关键词标记
最近在做一个微信过滤的后台程序,设计的主要目的不是屏蔽你的消息,而是记录你的行为,别的就不能再说了!
平时的脏字过滤是把“你麻痹”替换成“你**”,而我的功能是标记出来,把“你麻痹”标记成“<#>你麻痹</#>”这样子,所以在做的时候遇到了不少的问题。一开始就想着用kmp算法实现嘛,不过做着做着心态就崩了,因为那边改需求,好吧!挺烦的。最后重新写了一遍,用了二叉树实现。实现的比较傻逼,别见怪。
原句:中国人爱中国的每一片土地。
关键词:{"中国人","爱","中国"}
我要返回的句子就是:
<#>中国人</#><#>爱</#><#>中国</#>的每一片土地。
//树节点:
public class Node {
public String data;
public Node left;
public Node right;
public Node(String data) {
super();
this.data = data;
left=null;
right=null;
}
}这是一个很简单的树。
我的考虑是这样的:
我找到第一个词以后就对它进行分割,关键词就是父节点,然后子节点就是剩下的句子。
例如句子:
我们中国人爱中国人,爱中国的土地。
关键词:
中国人,爱,中国(关键词按顺序标记出来)
思路,第一次找到中国人这个关键词,以它分割成三个元素:
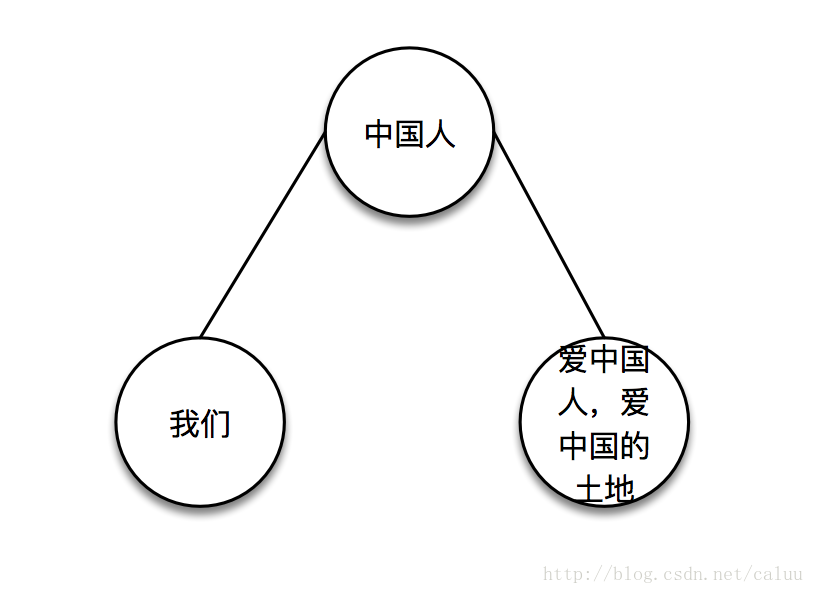
分完以后,左边肯定没有中国人这个关键词,右边可能有,所以找右子树,找到后继续分:
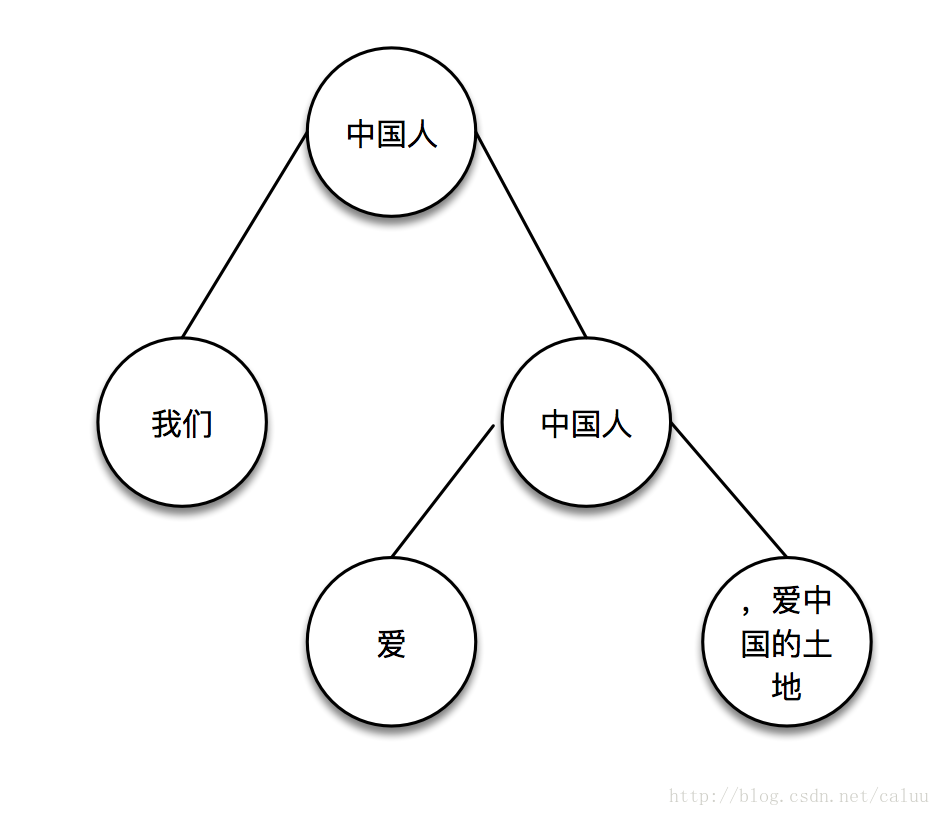
继续找右子树看有没有中国人这个关键词,没有的话,这个关键词就找完了。
然后开始找第二个关键词:爱
这个时候要注意的是不能嵌套找,也就是说,你不能在关键词”中国人“里面标记“中国”这个关键词,所以,找的时候只能找叶子节点,如果有关键词,依旧像之前那样分割:
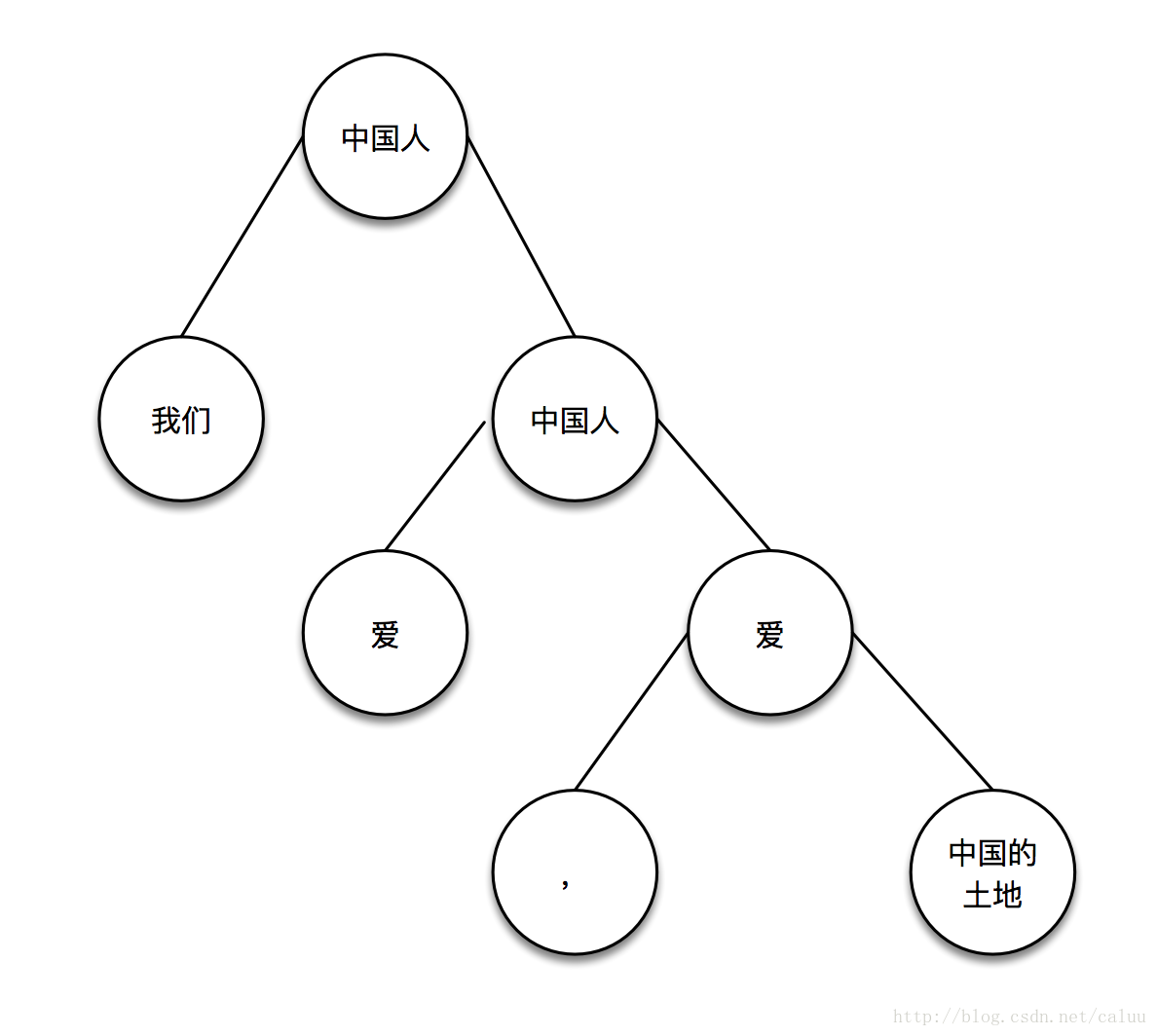
然后找中国
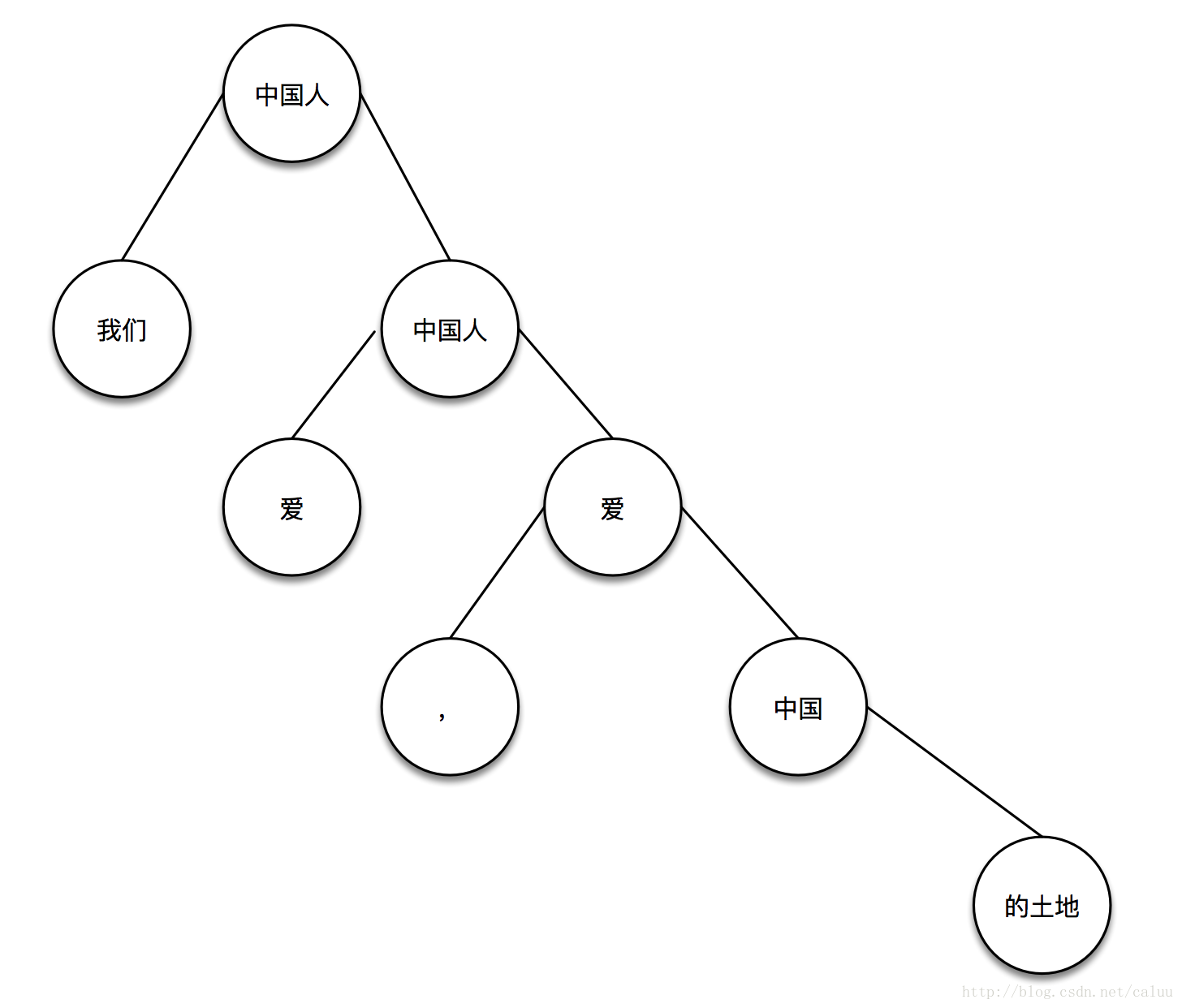
这样,这个树就搭建起来了:
之后通过前序遍历,遇到结点就添加标记符号<#>
// 先初始化树 根据第一个关键词把树先建立起来,左子树肯定没有第一个关键词,右子树有可能有关键词
public static void createTree(Node root, String word) {
// 当右子树不为空的时候判断,右子树为空的时候跳出循环
while (root.right != null) {
// 当右子树不含有关键词的时候函数返回
if (root.right.data.indexOf(word) != -1) {
root = root.right;
int indexOf = root.data.indexOf(word);
String l = root.data.substring(0, indexOf);
root.left = new Node(l);
String r = root.data.substring(indexOf + word.length(), root.data.length());
root.right = new Node(r);
root.data = word;
} else
break;
}
}
public static void rebuild(Node root, String word) { // 先根遍历
// 判断是否叶子节点
if (root != null) {
rebuild(root.left, word);
if (root.left == null && root.right == null) {
String msg = root.data;
int indexOf = msg.indexOf(word);
if (indexOf != -1) {
String f = msg.substring(0, indexOf);
String s = msg.substring(indexOf + word.length(), msg.length());
root.left = new Node(f);
root.right = new Node(s);
root.data = word;
createTree(root, word);
}
}
rebuild(root.right, word);
}
}
public static String preOrder(Node root,StringBuilder string) { // 先根遍历
// StringBuilder string = new StringBuilder();
if (root != null) {
preOrder(root.left,string);
if (root.left != null || root.right != null) {
string.append("<#>").append(root.data).append("</#>");
// System.out.print("<#>" + root.data + "</#>");
} else {
// System.out.print(root.data);
string.append(root.data);
}
// System.out.print(root.data+"-");
preOrder(root.right,string);
}
return string.toString();
}
public static void matchMsg(String msg, String[] word) {
Node root = new Node(word[0]);
int indexOf = msg.indexOf(word[0]);
if (indexOf != -1) {
String f = msg.substring(0, indexOf);
String s = msg.substring(indexOf + word[0].length(), msg.length());
root.left = new Node(f);
root.right = new Node(s);
}
createTree(root, word[0]);
for (int i = 1; i < word.length; i++) {
rebuild(root, word[i]);
}
System.out.println("先根遍历:");
StringBuilder string = new StringBuilder();
String pp = preOrder(root,string);
System.out.println(pp);
}
// 建立线程池并行处理
public static void poolThread(String msg,String[] word,String[] word1) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
for (int i = 1; i <= 2; i++) {
int index =i;
fixedThreadPool.execute(new Runnable() {
public void run() {
if(index==1)matchMsg(msg,word);
if(index==2)matchMsg(msg,word1);
}
});
}
}
public static void main(String[] args) {
String msg = "我们中国人爱中国人,爱中国的土地。;";
String[] word = { "中国人", "爱", "中国" };
String[] word1 = { "中国人"};
matchMsg(msg,word);
}