参考书籍:《Python数据分析与挖掘实战》
1.探索性数据分析
首先,也是很重要的一点,对数据本身的涵义认知是非常重要的,一定要基于数据本身的特性进行初步分析。(包括常识)
数据质量分析

异常值分析(离群点分析)常用方法:最值、(如果符合正态分布,利用3σ原则)、箱型图。
df.head()预览数据,默认5行
df.info()索引,数据类型和内存信息,例如用来查看缺失值情况。
df.describe() 数值列的汇总统计信息
数据特征分析
对数据进行质量分析后,接下来可通过绘制图表、计算某些特征量等手段进行数据的特征分析,包括分布分析、对比分析、统计量分析、贡献度分析、相对性分析等等
-
分布分析:

-
对比分析:

-
统计量分析:
利用统计指标,常从集中趋势和离中趋势两个方面进行分析.
均值:


均值法受极端数值影响较大,可以考虑截断极值或改用中位数。众数:一般用于离散型变量而非连续性变量。
离中趋势包括极差、标准差、变异系数、四分位数间距。

方差分析数据的稳定性和波动性的优点是:方差的计算结果将数据的波动性数值放大,比极差和标准差更为细致、准确、明显。当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大,或者数据量纲的不同,直接使用标准差来进行比较不合适,此时就应当消除测量尺度和量纲的影响,而变异系数可以做到这一点,它是原始数据标准差与原始数据平均数的比(一个无量纲量)。
变异系数的缺陷:当平均值接近于0的时候,微小的扰动也会对变异系数产生巨大影响,因此造成精确度不足;无法发展出类似于均值的置信区间的工具。
*

-
贡献度分析:

-
相关性分析:
1.直接绘制散点图(两个变量间)
2.绘制散点图矩阵(多个变量间)
3.计算相关系数

两种理解:


https://www.zhihu.com/question/19734616(2)


df.corr() 计算列之间的相关系数,得到一个矩阵
sns.heatmap 热力图
pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依 照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
其他笔记
df[name].value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
sns.distplot 灵活绘制单变量观测值分布图
bin参数指定bin(箱子)的个数(也就是总共有几条条状图)
2.特征工程
特征工程指的是最大限度地从原始数据中提取特征,以供机器学习算法和模型使用。
引用:“合适的特征才能真正暴露出数据的特性,不然再好的算法也无能无力。”

数据清洗
-
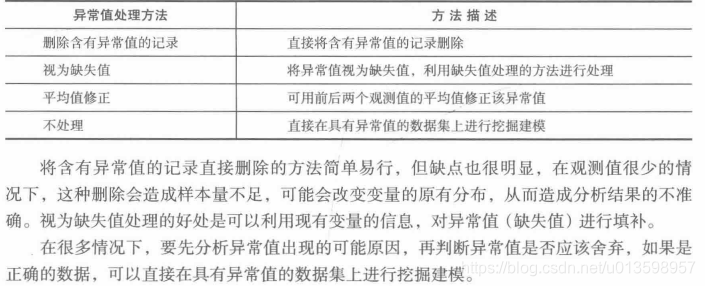
缺失值处理:

插值方法有拉格朗日插值法、牛顿插值法等。 -
异常值处理:
数据集成

(划重点:不同数据源的合并)
- 实体识别:常见问题有同名异义、异名同义、单位不统一。
- 多余属性识别:同一属性多次出现、同一属性命名不一致导致重复。
数据变换
主要是对数据进行规范化处理,转换成“适当”的形式,以适用于挖掘任务及算法的需要。
-
简单的函数变换:

-
规范化:

1.最大-最小规范化(离差标准化):是对原始数据的线性变换,将数值映射到[0,1]。

2.零-均值规范化(属于标准化):


3.小数定标规范化:


-
连续属性离散化:

常用方法:等宽法、等频法、聚类。 -
属性构造:
在数据挖掘的过程中,为了提取更有用的信息,挖掘更深层次的模式,提高挖掘结果的精度,可以利用已有的属性集构造新的属性,并加入到现有的属性集合中。
-
*小波变换:

数据规约

-
属性规约:

(划重点:寻找出最小的属性子集并尽可能接近原来的概率分布)
 *
*

-
数值规约:

1.直方图
2.聚类

3.抽样用比原始数据小得多的随机样本(子集)表示原始数据集。常用方法:有放回、无放回、聚类抽样、分层抽样。
4.参数回归
其中,简单线性模型常用最小二乘法。而对数线性模型一般用来近似离散度多维概率分布,可用于维规约和数据光滑。
其他笔记
SciPy函数库在NumPy库的基础上增加了众多的数学、科学以及工程计算中常用的库函数。例如线性代数、常微分方程数值求解、信号处理、图像处理、稀疏矩阵等。
python的scipy简介(以NumPy为基础)
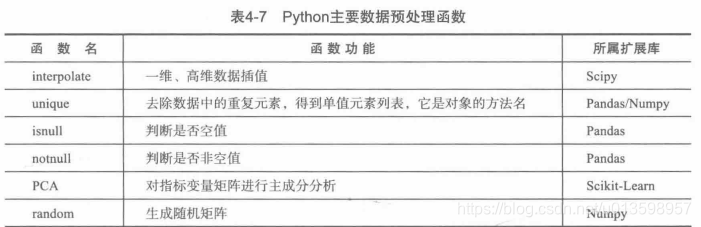

fillna表示数据填充的方法。
不只是简单的对缺失值进行了补全,还可以进行融合。重要的工作应该也包括特征的放大、组合。
文本型数据也需要处理,因为机器无法计算文本型数据。
对最终决定取值2种类型以上的特征,一般采用 one-hot code。
通过计算各个特征与标签的相关系数,进行特征选择,先求出相关性矩阵。(.corr)。根据各个特征与(要预测的)结果的相关系数大小(sort_values),选择几个特征作为模型的输入。