目录
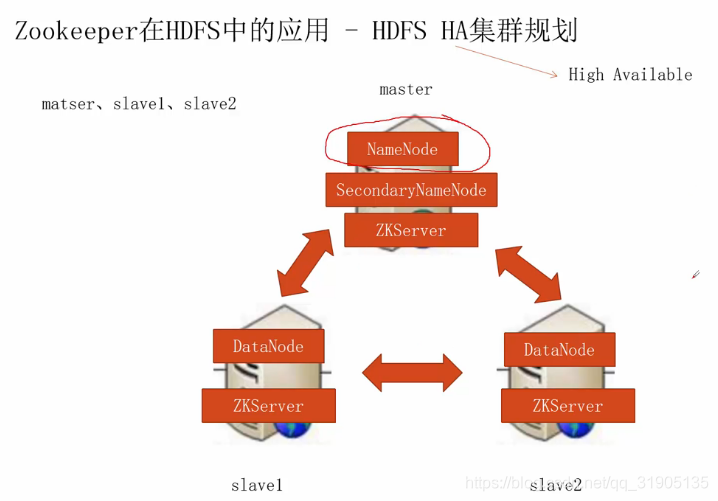
一、HDFS HA 集群规划
二、修改hdfs-site 和 core-site 配置
(1)停止集群,stop-dfs.sh, 然后备份三台机器hdfs的core-site.xml 和 hdfs-site.xml文件
(2)在master 节点的 hdfs-site.xml 增加如下配置
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
<description>hdfs各节点服务的逻辑名称,可以是任意值</description>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
<description>每一个namenode在集群中的唯一标识</description>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:8020</value>
<description>nn1这个namenode节点在rpc的时候使用的端口</description>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave1:8020</value>
<description>nn2这个namenode节点在rpc的时候使用的端口</description>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:50070</value>
<description>nn1这个namenode节点在对外提供的http服务的端口</description>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave1:50070</value>
<description>nn2这个namenode节点在对外提供的http服务的端口</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal:://master:8485:slave1:8485:slave2:8485/mycluster</value>
<description>标识journal组</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/journal/data</value>
<description>存储journal数据的地方</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>用于java客户端来连接Active的namenode</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>用于在namenode失败的时候不会对外提供服务</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop-twq/.ssh/id_dsa</value>
<description>用于在namenode失败的时候不会对外提供服务</description>
</property>(3)配置免密ssh 和 安装 fuser
用hadoop-twq 账号 在slave1 上配置无密钥登录master
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop-twq@master: ~/.ssh/
ssh master 不需要密码就表示配置成功
用root用户在master 和 salve1 上安装fuser
yum -y install psmisc
(4)配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs:mycluster</value>
<description>hdfs的基本路径</description>
</property>
将 core-site.xml 和 hdfs-site.xml 拷贝到slave1 和 slave2
scp core-site.xml hdfs-site.xml hadoop-twq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp core-site.xml hdfs-site.xml hadoop-twq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/
三、同步namenode 的 EditsLog 数据
(1)在master、slave1、slave2 上执行
~/bigdata/hadoop-2.7.5/sbin/hadoop-daemon.sh start journalnode
(2)在master中执行
scp r~/bigdata/dfs/name/ hadoop-twq@slave1: ~/bigdata/dfs/
(3) 如果从一个不足HA的hdfs集群转向HA集群,那么执行:
在slave1中执行
~/bigdata/hadoop-2.7.5/bin/hdfs namenode -bootstrapStandby = > 同步两个namenode 的数据
在master 中执行
hdfs namenode -initialzeSharedEdits = 》 初始化journal node 的数据
如果是全新搭建的一个HA的hdfs集群,那么执行:
在master 中执行
hdfs namenode -format即可
(4)重启 hdfs集群
start-hdfs.sh

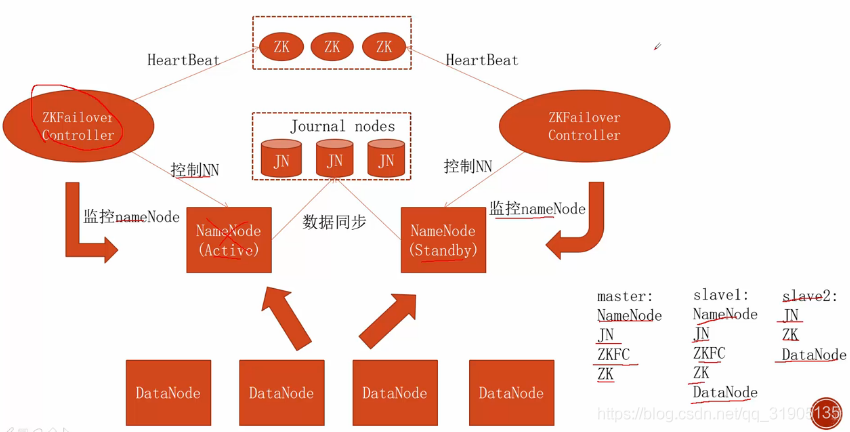
四、配置自动状态改变
在生产环境上面需要配置成自动切换 active 的 namenode节点,此处省略zk集群的搭建
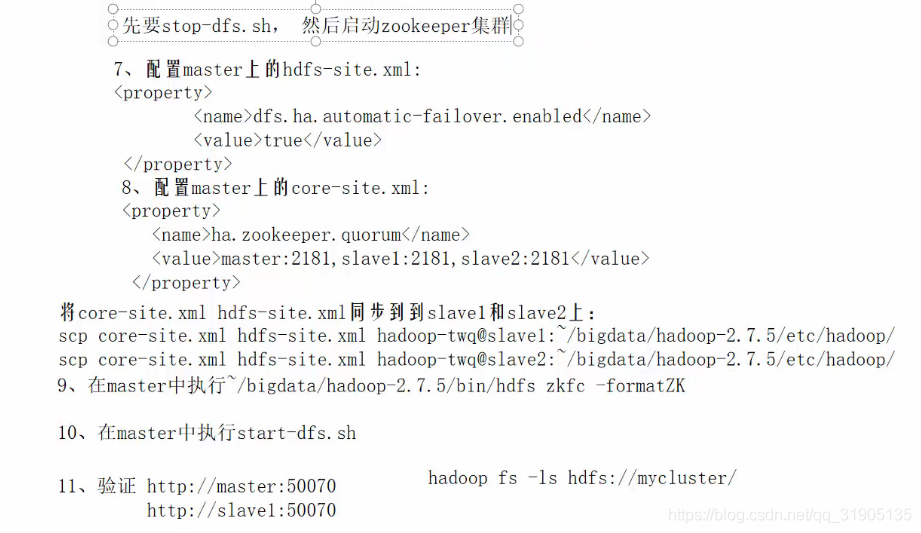
五、杀死一个active状态的namenode进行验证
访问 http://master:50070 可看到 当前节点是 active 状态
访问 http://slave1:50070可看到当前节点是 standby状态
在master 上面 jps 查看namenode 节点的 进程号,kill -9 进程号,杀死该进程
,再次访问 http://master:50070 发现当前节点变成了 standby 状态。
再次访问 http://slave1:50070 ,发现slave1 的 节点自动被zk选举为active状态。
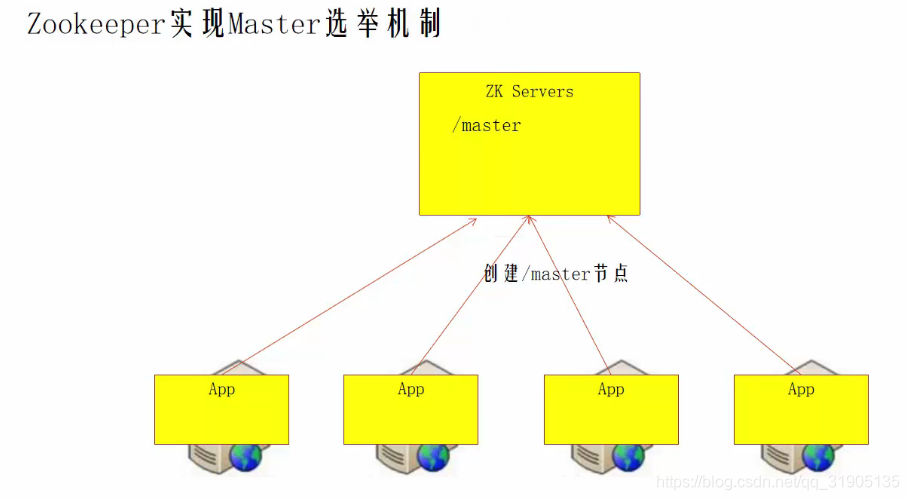
六、实现HA中的 zookeeper 的作用
七、清理垃圾数据
当我们需要把HA 集群回复成 单节点的 非HA 状态时,需要清理一些垃圾数据

八、配置yarn(ResourceManager) 的集群
将原先的 resourcemanager.hostname 和 resourcemanager.address注释掉


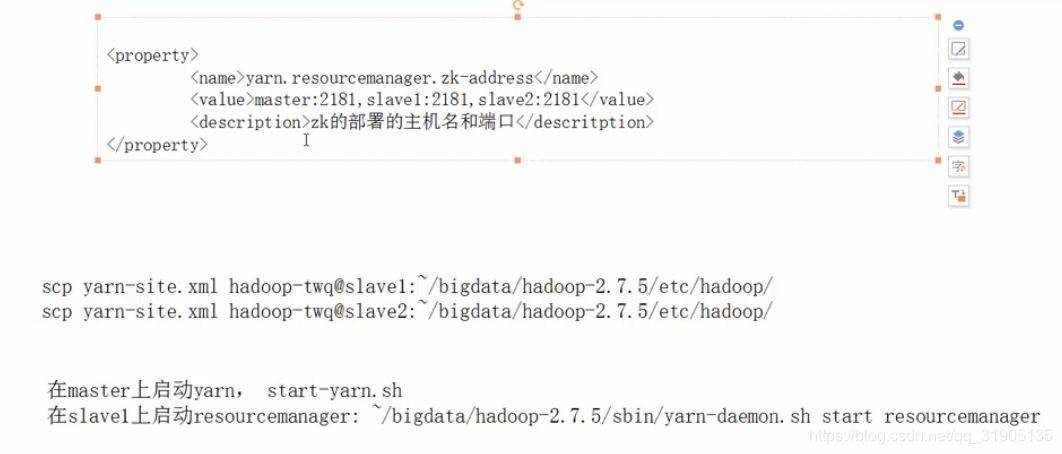
查看yarn 的状态
yarn rmadmin -getServiceState rm1
打印出active说明当前yarn节点是被选举状态。