2020/11/10 [email protected]
文章目录
一、Federation(联邦)
1.1背景(HDFS的两个层面)
命名空间:
- 命名空间:由目录,文件和块组成。
- 它支持所有与名称空间相关的文件系统操作,例如创建,删除,修改和列出文件和目录
块存储服务:
-
Block管理:
- 提供datanode集群的注册和定期的心跳检查,处理block的报告并掌握block的位置;
- 支持block的相关操作,如增删改查和得到block的位置管理副本位置,管理副本的复制和删除
-
存储:本地系统的datanodes提供,允许读写。
↑before:整个集群使用单个NameNode,共用一个nameSpace
↓then:向HDFS添加多个NameNode,nameSpace
1.2联邦的概念
多nameNode&nameSpace:
-
多个NameNode相互独立,使得HDFS的命名服务能够水平扩展,这些NN分别进行各自命名空间和块的管理,不需要彼此协调
-
多个NameSpace管理属于自己的一组块,这些属于同一个命名空间的块组成一个块池
-
DataNode
-
被所有NameNode使用,作为通用的数据块存储设备
-
向联邦中每一个NameNode注册
-
向NameNode发送心跳机制以及block报告
-
处理NameNode的命令
-
每个datanode为多个块池提供存储
-
Block池:
-
每个块池存储同一个nameSpace里的所有文件的块集合
-
被独立管理,互不影响
-
块存储在不同的DataNode中的
→允许为新的block产生Block ID并不会需要其他的namespace。一个NameNode出问题也不会影响datanode为集群中的其他NameNode服务。
- NameSpace与块池绑定一起称为NameSpaceVolume,作为一个独立的单位进行管理
- 当nameNode/nameSpace被删除时,对应的block池也被删除
→当集群升级时,一个NameSpaceVolume是一个升级单元
集群ID:
- ClusterID用来标识以及识别集群中的所有节点,格式化NameNode时,Cluster自动生成。
- 该ClusterID 用于将其他NameNode格式化为集群。
1.3联邦的优点
扩展性:
- l联邦使得集群的NameSpace水平伸缩扩展
- 大型部署、使用大量小文件的部署可以通过向集群中添加更多的NameNode完成效率以及nameSpace的扩展
性能:
- HDFS文件系统的吞吐量不再受单一NameNode的限制,向集群中添加更多的NameNode会提高文件读写的吞吐量
隔离:
-
单个NameNode存在多用户环境不提供隔离机制,例如实验程序导致NameNode变慢影响生产环境
-
通过多NameNode可以将不同类别的应用程序和用户隔离到不同的nameSpace
1.4联邦的配置
- 添加一个新的NameNode到一个既存的HDFS集群
- 添加配置参数dfs.nameservices到配置文件且使用NameServiceID 作为后缀更新配置文件(hdfs-site.xml)。
- 将配置文件同步到集群当中的所有节点。
- 格式化并启动新增的Namenode节点,注意使用clusterid(尤其在大集群新增多个namenode)。
- 启动新的 Secondary/Backup节点。
- 刷新datanode获取新添加的namenode。
- 使用jps与HDFS UI检查配置是否成功。



参考资料
https://blog.csdn.net/weixin_42348333/article/details/82193852#3.1%20Viewfs%E9%85%8D%E7%BD%AE
http://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-hdfs/Federation.html
2020/11/3
二、ViewFs
2.1背景
联邦前:
一个集群拥有一个namenode,它为集群提供一个单一的文件系统namespace。假设有很多集群,那么它们的namespace是彼此独立的。更重要的是,物理存储也没有在集群之间进行共享
联邦后:
假设有多个集群,每个集群又有一个或多个namenode。每个namenode有自己的namespace。一个namenode只会属于一个集群,同一个集群中的namenode共享该集群的物理存储(datanodes)。同时不同集群的namespace依旧保持其独立性
联邦-ViewFs:
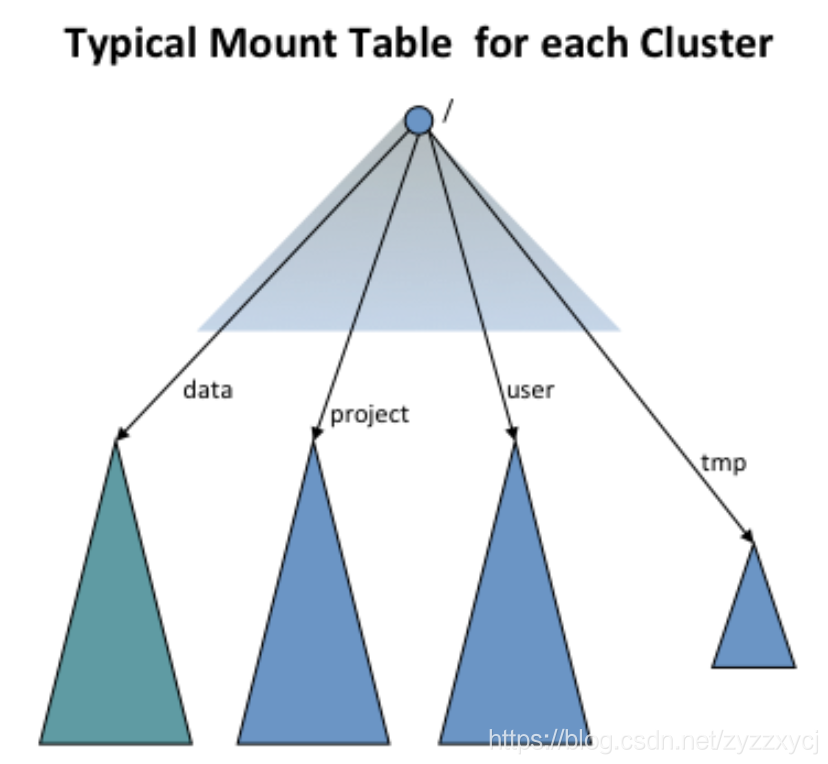
使用ViewFs得到集群的全局namespace,为每个集群建立独立的集群nameSpace图
蓝色的点表示客户去访问的namespace,而下面四个为实际去访问的namespace。
2.2ViewFs配置
-
关闭集群,配置core-site.xml,新建mountTable.xml
修改core-site.xml 其中my-cluster可以自己命名ViewFs名称(安装表)
fs.default.name viewfs://my-cluster
-
装载表的装载点在标准Hadoop配置文件中指定。viewfs的所有安装表配置条目均以fs.viewfs.mounttable为前缀
-
使用链接标记指定链接其他文件系统的安装点。建议使挂载点名称与链接的文件系统目标位置中的挂载点名称相同。
-
对于未在安装表中配置的所有名称空间,我们可以通过
linkFallback将它们回退到默认文件系统
新文件中的link./output为在ViewFs视图中的名称
hdfs://node101:8020/input为视图名称实际对应的文件夹名称fs.viewfs.mounttable.my-cluster.link./output hdfs://node101:8020/output fs.viewfs.mounttable.my-cluster.link./input hdfs://node103:8020/input fs.viewfs.mounttable.my-cluster.linkFallback hdfs://node103:8020/home
-
-
配置文件同步
-
启动集群,在不同节点上测试
hadoop fs -ls viewfs://my-cluster/
hadoop fs -ls /
hadoop fs -put file /input

建议使用简单路径代替全路径 例如
hadoop fs -put file1 /input/ 实际执行的是hadoop fs -put file1 hdfs://node103:8020/input/
hadoop fs -put file2 /output/ 实际执行的是hadoop fs -put file2 hdfs://node101:8020/output/
2.3路径使用的最佳实践为简写路径
- /input 等价于viewfs:my-cluster/input
- viewfs://my-cluster/input 建议直接使用/input
- viewfs://you-cluster/input 其他集群的input
实现从my-cluster拷贝文件到you-Cluster
distcp viewfs://my-cluster/input/apple viewfs://you-cluster/input/
- 通过WebHDFS和HFTP协议这两种文件系统对文件进行访问
viewfs://my-cluster/input/apple
viewfs://you-cluster/inputlapple
2.4不同命名空间建的路径重命名
在NameNode集群中不能随意的重命名hdfs文件或者目录,但是在联邦模式下可以执行如下的操作
rename /input/apple /output/apple
如果/input 和 /output属于一个集群不同的NameNode,不能执行如上操作
2.5常见问题
- 从非联邦世界迁移到联邦世界,把namenode挂载不同的卷上如何实现
不可以,但可以使用默认文件系统的相对路径的特性,把hdfs://node101:8020/foo/bar改为 viewfs://my-cluster/foo/bar.
-
集群内如果从一个namenode迁移文件到另外一个namenode会发生什么.
-
跨namenode之间的文件转义可能是为了解决存储问题,这样操作可以避免程序被打断
场景1:/input 和 /outherinput属于同一个namenode管理,为了解决存储问题,我们需要把他们转移出去,说实在的,操作将为/input和/outherinput创建单独的挂载点。
在更改/input和/outherinput的挂载之前,会指向相同的namenode,比如namenodeContainingInput,操作将更新挂载表,
以便将挂载点分别更改为namenodeContaingInput和namenodeContainingOutherInput
场景2:目前所有的项目都在一个namenode里,我们想要更多的namenode,视图文件系统向 /input 和 /otherinput允许挂载表更新到对应的namenode里。
- 挂载表是否存在每个core-site.xml文件或者单独的文件里?
挂载表需要单独存在在一个文件中,core-site.xml使用xincluding指向这个文件,尽管每个机器可以在本地保留一份这个文件,但是还是建议使用http的方式从配置中心拉取S
- 每个集群的挂载表定义一定要一致吗?
是的,因为这样的话跨集群间数据转移就可以正常进行,比如distcp
- 如果操作可能随着时间的推移而更改挂载表,那么挂载表实际读取的时间是什么时候?
当job被提交到集群上的时候挂载表配置会被读取,core-site.xml中的XInclude在Job提交的时候也会读到,这意味着,如果挂载表被更改,
则需要重新提交作业。由于这个原因,我们希望实现合并挂载,这将大大减少更改挂载表的需要。此外,我们希望将来通过作业开始时初始化的另一种机制读取挂载表。
参考资料
https://blog.csdn.net/guofei_ok/article/details/86138451
http://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-hdfs/ViewFs.html#How_The_Clusters_Look
实现合并挂载,这将大大减少更改挂载表的需要。此外,我们希望将来通过作业开始时初始化的另一种机制读取挂载表。
参考资料
https://blog.csdn.net/guofei_ok/article/details/86138451
http://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-hdfs/ViewFs.html#How_The_Clusters_Look