决策树基础
内容引自: 决策树, 机器学习之决策树
决策树是数据挖掘中一种最基本的分类与回归方法,与其他算法相比,决策树的原理浅显易懂,计算复杂度较小,而且输出结果易于理解,因此在实际工作中有着广泛的应用。

1.得到决策树的主要步骤
构造
根节点、中间节点、叶节点的确定选择。
剪枝
剪枝就是给决策树瘦身,这一步想实现的目标就是,不需要太多的判断,同样可以得到不错的结果。之所以这么做,是为了防止“过拟合”(Overfitting)现象的发生,从而提高最终决策树的泛化性能。
预剪枝:在决策树构造时就进行剪枝。方法是,在构造的过程中对节点进行评估,如果对某个节点进行划分,在验证集中不能带来准确性的提升,那么对这个节点进行划分就没有意义,这时就会把当前节点作为叶节点,不对其进行划分。

后剪枝:在生成决策树之后再进行剪枝。通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。如果剪掉这个节点子树,与保留该节点子树在分类准确性上差别不大,或者剪掉该节点子树,能在验证集中带来准确性的提升,那么就可以把该节点子树进行剪枝。方法是:用这个节点子树的叶子节点来替代该节点,类标记为这个节点子树中最频繁的那个类。

基本算法


尤其注意如何选择最优划分属性。 一般而言,随着划分的不断进行,我们希望决策树的分支节点所包含的样本尽可能的属于同一个类别。即节点的纯度越高。于是特征选择问题就转化为了纯度的定义问题。
2.纯度、信息熵与信息增益
纯度

构造决策树的时候,会基于纯度来构建。而经典的 “不纯度”的指标有三种,分别是信息增益(ID3 算法)、信息增益率(C4.5 算法)以及基尼指数(Cart 算法)。
信息熵
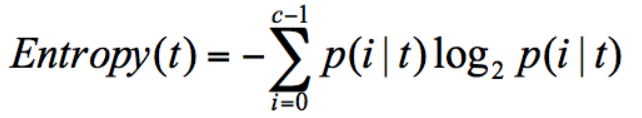
表示信息的不确定度。当不确定性越大时,它所包含的信息量也就越大,信息熵也就越高。
信息增益(ID3 算法)
信息增益指的就是划分可以带来纯度的提高,信息熵的下降。
计算公式:父亲节点的信息熵减去所有子节点的信息熵。
计算的过程中,我们会计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率,来计算这些子节点的信息熵。所以信息增益的公式可以表示为:
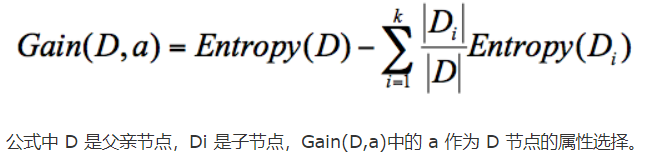
ID3 就是要将信息增益最大(纯度增加大)的节点作为父节点,这样可以得到纯度高的决策树。
正因如此,它也有缺陷:ID3 算法倾向于选择取值比较多的属性。 如果把“编号”作为一个属性(一般情况下不会这么做,这里只是举个例子),那么将会有等于编号数的子节点,“编号”将会被选为最优属性 。但实际上“编号”是无关属性的
3.在 ID3 算法上进行改进的 C4.5 算法
C4.5 采用信息增益率的方式来选择属性。信息增益率 = 信息增益 / 属性熵。

当属性有很多值的时候,相当于被划分成了许多份,虽然信息增益变大了,但是对于 C4.5 来说,属性熵也会变大,所以整体的信息增益率并不大。

ID3 构造决策树的时候,容易产生过拟合的情况。在 C4.5中,会在决策树构造之后采用悲观剪枝,这样可以提升决策树的泛化能力。
悲剪枝是后剪枝技术中的一种,通过递归估算每个内部节点的分类错误率,比较剪枝前后这个节点的分类错误率来决定是否对其进行剪枝。这种剪枝方法不再需要一个单独的测试数据集。
总的来看,4.5 在 IID3 的基础上,用信息增益率代替了信息增益,解决了噪声敏感的问题,并且可以对构造树进行剪枝、处理连续数值以及数值缺失等情况,但是由于 C4.5 需要对数据集进行多次扫描,算法效率相对较低。
4. CART 决策树
CART 决策树使用“基尼指数”来划分属性。

使用不同的误差准则,可以通过CART 算法构建模型树和回归树。
5.构造决策树 代码功能简述
1.计算信息熵
2.选择最优特征
3.划分数据集
4.对最终分类的多胜少决策
5.植树(花费时间较长,可以pickle)
6.分类器(传入所植的数和测试数据)
6.连续与缺失值
-
连续值:
1.二分法结合信息增益:

需要注意的是,与离散属性不同,若当前节点划分属性为连续属性,该属性还可作为其后代节点的划分属性。 -
缺失值:


7. 多变量决策树
单变量为轴:

(划关键:每个属性视为一个坐标轴,坐标轴上只能单属性的情况)
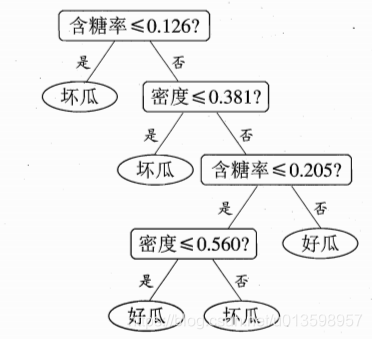
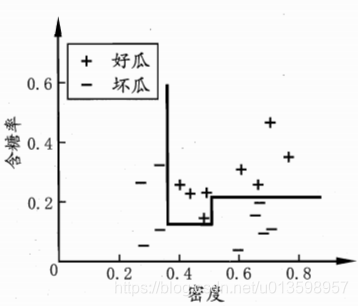
多变量:

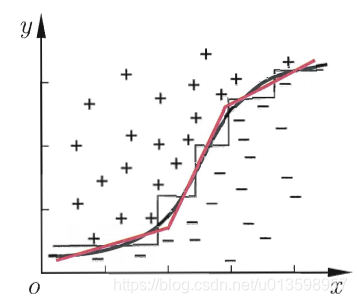
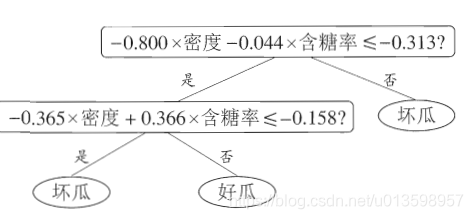
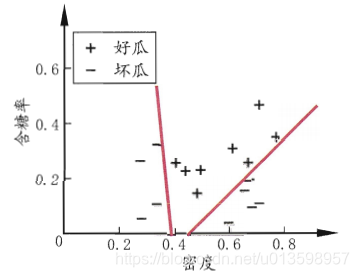
8.回归树
回归树总体流程类似于分类树,区别在于,回归树的每一个节点都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化平方误差。