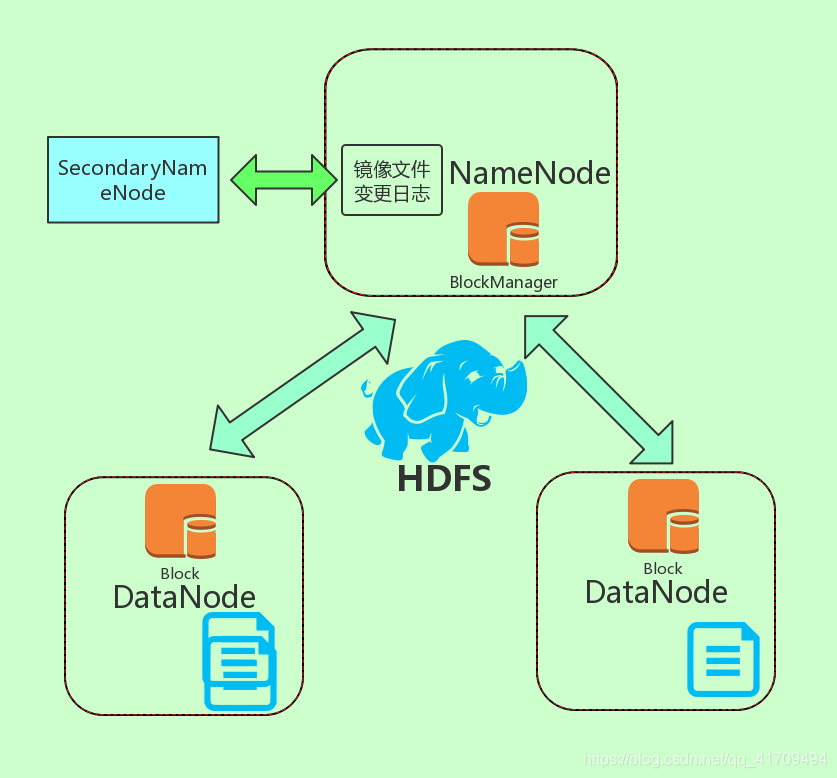
hdfs拓扑图:
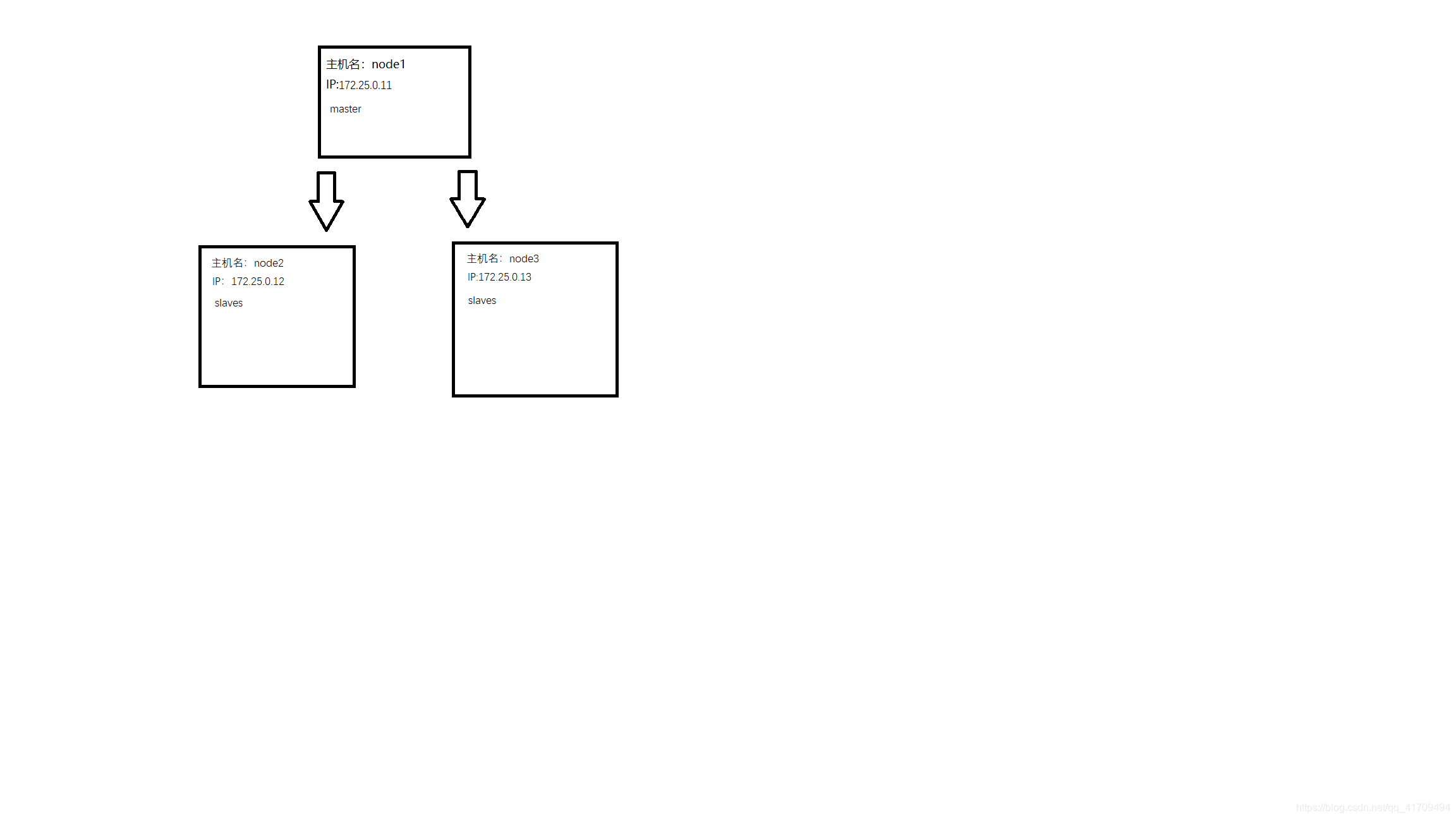
三台主机的拓扑图:
1.设置主机名
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3
2.ip映射主机名(所有节点)
echo '172.25.0.11 node1' >> /etc/hosts
echo '172.25.0.12 node2' >> /etc/hosts
echo '172.25.0.13 node3' >> /etc/hosts
3.创建用户和修改密码(所有节点)
useradd hadoop
echo 123456|passwd --stdin hadoop4.生成证书密钥(node1)
su - hadoop
[hadoop@node1 ~]$ssh-keygen -t dsa #一路按回车
5.在node1的hadoop用户下复制证书公钥到所有节点
[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node1
[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node2
[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node3
6.下载hadoop

hadoop官网下载地址:https://hadoop.apache.org/releases.html
#在这里我用Binary download(下载)
7.一定要在master(node1)上传hadoop包
[root@node1 ~]# rz -be
[root@node1 ~]# ll hadoop-3.2.0.tar.gz
-rw-r--r--. 1 root root 345625475 5月 7 11:55 hadoop-3.2.0.tar.gz8.解压hadoop包和移动hadoop的二进制文件到hadoop用户目录下,配置hadoop-env.sh的java的环境变量
[root@node1 ~]# tar -zxvf hadoop-3.2.0.tar.gz
[root@node1 ~]# cd hadoop-3.2.0/
[root@node1 hadoop-3.2.0]# mv * /home/hadoop/
9.安装java-1.8.0和配置hadoop-env.sh文件
[root@node1 ~]# yum install java-1.8*
[root@node1 ~]# find / -name ‘java-1.8.0’
…
/usr/lib/jvm/java-1.8.0 #找到这个,复制
…
[root@node1 ~]# vi /home/hadoop/etc/hadoop/hadoop-env.sh
…
#export JAVA_HOME=修改为export JAVA_HOME=/usr/lib/jvm/java-1.8.0
…
10.配置slaves添加node2,node3节点的主机名
[root@node1 ~]cd /home/hadoop/etc/hadoop
[root@node1 hadoop]# pwd #查看当前路径
/home/hadoop/etc/Hadoop
[root@node1 hadoop]# vi workers #注意:hadoop2.X版本是编辑 vi slaves
node2
node3 #添加的内容
11.配置core-site.xml
root@node1 ~]# cd /home/hadoop/etc/hadoop/
[root@node1 hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
</configuration>
12.配置hdfs-site.xml
[root@node1 ~]# cd /home/hadoop/etc/hadoop/
[root@node1 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
13.配置mapred-site.xml
配置mapred-site.xml
[root@node1 ~]# cd /home/hadoop/etc/hadoop/
[root@node1 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
14.配置yarn-site.xml
[root@node1 ~]# cd /home/hadoop/etc/hadoop/
[root@node1 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.addrss</name>
<value>node1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8088</value>
</property>
</configuration>
15.修改所有权和所属组
[root@node1 hadoop]# chown -R hadoop:hadoop /home/hadoop/
[root@node1 hadoop]# ll /home/hadoop/
总用量 184
drwxr-xr-x. 2 hadoop hadoop 203 1月 8 15:59 bin
drwxr-xr-x. 3 hadoop hadoop 20 1月 8 14:13 etc
drwxr-xr-x. 2 hadoop hadoop 106 1月 8 15:59 include
drwxr-xr-x. 3 hadoop hadoop 20 1月 8 15:58 lib
drwxr-xr-x. 4 hadoop hadoop 4096 1月 8 15:59 libexec
-rw-rw-r--. 1 hadoop hadoop 150569 10月 19 2018 LICENSE.txt
-rw-rw-r--. 1 hadoop hadoop 22125 10月 19 2018 NOTICE.txt
-rw-rw-r--. 1 hadoop hadoop 1361 10月 19 2018 README.txt
drwxr-xr-x. 3 hadoop hadoop 4096 1月 8 14:13 sbin
drwxr-xr-x. 4 hadoop hadoop 31 1月 8 16:32 share
16.node1的hadoop的配置复制到其他节点上(node2,node3)
[root@node1 hadoop]# cd /home/hadoop/
#复制到node2的hadoop用户下的/home/hadoop
[root@node1 hadoop]# scp -r * hadoop@node2:/home/hadoop/
#复制到node3的hadoop用户下的/home/hadoop
[root@node1 hadoop]#scp -r * hadoop@node3:/home/hadoop/
#注意:在node2切换到hadoop用户
[root@node2 ~]# su – hadoop
[hadoop@node2 ~]$ ll #查看内容是否传送过来,所有权和所属组是否为hadoop
总用量 184
drwxr-xr-x. 2 hadoop hadoop 203 5月 7 21:34 bin
drwxr-xr-x. 3 hadoop hadoop 20 5月 7 21:34 etc
drwxr-xr-x. 2 hadoop hadoop 106 5月 7 21:34 include
drwxr-xr-x. 3 hadoop hadoop 20 5月 7 21:34 lib
drwxr-xr-x. 4 hadoop hadoop 4096 5月 7 21:34 libexec
-rw-rw-r--. 1 hadoop hadoop 150569 5月 7 21:34 LICENSE.txt
-rw-rw-r--. 1 hadoop hadoop 22125 5月 7 21:34 NOTICE.txt
-rw-rw-r--. 1 hadoop hadoop 1361 5月 7 21:34 README.txt
drwxr-xr-x. 3 hadoop hadoop 4096 5月 7 21:34 sbin
drwxr-xr-x. 4 hadoop hadoop 31 5月 7 21:36 share
#注意:在node3切换hadoop用户
[root@node3 ~]# su – hadoop
[hadoop@node3 ~]$ ll
总用量 184
drwxr-xr-x. 2 hadoop hadoop 203 5月 7 21:53 bin
drwxr-xr-x. 3 hadoop hadoop 20 5月 7 21:53 etc
drwxr-xr-x. 2 hadoop hadoop 106 5月 7 21:53 include
drwxr-xr-x. 3 hadoop hadoop 20 5月 7 21:53 lib
drwxr-xr-x. 4 hadoop hadoop 4096 5月 7 21:53 libexec
-rw-rw-r--. 1 hadoop hadoop 150569 5月 7 21:53 LICENSE.txt
-rw-rw-r--. 1 hadoop hadoop 22125 5月 7 21:53 NOTICE.txt
-rw-rw-r--. 1 hadoop hadoop 1361 5月 7 21:53 README.txt
drwxr-xr-x. 3 hadoop hadoop 4096 5月 7 21:53 sbin
drwxr-xr-x. 4 hadoop hadoop 31 5月 7 21:54 share
17.node1(master)节点格式化
#注意:首先要切换到hadoop用户下
[root@node1 ~]# su – hadoop
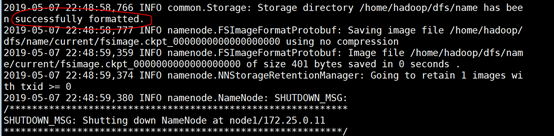
[hadoop@node1 ~]$ hadoop namenode -format 或用 hdfs namenode -format
#显示这个就成功了
18.修改hadoop用户下的环境变量(.bash_profile或者.bash_)
[hadoop@node1 ~]$ vi .bash_profile
…
PATH=$PATH:$HOME/.local/bin:$HOME/bin
HADOOP_HOME=/home/hadoop
PATH=$PATH:$HADOOP_HOME/sbin
export PATH
[hadoop@node1 ~]$ echo $PATH #输出环境变量
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/hadoop/.local/bin:/home/hadoop/bin
[hadoop@node1 ~]$ source .bash_profile #让环境变量生效
[hadoop@node1 ~]$ echo $PATH #再次输出环境变量,对比上一次的环境变量的变化
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/hadoop/.local/bin:/home/hadoop/bin:/home/hadoop/.local/bin:/home/hadoop/bin:/home/hadoop/sbin
#注意:当一个进程执行完毕时,该进程会调用一个名为 _exit 的例程来通知内核它已经做好“消亡”的准备了。该进程会提供一个退出码(一个整数)表明它准备退出的原因。按照惯例,0用来表示正常的或者说“成功”的终止。
[hadoop@node1 ~]$ echo $?
0
19.执行脚本启动
[hadoop@node1 ~]$ start-dfs.sh
或者用
#注意:这里是不用编辑环境变量,直接到sbin里面执行脚本
[hadoop@node1 ~]$ cd sbin/
[hadoop@node1 sbin]$ ./start-dfs.sh
[hadoop@node1 ~]$ start-yarn.sh
或者用
[hadoop@node1 ~]$ cd sbin/
[hadoop@node1 sbin]$ ./start-yarn.sh
[hadoop@node1 ~]$ hdfs dfsadmin -report #查看集群状态
[hadoop@node1 ~]$ hdfs fsck / -files -blocks #查看文件块组成
Connecting to namenode via http://node1:9870/fsck?ugi=hadoop&files=1&blocks=1&path=%2F
FSCK started by hadoop (auth:SIMPLE) from /172.25.0.11 for path / at Tue May 07 23:43:44 CST 2019
...
20.浏览网页查看集群状态

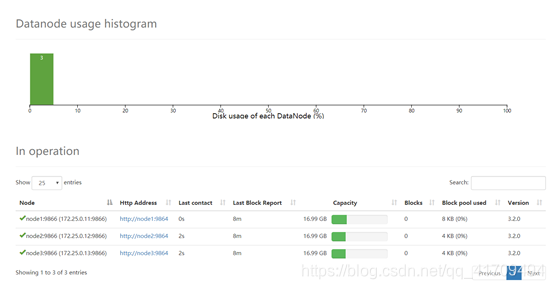
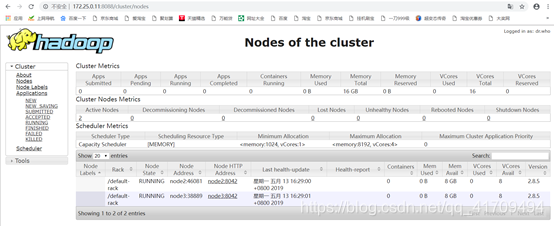
21.检查每台节点的运行情况
[hadoop@node1 ~]$ jps
2208 NameNode
3025 Jps
2426 SecondaryNameNode
2717 ResourceManager
[hadoop@node2 ~]$ jps
2049 DataNode
2321 Jps
2200 NodeManager
[root@node3 ~]# jps
2050 DataNode
2202 NodeManager
2300 Jps
22.使用wordcount计算单词
[hadoop@node1 ~]$ mkdir test
[hadoop@node1 ~]$ cd test
[hadoop@node1 test]$ vi test.txt
I am learning hadoop.
Hello hadoop.
I am using hadoop.
[hadoop@node1 test]$ hdfs dfs -mkdir /input
[hadoop@node1 test]$ hdfs dfs -put test.txt /input
[hadoop@node1 ~]$ cd /home/hadoop/share/hadoop/mapreduce
[hadoop@node1 mapreduce]$ pwd
/home/hadoop/share/hadoop/mapreduce
[hadoop@node1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.0.jar wordcount /input /output/demo
#出错了,hadoop3.x以后的版本;至于hadoop2.x以后的版本就没出过这样的错误
2019-05-08 18:18:13,351 INFO mapreduce.Job: Job job_1557310614588_0001 failed with state FAILED due to: Aplication application_1557310614588_0001 failed 2 times due to AM Container for appattempt_1557310614588_001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2019-05-08 18:18:12.987]Exception from container-launch.
Container id: container_1557310614588_0001_02_000001
Exit code: 1
[2019-05-08 18:18:13.013]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
23.解决错误
[hadoop@node1 mapreduce]$ hadoop classpath
/home/hadoop/etc/hadoop:/home/hadoop/share/hadoop/common/lib/*:/home/hadoop/share/hadoop/common/*:/home/haoop/share/hadoop/hdfs:/home/hadoop/share/hadoop/hdfs/lib/*:/home/hadoop/share/hadoop/hdfs/*:/home/hadoop/sare/hadoop/mapreduce/lib/*:/home/hadoop/share/hadoop/mapreduce/*:/home/hadoop/share/hadoop/yarn:/home/hadop/share/hadoop/yarn/lib/*:/home/hadoop/share/hadoop/yarn/*
[hadoop@node1 ~]$ cd /home/hadoop/etc/hadoop/
#添加内容
[hadoop@node1 hadoop]$ vi yarn-site.xml
…
<property>
<name>yarn.application.classpath</name>
<value>/home/hadoop/etc/hadoop:/home/hadoop/share/hadoop/common/lib/*:/ome/hadoop/share/hadoop/common/*:/home/hadoop/share/hadoop/hdfs:/home/hadoop/share/hadoop/hdfs/lib/*:/home/hadoop/share/hadoop/hdfs/*:/home/hadoop/share/hadoop/mapreduce/lib/*:/home/hadoop/share/hadoop/mapreduce/*:/home/hadoop/share/hadoop/yarn:/home/hadoop/share/hadoop/yarn/lib/*:/home/hadoop/share/hadoop/yarn/*</value>
</property>
…
#重启一下
[hadoop@node1 ~]$ stop-all.sh
[hadoop@node1 ~]$ start-all.sh
[hadoop@node1 ~]$ cd /home/hadoop/share/hadoop/mapreduce
#显示这个就成功了
[hadoop@node1 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.0.jar wordcount /input /output/demo
2019-05-08 18:36:18,532 INFO mapreduce.Job: Running job: job_1557311701691_0001
2019-05-08 18:36:29,683 INFO mapreduce.Job: Job job_1557311701691_0001 running in uber mode : false
2019-05-08 18:36:29,686 INFO mapreduce.Job: map 0% reduce 0%
2019-05-08 18:36:35,762 INFO mapreduce.Job: map 100% reduce 0%
2019-05-08 18:36:40,851 INFO mapreduce.Job: map 100% reduce 100%
2019-05-08 18:36:40,868 INFO mapreduce.Job: Job job_1557311701691_0001 completed successfully
2019-05-08 18:36:40,959 INFO mapreduce.Job: Counters: 54
#浏览网页并找到output目录点击,再点击demo目录发现了两个文件
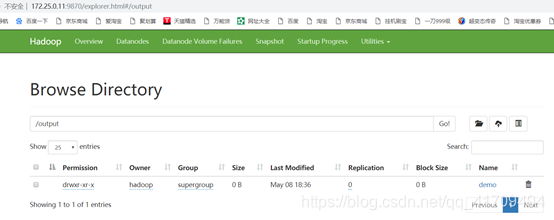
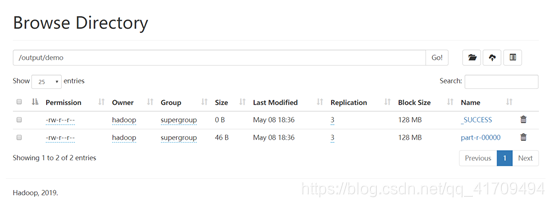
24.查看计数结果
#注意:切换路径
[hadoop@node1 mapreduce]$ cd
[hadoop@node1 ~]$ cd test/
[hadoop@node1 test]$ hdfs dfs -get /output/demo/*
[hadoop@node1 test]$ ll
总用量 8
-rw-r--r--. 1 hadoop hadoop 46 5月 8 18:38 part-r-00000
-rw-r--r--. 1 hadoop hadoop 0 5月 8 18:38 _SUCCESS
-rw-rw-r--. 1 hadoop hadoop 56 5月 8 18:04 test.txt
#对比一下编辑的文件和计算的文件
[hadoop@node1 test]$ cat part-r-00000
Hello 1
I 2
am 2
hadoop. 3
learning 1
using 1
[hadoop@node1 test]$ cat test.txt
I am learning hadoop.
Hello hadoop.
I am using hadoop.