引入 MQ 消息中间件最直接的目的是:做系统解耦合流量控制,追其根源还是为了解决互联网系统的高可用和高性能问题。
系统解耦:用 MQ 消息队列,可以隔离系统上下游环境变化带来的不稳定因素,比如京豆服务的系统需求无论如何变化,交易服务不用做任何改变,即使当京豆服务出现故障,主交易流程也可以将京豆服务降级,实现交易服务和京豆服务的解耦,做到了系统的高可用。
流量控制:遇到秒杀等流量突增的场景,通过 MQ 还可以实现流量的“削峰填谷”的作用,可以根据下游的处理能力自动调节流量。
不过引入 MQ 虽然实现了系统解耦和流量控制,也会带来其他问题。
引入MQ消息中间件实现系统解耦,会影响系统之间数据传输的一致性。
而引入MQ消息中间件解决流量控制,会使消费端处理能力不足从而导致消息积压。
一、如何确保消息不丢失
首先我们来看下哪些环节可能消息会丢失。
一条消息从生产到消费,整个过程分为三个阶段,分别为消息生产阶段,消息队列,消息消费阶段。
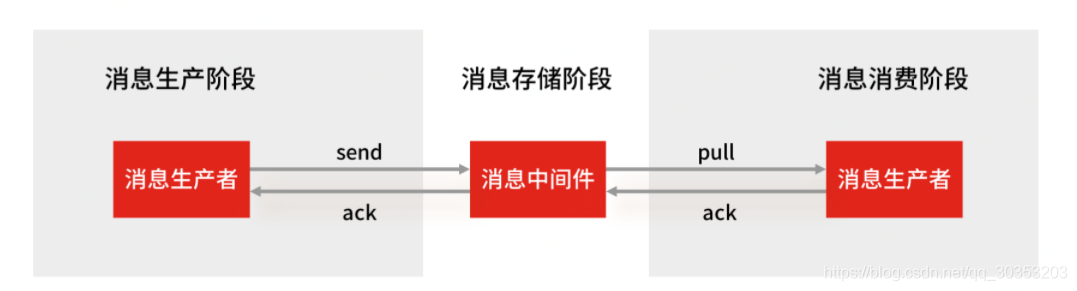
消息生产阶段: 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 MQ Broker 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,这个阶段是不会出现消息丢失的。
消息存储阶段: 这个阶段一般会直接交给 MQ 消息中间件来保证,它的原理,比如 Broker 会做副本,保证一条消息至少同步两个节点再返回 ack。
消息消费阶段: 消费端从 Broker 上拉取消息,只要消费端在收到消息后,不立即发送消费确认给 Broker,而是等到执行完业务逻辑后,再发送消费确认,也能保证消息的不丢失。
以上就是整MQ的生产消费过程,看似不会出现问题,但是如果是在分布式系统中,就不能保证MQ是不是丢失你的消息,消费者是否消费了你的消息。
为了检查MQ是否会丢失,这个问题,可以采取一种方式,在消息生产端,给每一个发出的消息指定一个全局唯一ID,或者附加一个连续递增的版本号,然后在消费端做对应的版本校验。具体实现方式可以采用拦截器机制。在生产端发送消息之前,通过拦截器将消息版本号注入消息中(版本号可以采用连续递增的 ID 生成,也可以通过分布式全局唯一 ID生成)。然后在消费端收到消息后,再通过拦截器检测版本号的连续性或消费状态,这样实现的好处是消息检测的代码不会侵入到业务代码中,可以通过单独的任务来定位丢失的消息,做进一步的排查。
二、如何保证消息被重复消费呢
换句话说就是如何解决消费端幂等性的问题(幂等性,就是一条命令,任意多次执行所产生的影响均与一次执行的影响相同),只要消费端具备幂等性,那么就可以避免重复消费的问题。
最简单的实现方案,就是在数据库中建一张消息日志表, 这个表有两个字段:消息 ID 和消息执行状态。这样,我们消费消息的逻辑可以变为:在消息日志表中增加一条消息记录,然后再根据消息记录,异步操作更新用户信息。因为我们每次都会在插入之前检查是否消息已存在,所以就不会出现一条消息被执行多次的情况,这样就实现了一个幂等的操作。当然,基于这个思路,不仅可以使用关系型数据库,也可以通过 Redis 来代替数据库实现唯一约束的方案。
对于解决消息丢失和消息重复消费,都有个前提是创建一个全局的ID。
创建全局的ID的方式有数据库自增主键,UUID、Redis、Twitter-Snowflake 算法。总结如下:

三、如何解决消息积压问题
如果出现消息积压问题,必然是一个消费端的性能问题。如果出现这个情况,首先那要临时扩容,增加消费端的数量,与此同时,降级一些非可信的业务。其次然后通过监控、日志等分析消费端的代码是否出现了问题,优化消费端的业务逻辑。最后如果消费端的处理能力不足,可以通过水平扩容来提供消费端的并发处理能力。需要注意的是,在扩容消费者的实例数的同时,必须同步扩容主题Topic的分区数量,确保消费者的实例数和分区数相等。