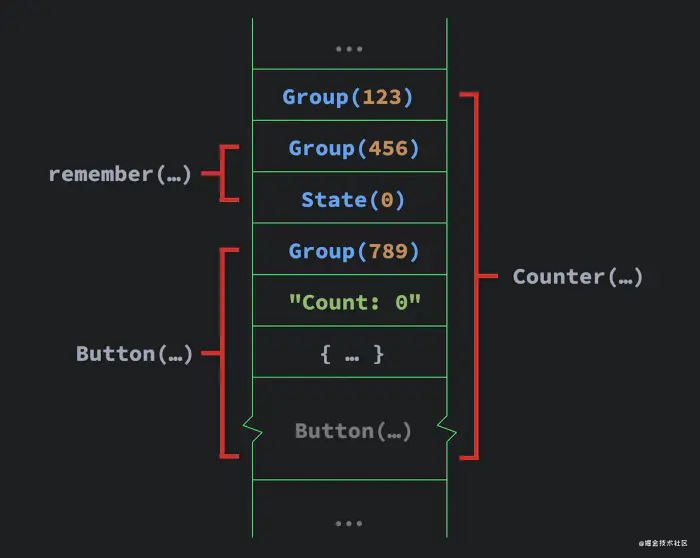
positional memoization
可以看到remember函数,state,Button函数传的参数,全部都被以深度优先遍历的顺序记录在了纸带上
Positional Memoization自然可以用作状态管理。同时,因为Compose记录了每个函数传递的参数,因此Diff操作就变成了composer在纸带上对比上一轮参数与本轮参数,从而决定是否跳过某个组件。
@Composable
fun Google(number: Int) {
Address(number=number)
}
会被编译为
fun Google(
$composer: Composer,
number: Int
) {
if (number == $composer.next()) {
$composer.skip()
} else {
Address(
$composer,
number=number
)
}
}
在没有引入额外层的情况下,Compose实现了状态的持久化和Diff操作,可以算是Compose团队创新的思路了。但是由于Compose收集以及处理的信息如此之多,这样的直接结果就是导致Compose几乎可以被称为是一个新虚拟机了
同时,根据Compose团队所述,这个模型容易实现并发渲染。原理看起来如此,但目前没有技术方案和实现,在此仅作提及。
编译期优化
到此为止,不论做不做编译期优化,Compose都已经具有了一个新型框架的合格技术水准。但Compose因为选择了直接魔改Kotlin编译器,所以在编译期优化上大有挖掘之处。Compose团队主要举了常量参数的消除作为例子。
Compose理论上应该记录下所有@Composable函数的参数,从而进行Diff。但和Vue3.0的思路类似,如果开发者传进来一个常量,很明显是没必要记录和Diff的。Compose编译插件会自动分析每一处函数调用,产生一个bit flag,提示runtime跳过某些常量参数。例如下面这个例子中出现了大量常量(实际编译产物中bit flag的逻辑和官方演示并不一致,望周知)
@Composable fun Google(number: Int) {
Address(
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
}
会被编译为类似
fun Google(
$composer: Composer,
$static: Int,
number: Int
) {
//此处应有Diff代码,略过
Address(
$composer,
0b11110 or ($static and 0b1),
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
}
Google函数和Address函数均多了一个$static的bit flag参数。Address函数的$static参数0b11110在运行时会导致后四个参数跳过保存和 Diff步骤。这实现了常量参数的消除。
同样的,Google函数的number参数未经修改便直接被传入了Address函数,如果Google处的number是常量,那么Address处应当也是,而不是因为number=number的写法就被当作变量。于是0b11110后一个or运算实现了常量属性的传递。
对Compose设计的思考
目前Compose的官方资料仍然较为缺乏,因此很难知道Compose除此之外的优化设计以及runtime具体调度机制。但总体来说,我认为
- Compose的编译期优化潜力较为巨大,在未来完全有实现SwiftUI所有编译期优化的潜力,尽管没有使用类型系统可能会导致某些实现更为困难。
- Compose对于原版Kotlin的强势侵入是其得以实现设计目标的重要原因。但也是一个隐患,Compose对语义的入侵过深,我们可以看看Compose的编译器可能会干什么事情
- 对每个树的节点,按照源代码位置,生成一个唯一的int型ID
- 插入start和group来表明节点的边界
- 收集向函数传递的参数,参数的性质
- 根据收集的信息指导一个指令机的工作,那个指令机工作在一个无类型的纸带上
这个已经可以算作在Kotlin/JVM上重新发明了一个虚拟机了。结构化的执行流程,内存,ABI,call site,复杂的调度策略都有了,我觉得就差来个人来证明能跑操作系统了。在已经因为DSL特性高度特化的Kotlin语言上继续发明新虚拟机,总归是有点奇怪的事情。与此对比,SwiftUI对语言的入侵很少而且是隐式的。
- 作为未来取代Android SDK的候选者,有强烈的风格取向,opinionated。为了实现对树状渲染结构“通用”的描述,Compose捆绑了一整套非常新的解决方案,从Positional Memoization,到安卓上第xxxxxxx个响应式数据解决方案@State(目前仍然缺乏资料以证明其通用性)。好是好,但是Angular前车之鉴在那里。公平的来说,SwiftUI也是强烈的风格取向,但SwiftUI在苹果生态中的地位个人觉得谷歌没法在Compose上复刻。而且加上强势侵入原语言语义,一旦要调整估计就要大调整。
- Compose大量功能处于编译器层,导致这些功能其实是没办法灵活调节的。Flutter我觉得官方的xxx不好还可以自己重写一个发布出去,才有了一堆群魔乱舞的东西,engine虽大但除了engine以外都可以自己写。Compose感觉很容易就会碰到编译器层。
- Compose由于基于编译器,很多的优化都是类似于编译器过一个pass的模式来的,尤其是Diff和常量消除那些地方,比较细碎,不容易归档解释,给人一种“想到哪里写到哪里”的感觉,目前官方的文档就有很多这种问题。
- 总之,非常期待以后真正理想的“通用”编程语言配上先进的前端框架。也许就是swift加上MPS。
最后
为了让大家更好的去学习和提升自己,我和几位大佬一起收录整理的 Flutter进阶资料以及Android学习PDF+架构视频+面试文档+源码笔记 ,并且还有 高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料……
这些都是我闲暇时还会反复翻阅的精品资料。可以有效的帮助大家掌握知识、理解原理。当然你也可以拿去查漏补缺,提升自身的竞争力。
如果你有需要的话,可以前往 GitHub 自行查阅。