毕业设计题目是铁道部的票务系统设计与实现。毕竟本科毕设要求很简单,但还是想查阅资料尽量以学习为目的提升自己。自己也快写了一大半了,代码上很多地方还没有做整合,这里先简单回顾一下。
12306的数据库设计难点一在于如何动态计算余票。一个线路上有多个站点所以票的卖法有很多种,全国站点几万个,每两个站点之间就有n个下单记录(n为座位暂时不考虑日期)这样首先余票表数据量庞大,并且路线为abcdef的路段,卖出去cd一张票,那么原本包含有cd路段的所有余票都会改变。另一个难点在于对于余票动态变化的情况下,针对春运情况,每两个站点之间的票都被很多人抢,相当于全国几万个站点每两个站点就组合成一个“秒杀”商品,这比淘宝几十个几百个秒杀商品情况复杂很多倍,如何设计余票库的秒杀系统。
这里简单记录一下针对动态余票库、卖票、缓存、春运等问题的解决方式。以及整体设计。
目录:
1.需求方面
2.数据库方面
3.系统架构方面
4.系统架构实现方面
5.系统性能优化方面
<!----分割线---->
1.需求方面
需求方面划分为功能性需求和非功能需求。从分析的角度记录如下:
(1)注册、登录验证
最起码的一个点了,当然由于包含车次信息、余票、订单、短信通知、购票流程等多个大需求,所以目前划分了四个子系统。单点登录也是必须的。
(2)车次信息查询
输入始发站找到对应车次信息。
(3)余票、价格信息查询
输入始发站和终点站,对沿途站点计算价格总和。
(4)下单流程
终端-->查询余票-->选择车次-->确认座位-->选择张数-->支付-->出票
用户锁定订单,30分钟内支付然后更新余票库和订单库。
(5)支付系统
刚开始也看了下银行卡支付,要依赖于专门做支付的平台的sdk,而且涉及到money就必须考虑很多安全问题比如要反复相互确认秘钥啊这些很麻烦。后来了解了下微信扫码支付,发现代码量特别少接入起来比较简单就拟选择扫码支付。
(6)非功能需求
这部分需求就包含许多方面了,比如数据库如何高可用以及高并发,服务接口如何实现高可用高并发。某些场景(类似于秒杀)怎么保证高度数据一致性比如用户锁定一张票付款后是否真的能买到,是否会因为数据一致性问题造成多用户锁定了同一张票。还包括如何优化,是否需要缓存,数据库是否需要分表分库来支持高压力,如何防止黄牛软件而已刷票(我不知道这种刷票软件实现方式,简单理解为一直发送请求然后利用身份信息去锁定票,类比成恶意的大量请求攻击好了)。突然联想到12306官网本身也支持刷票功能,就是点击余票监控,然后会自动不断发送查询请求,查到余票立即提醒用户,想来12306花十几亿做到这样也挺不错了却还是被用户喷。暂时只想到这些。
2.数据库方面
思路总结:
(a)路线区间:一张票的本质是某个车次的某一段区间(一条线段),这个区间包含了若干个站点。然后我们还发现,只要区间不重叠,那座位就不会发生竞争,可以被回收利用,也就是说,可以同时预先出售。
(b)是否能出票:根据订单信息,拿到出发地和目的地,然后获取这段区间里的所有的原子区间。然后尝试将每个原子区间的可用票数减1,如果所有的原子区间都够减,则购票成功;否则购票失败,提示用户该票已经卖完了
(c)退票:把这个票的所有原子区间的可用票数加1
(d)挑选座位:已经出售的票的的本质是区间和座位的对应关系。先根据区间去判断是否有可用的座位;如果有可用座位,则再通过算法去选择一个可用的座位;
数据库实体:
(a)旅客信息:假设都是实名的,至少有三个重要信息 姓名,身份证,手机号
(b) 车次信息:车次,起始站,终点站,类型,发车时间,到达时间
(c)车次停靠信息:车次,停靠站,达到时间,停靠时间
(d) 余票信息:车次,起始站,终点站,发车日期,剩余票
(e)车票信息:车次,起始站,终点站,发车日期,购票日期,旅客姓名,身份证,手机号,状态,购票渠道,支付日期
(f)支付信息:金额,支付日期,支付银行,支付金额,支付方式
(g) 短信(邮件)信息:车票信息,验证码,短信内容
车次库:
车次库仅仅做路线查询功能,请求走到这里时还没有去访问余票信息。整个系统是从用户输入两个站点开始的,从站点查询能够直达的车次(忽略转车问题以及类似于搜狗地图那种最优路线,因为那会涉及一个最优化的数学模型),再根据车次去查找这两个站点的余票库。
假如以车次为实体,站点为字段,使用结构化数据库来维护比较麻烦,并且想要通过两个站点来查询车次也比较麻烦。所以我使用nosql来实现。
把一个车次看成一条链表,节点就是每个站点的话就很容易实现,首先找到包含站点a的车次,再从这些车次里面找到包含b的车次就可以最终确定车次信息。但是这样只能确定由车次到站点的映射(正向索引),如果想实现由站点到车次的映射(反向索引),就需要以站点作为键,以会经过这个站点的车次的集合作为值。这两种方式其实就是键的数量的差别,虽然站点个数是远远多于车次个数的,但是想想全国站点应该也就几万个吧(应该吧),从几万个键里面找几个键基于内存数据库来说是没什么压力的,思路来源于《redis in action》的第七章。
余票库:
(a)出票方式1
通过站点得到车次,再结合两个站点才能查到余票。车次也是余票实体的一个影响因素,毕竟同一段路不同车次可能跑过的路程不一样长,计算得到的价格也不一样。不过把两个站点加上车次等信息构成一条记录的话,就遇到了参考链接中的动态库存问题,如果把两个站点比作一个商品,首先余票表的数据量就会很多(几万个站点,每两个就要有一条记录),并且在每一个这样的商品后面需要带上“库存”这样一个字段,某个商品的“库存减少”会造成其他很多商品的“库存”减少。比如abcdef之间,某人买了cd之间的票,那么以cd为分割线相关的所有票数量都会改变,这样的话每一个下单操作会触发n条update语句,并且都可能会经历“春运、秒杀”这样的场景,同时事物隔离级别还必须选择性能最低的串行化来保证数据强一致性。
(b)出票方式2
参考链接上面作者以把路线上面每一段看成一个原子区间,可以“原子区间+车次+剩余座位数”构造一个余票表,在通过上一步拿到车次信息后,之后获取用户想要买的路线上面的所有原子区间,在对所有区间都能够执行减1的操作情况下证明能够出票。和方法一一样一个订单也会触发很多个update语句。
其他库:
其他数据实体就比较简单,包括用户信息库、订单库、短信库等等。
余票的动态计算、查询:
假设一共有100座位,初始时某一车次上所有原子区间剩余座位数都为100,再利用上面出票方式2对所有区间的票做动态计算,随着用户一张一张地买票,直到所有原子区间的剩余座位数都为0。
解决了余票计算问题,剩下就是余票的查询问题。到底每个区间的余票怎么衡量呢?其实利用上面原子区间的方式就可以简单实现:任意一个区间假设包含了5个原子区间,他们分别的剩余座位数为3,4,51,3,那么其中的最小值就是这条路线的余票数
这样既能保证余票的正确显示,也能保证余票不会同一张票卖给两个人。
3.系统架构方面
基本架构:
采用最简单的tomcat集群架构,所有tomcat用来响应html或者jsp同时部署服务消费者接口只负责调用其他接口或者查询缓存不处理具体业务逻辑,所有不需要tomcat的后台接口用来处理具体的业务逻辑包括查询数据库或者其他计算,这样在消费者端能从缓存中拿到数据则不需要远程调用服务接口,这样可以降低服务提供者负载。
所有外部请求通过web代理对tomcat集群做负载均衡,同时web代理需要提供某些静态资源的缓存功能,这样对静态资源的请求就不必发送到系统内部。
数据库肯定要读写分离,因为读写大概各占80%、20%。由于订单、余票等都有日期时间字段,我感觉实际中可能利用日期或者其他依据做了分表分库这里就忽略,因为数据库中间件我并不了解。
缓存可以选择多种方式,一级缓存、二级缓存等等,这里直接使用一级缓存。由于缓存设计本身很复杂包括失效时间、更新时间、缓存策略、命中率等等,这里简单地使用hash来保存每个原子区间,其中hash名为原子区间id+后缀,键为车次、这一段路价格、剩余票数。这样就相当于缓存了所有的余票信息。
邮件通知任务、下单任务等分别单独部署应用,利用rabbitmq通信。
秒杀和春运场景:
秒杀指的是在开启的一瞬间融入大量请求,但是只有有限个请求能够真正秒杀成功,对应于商品的下单成功操作。首先秒杀系统设计原理很简单,就是如何让系统在短时间内处理超量请求,并且每个请求的目标都是去进行数据库操作,并且高度保持数据一致性,当然限于硬盘读取速度瓶颈,只能使用缓存来代替,最后获取到所有秒杀成功的用户id使用异步批量更新数据库。借用redis、zk都能够很好的实现。
可是春运场景实现以来就很麻烦,首先因为余票是动态计算的,所以缓存也需要动态更新,并且商品的秒杀仅仅针对有限个商品,而春运场景下每一张票都是秒杀,因为一个区间上面的票有n种卖法,每一种卖法都被争抢。
由于采用了原子区间的方式,余票信息的缓存也比较方便:使用hash来保存每个原子区间,其中hash名为原子区间id+后缀,键为车次、这一段路价格、剩余票数。这样就相当于缓存了所有的余票信息。这样每卖出去一张票,这张票上面的原子区间的hash上面的剩余票数减1,就将硬盘数据库操作全部移植到了内存中。
解决了余票缓存的买票问题,接下来就是解决秒杀问题。秒杀的应对主要是削峰,12306的变态验证码就是为了拖延时间然后拦截掉了一大部分流量,还可以使用消息队列,处理不完的请求封装成任务放到队列里面防止业务系统被压垮。我这里就使用的这两种方式:直接忽略一部分下单请求、使用消息队列处理请求。我这里将出票操作(redis集群写操作)单独部署为一个后台项目,用来接收rabbitmq的下单消息,随机忽略一些消息。既然使用rabbitmq将下单操作分离出去,当然要借用其并行计算的优势,所有使用了1生产者n消费者的方式(毕竟承担了整个系统的写操作肯定会是瓶颈所在),这样可以进行预估,如果3个消费者承受不住就上5个。
用户一次完整的查询余票,下单操作:
请求通过web代理随机到了tomcat集群某一个结点里,如果是查询余票操作,于是远程调用查询余票的接口(由于是多读少写,查询余票接口需要集群部署)。如果是下单操作,远程调用下单接口(这个接口不直接下单,而是向rabbitmq队列发送消息),下单应用接收消息然后挨个处理消息。下单接口并非一定发送消息,可以根据时间段自动判断要低要不要发送消息以此随机忽略请求。
架构图:
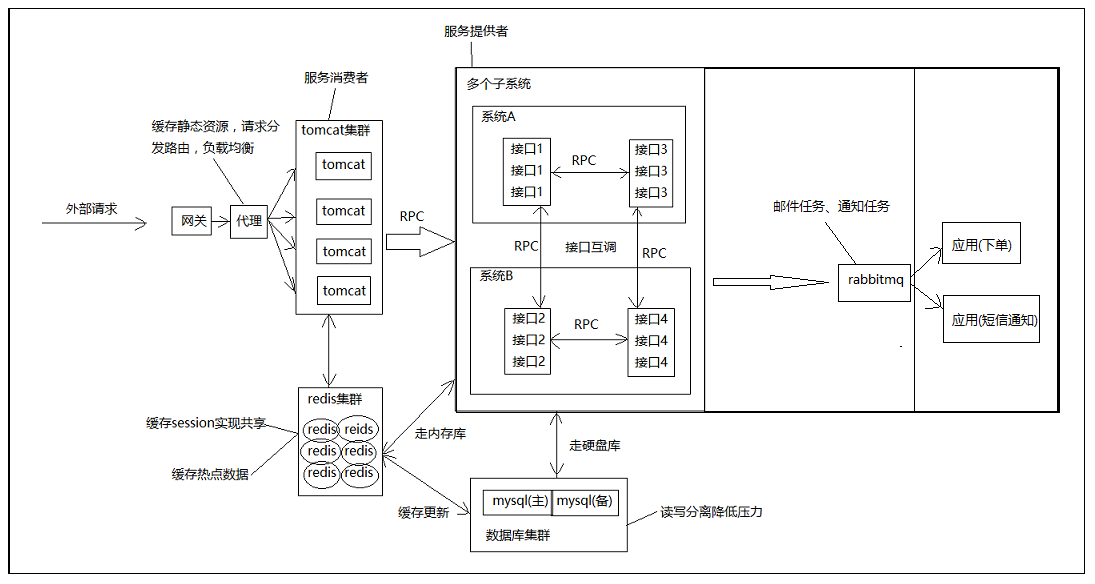
(电脑自带画板画得很丑)
4.系统架构实现方面
(f)服务接口利用dubbo功能实现容错、降级、集群负载均衡。
5.系统性能优化方面
(b)tomcat优化(线程池参数、连接参数、aio、jvm参数)。
(c)监控各个tomcat、服务接口等节点jvm和机器cpu,预估瓶颈对集群动态横向扩展。
(d)数据库索引、sql优化(这方面不懂)