转载的第一篇博客
1、ack是什么
ack 机制是storm整个技术体系中非常闪亮的一个创新点。
通过Ack机制,spout发送出去的每一条消息,都可以确定是被成功处理或失败处理, 从而可以让开发者采取动作。比如在Meta中,成功被处理,即可更新偏移量,当失败时,重复发送数据。
因此,通过Ack机制,很容易做到保证所有数据均被处理,一条都不漏。
另外需要注意的,当spout触发fail动作时,不会自动重发失败的tuple,需要spout自己重新获取数据,手动重新再发送一次
ack机制即, spout发送的每一条消息,
在规定的时间内,spout收到Acker的ack响应,即认为该tuple 被后续bolt成功处理
在规定的时间内,没有收到Acker的ack响应tuple,就触发fail动作,即认为该tuple处理失败,
或者收到Acker发送的fail响应tuple,也认为失败,触发fail动作
另外Ack机制还常用于限流作用: 为了避免spout发送数据太快,而bolt处理太慢,常常设置pending数,当spout有等于或超过pending数的tuple没有收到ack或fail响应时,跳过执行nextTuple, 从而限制spout发送数据。
通过conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, pending);设置spout pend数。.
2、如何使用Ack机制
spout 在发送数据的时候带上msgid
设置acker数至少大于0;Config.setNumAckers(conf, ackerParal);
在bolt中完成处理tuple时,执行OutputCollector.ack(tuple), 当失败处理时,执行OutputCollector.fail(tuple);
推荐使用IBasicBolt, 因为IBasicBolt 自动封装了OutputCollector.ack(tuple), 处理失败时,请抛出FailedException,则自动执行OutputCollector.fail(tuple)
3、如何关闭Ack机制
有2种途径
spout发送数据时不带上msgid
设置acker数等于0
4、基本实现
Storm 系统中有一组叫做”acker”的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。
acker任务保存了spout id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为”ack val”, 它是树中所有消息的随机id的异或计算结果。
<TaskId,<RootId,ackValue>>
Spoutid,<系统生成的id,ackValue>
Task-0,64bit,0
<TaskId,<RootId,ackValue>>
Spoutid,<系统生成的id,ackValue>
Task-0,64bit,0
ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。 每当acker发现一棵树的ack val值为0的时候,它就知道这棵树已经被完全处理了 。
STORM的消息容错机制
数据在处理中出现异常时,需要保证消息被完整处理。
SPOUT --A---B---C---D
期望:当其中一个环节出现异常时,Spout能够重新发送一份数据。
问题:SPOUT如何知道一条消息的处理状态
成功:ack(Object msgid)
失败:fail(Object msgid)
:Bolt如何告知Spout消息处理的状态
collector.emit(new Value())
collector.ack() //当消息处理成功时
collector.fail()//当消息处理失败时
Ack机制
Spout发送一条数据出去,需要知道数据处理成功和失败的状态,如果失败进行消息的重新发送
1、自定义spout实现BaseRichSpout,覆写ack,fail方法。
2、在自定义的spout发送数据的时候,需要制定messageid,messageid是一个Object。
3、当消息处理成功或失败之后,Storm框架会将messageId传回来。
如果消息要重发,直接通过messageId找到或直接转化成数据内容进行重发。
4、自定义Bolt实现BaseRichBolt
5、在bolt的execute中进行两个操作
5.1、发送数据时,需要指定血缘关系,锚点
collector.emit(父tuple,new 子Tuple)
5.2、当execute处理完业务逻辑的时候,需要告诉storm框架当前阶段的处理状态。
collector.ack(tuple)
如果在编写storm程序时,在bolt环节忘了手动ack或fail,怎么办?
忘了手动ack或fail,storm框架会等待反馈,达到超时阈值之后,就直接给fail。
如果在编写storm程序时,在bolt环节忘了标识锚点,怎么办?
忘了标识锚点,就是忘了标识血缘关系。storm会认为你不关心后面阶段的处理状况。
Storm BaseRichBolt API 过于繁琐,就开了另外一个api:BaseBasicBolt
如果实现了BaseBasicBolt,就不需要锚点,不需要手动ack或fail。
转载的第二篇博客
由于通信过程的不可靠性,传输的数据不可避免的会出现丢失、延迟、错误、重复等各种状况,TCP协议为解决这些问题设计了一系列机制。这个机制的核心,就是发送方向接收方发送数据后,接收方要向发送方发送ACK(回执)。如果发送方没接收到正确的ACK,就会重新发送数据直到接收到ACK为止。比如:发送方发送的数据序号是seq,那么接收方会发送seq + 1作为ACK,这样发送方就知道接下来要发送序号为seq + 1的数据给接收方了。
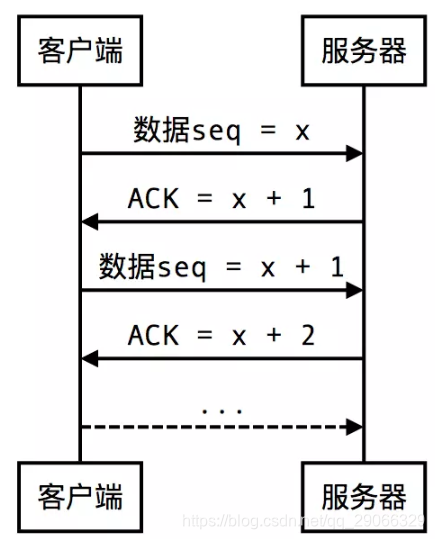
- 数据丢失或延迟。发送方发送数据seq时会起一个定时器,如果在指定时间内没有接收到ACK seq + 1,就把数据seq再发一次。
- 数据乱序。接收方上一个收到的正确数据是seq + 4,它返回seq + 5作为ACK。这时候它收到了seq + 7,因为顺序错了,所以接收方会再次返回seq + 5给发送方。
- 数据错误。每一个TCP数据都会带着数据的校验和。接收方收到数据seq + 3以后会先对校验和进行验证。如果结果不对,则发送ACK seq + 3,让发送方重新发送数据。
- 数据重复。接收方直接丢弃重复的数据即可。