目录
一、性能调优分析
1、分析:调优的目的是提升系统的性能,针对系统的“瓶颈点”对症“下药”,通过测试验证系统的性能有多大的提升。
2、风险:未进行调优的系统,系统上线后,可能会出现客户体验差的效果,甚至导致系统“崩溃”的风险。
3、中间件调优:线程池、数据库连接池、JVM。
4、数据库调优:效率低下SQL、死锁和锁等待、缓存命中率,进程和会话参数。
5、应用调优:方法耗时、算法、同步和异步、缓存、缓冲。
二、TOMCAT调优
1、修改用户线程数
vi /etc/security/limits.d/90-nproc.conf
2、修改文件打开数
vi /etc/security/limits.conf
@monitor - nice 10 # 限制nice不能低于10
@monitor - priority 10 # nice默认是10
@monitor - fsize 1024000 # 单个文件不能超过1G
@monitor - rss 1024000 # 驻留内存不能超过1G
@monitor - nofile 512 # 文件打开数不能超过512
@monitor - nproc 128 # 最大进程数不能超过128
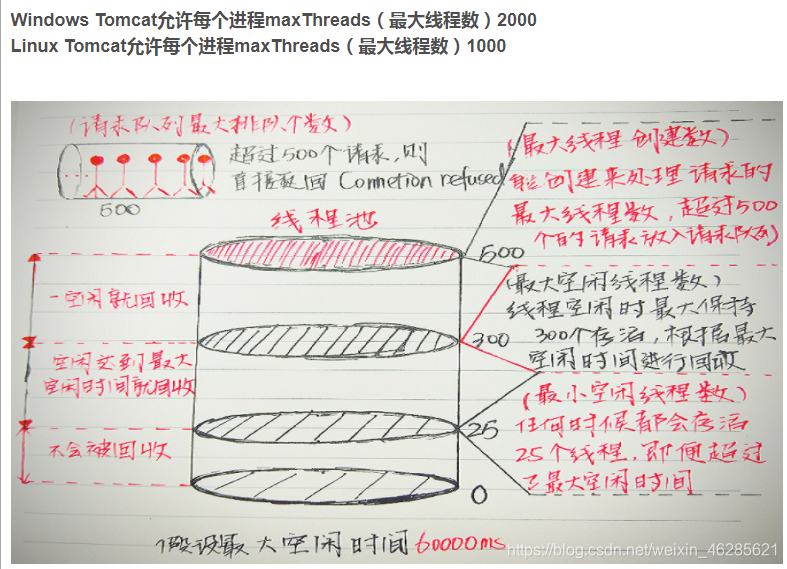
3、优化tomcat连接数
vi /conf/server.xml
<Connector port="60081" protocol="HTTP/1.1"
connectionTimeout="20000"
minSpareThreads="50"
maxSpareThreads="400"
maxThreads="600"
acceptCount="500"
redirectPort="8443" />

4、优化tomcat的数据库连接数
vi /apps/ba3/ba3_tomcat8_60081//webapps/ba3/WEB-INF/classes/application-preprod.properties
app.readonly1.datasource.minIdle=3
app.readonly1.datasource.maxActive=40
app.readonly1.datasource.maxWait=60000
三、JVM调优
1、堆栈溢出:
Java.lang.OutOfMemoryError: ......Java heap space.....
也就是当你看到heap相关的时候就肯定是堆栈溢出了,此时如果代码没有问题的情况下,适当调整-Xmx和-Xms是可以避免的,不过一定是代码没有问题的前提,为什么会溢出呢,要么代码有问题,要么访问量太多并且每个访问的时间太长或者数据太多,导致数据释放不掉,因为垃圾回收器是要找到那些是垃圾才能回收,这里它不会认为这些东西是垃圾,自然不会去回收了;主意这个溢出之前,可能系统会提前先报错关键字为:
java.lang.OutOfMemoryError:GC over head limit exceeded
这种情况是当系统处于高频的GC状态,而且回收的效果依然不佳的情况,就会开始报这个错误,这种情况一般是产生了很多不可以被释放的对象,有可能是引用使用不当导致,或申请大对象导致,但是java heap space的内存溢出有可能提前不会报这个错误,也就是可能内存就直接不够导致,而不是高频GC.
2、永久代溢出
java.lang.OutOfMemoryError: PermGen space
原因:系统的代码非常多或引用的第三方包非常多、或代码中使用了大量的常量、或通过intern注入常量、或者通过动态代码加载等方法,导致常量池的膨胀,虽然JDK 1.5以后可以通过设置对永久带进行回收,但是我们希望的是这个地方是不做GC的,它够用就行,所以一般情况下今年少做类似的操作,所以在面对这种情况常用的手段是:增加-XX:PermSize和-XX:MaxPermSize的大小。
3、在使用ByteBuffer中的allocateDirect()的时候会用到,很多javaNIO的框架中被封装为其他的方法
java.lang.OutOfMemoryError: Direct buffer memory
如果你在直接或间接使用了ByteBuffer中的allocateDirect方法的时候,而不做clear的时候就会出现类似的问题,常规的引用程序IO输出存在一个内核态与用户态的转换过程,也就是对应直接内存与非直接内存,如果常规的应用程序你要将一个文件的内容输出到客户端需要通过OS的直接内存转换拷贝到程序的非直接内存(也就是heap中),然后再输出到直接内存由操作系统发送出去,而直接内存就是由OS和应用程序共同管理的,而非直接内存可以直接由应用程序自己控制的内存,jvm垃圾回收不会回收掉直接内存这部分的内存,所以要注意了哦。
如果经常有类似的操作,可以考虑设置参数:-XX:MaxDirectMemorySize
4、栈溢出
java.lang.StackOverflowError
这个参数直接说明一个内容,就是-Xss太小了,我们申请很多局部调用的栈针等内容是存放在用户当前所持有的线程中的,线程在jdk 1.4以前默认是256K,1.5以后是1M,如果报这个错,只能说明-Xss设置得太小,当然有些厂商的JVM不是这个参数,本文仅仅针对Hotspot VM而已;不过在有必要的情况下可以对系统做一些优化,使得-Xss的值是可用的。
5、内存不够
java.lang.OutOfMemoryError: unable to create new native thread
上面第四种溢出错误,已经说明了线程的内存空间,其实线程基本只占用heap以外的内存区域,也就是这个错误说明除了heap以外的区域,无法为线程分配一块内存区域了,这个要么是内存本身就不够,要么heap的空间设置得太大了,导致了剩余的内存已经不多了,而由于线程本身要占用内存,所以就不够用了,说明了原因,如何去修改,不用我多说,你懂的。
6、地址空间不够
java.lang.OutOfMemoryError: request {} byte for {}out of swap
7、创建的数组大于堆内存的空间
Exception in thread “main”: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
四、数据库调优
1、SQL优化的必要性
我们开发项目上线初期,由于业务数据量相对较少,一些SQL的执行效率对程序运行效率的影响不太明显,而开发和运维人员也无法判断SQL对程序的运行效率有多大,故很少针对SQL进行专门的优化,而随着时间的积累,业务数据量的增多,SQL的执行效率对程序的运行效率的影响逐渐增大,此时对SQL的优化就很有必要。
2、SQL优化原则:
增加B+树索引:
- 如果一个(或一组)属性经常在查询条件中出现,考虑建立索引(或组合索引)。
- 如果属性经常在连接操作的连接条件中出现,考虑建立索引。
- 如果属性经常作为最大值和最小值等聚集函数的参数,考虑建立索引。
- 系统维护索引要付出代价,查询索引也要付出代价。若一个关系表更新频率很高,则索引不能太多,因为更新表时需要对表的有关索引做响应修改。
增加hash索引:
- 如果属性主要出现在等值连接条件和等值比较条件,满足表的大小可预见且不变或大小动态变化而数据库系统提供动态的hash存取方法的。
增加聚簇索引:
- 把属性具有相同值的元组存放在连续的物理块中,减少IO次数,提供查询效率。
- 一个表只能建立一个聚簇索引,多个表连接建立一个聚簇索引。
- 经常在一起连接操作的,出现相等比较条件的,属性值重复率高的。
- 从聚簇中删除经常全表扫描的,更新操作多于连接操作的。
- 一个表不能属于多个聚簇,建立与维护聚簇的开销比较大,聚簇码要相对稳定。
确定存放位置:易变与稳定部分数据分开存放,表和索引放在不同磁盘,大表分开存放,日志文件与数据库对象(表,索引等)分开存放。
3、SQL优化的一些方法
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
应改为:
select id from t where name like 'abc%'
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用,估算查询结果数据量比例小于10%使用索引。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,
因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,
其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.对于连接,连接条件可以使用索引。先做选择再做连接操作,减少全表扫描。
19.避免频繁创建和删除临时表,以减少系统表资源的消耗。
20.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
21.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,
以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
22.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
23.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
24.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
25.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。
在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
26.尽量避免大事务操作,提高系统并发能力。
27.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。