布隆过滤器应用场景有很多, 搜索框: 如用户按特点关键词搜索, 避免缓存穿透等等
不良用户利用搜索框或者涉及到缓存的应用场景,拿一些乱七八糟的key来查询,这时候redis和数据库这种值都是不存在的,人家每次拿的key也不一样,你就算缓存了也没用,(缓存没有的数据就会去查数据库), 这时候数据库的压力是相当大, 怎么办呢,这时候我们今天的主角布隆过滤器就登场了。。
布隆过滤器的概念这里就不赘述了
首先引入一道面试题: 如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在
很简单嘛, 把所有的数据都添加到数据结构里去, 如list或map等, get判断不就完了嘛. emmm... 面试官可能会问这么简单的问题吗?
数据量小的话, 完全可以的, 那么上亿上百亿呢?
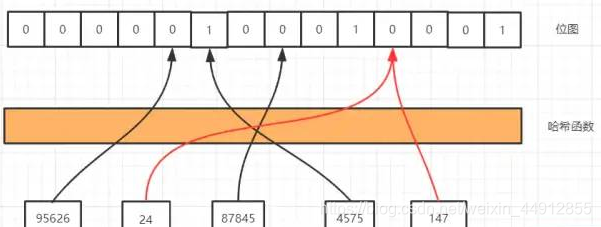
引入一个节省空间的数据结构: 位图,他是一个有序的数组,只有两个值,0 和 1。0代表不存在,1代表存在。
如何确定某一元素在哪个位置是0还是1, 怎么解决这个问题呢,那就要用到哈希函数,用哈希函数有两个好处,第一是哈希函数无论输入值的长度是多少,得到的输出值长度是固定的,第二是他的分布是均匀的(map中定义元素的位置也是这种形式),如果全挤的一块去那还怎么区分,比如MD5、SHA-1这些就是常见的哈希算法。
我们通过哈希函数计算以后就可以到相应的位置去找是否存在了,我们看红色的线,24和147经过哈希函数得到的哈希值是一样的,我们把这种情况叫做哈希冲突或者哈希碰撞。哈希碰撞是不可避免的,我们能做的就是降低哈希碰撞的概率,第一种是可以扩大维数组的长度或者说位图容量,因为我们的函数是分布均匀的,所以位图容量越大,在同一个位置发生哈希碰撞的概率就越小。但是越大的位图容量,意味着越多的内存消耗,所以我们想想能不能通过其他的方式来解决,第二种方式就是经过多几个哈希函数的计算,你想啊,24和147现在经过一次计算就碰撞了,那我经过5次,10次,100次计算还能碰撞的话那真的是缘分了,你们可以在一起了,但也不是越多次哈希函数计算越好,因为这样很快就会填满位图,而且计算也是需要消耗时间,所以我们需要在时间和空间上寻求一个平衡。。
为什么会使用它
相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的.
Java代码中使用布隆过滤器 google为我们已经提供了相关家暴
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>简单模拟
private static int size = 1000000; // 元素的个数
private static double fpp = 0.05; //默认误判率 不设置默认是0.03
private static BloomFilter<String> BF = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), size, fpp);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
BF.put("dugt" + i);
}
if (!BF.mightContain("dugt8866")) {
System.out.println("没有");
return; // 没有直接返回
}
System.out.println("有");
//todo 业务逻辑
}
运行结果
从元素的角度来说:
如果元素实际存在,布隆过滤器一定判断存在
如果元素实际不存在,布隆过滤器可能判断存在 (这点误判 相比大量的无意垃圾请求 可以容忍的 )