目录
Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。
事件驱动型应用
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
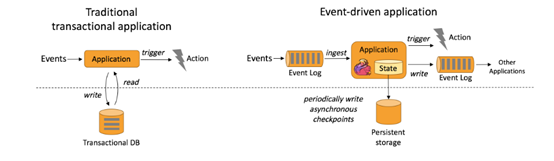
典型的事件驱动型应用实例:
反欺诈
异常检测
基于规则的报警
业务流程监控
(社交网络)Web 应用
数据分析型应用
数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。借助一些先进的流处理引擎,还可以实时地进行数据分析。和传统模式下读取有限数据集不同,流式查询或应用会接入实时事件流,并随着事件消费持续产生和更新结果。这些结果数据可能会写入外部数据库系统或以内部状态的形式维护。仪表展示应用可以相应地从外部数据库读取数据或直接查询应用的内部状态。
如下图所示,Apache Flink 同时支持流式及批量分析应用。
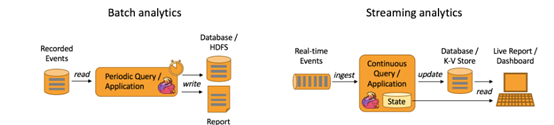
Flink 如何支持数据分析类应用?
Flink 为持续流式分析和批量分析都提供了良好的支持。具体而言,它内置了一个符合 ANSI 标准的 SQL 接口,将批、流查询的语义统一起来。无论是在记录事件的静态数据集上还是实时事件流上,相同 SQL 查询都会得到一致的结果。同时 Flink 还支持丰富的用户自定义函数,允许在 SQL 中执行定制化代码。如果还需进一步定制逻辑,可以利用 Flink DataStream API 和 DataSet API 进行更低层次的控制。此外,Flink 的 Gelly 库为基于批量数据集的大规模高性能图分析提供了算法和构建模块支持。
典型的数据分析应用实例:
电信网络质量监控
移动应用中的产品更新及实验评估分析
消费者技术中的实时数据即席分析
大规模图分析
数据管道型应用
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
下图描述了周期性 ETL 作业和持续数据管道的差异。
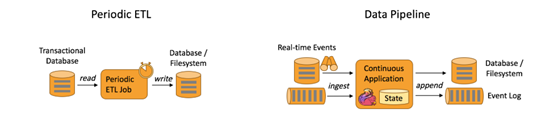
典型的数据管道应用实例:
电子商务中的实时查询索引构建
电子商务中的持续 ETL