开源地址:
- github: https://github.com/sagframe/sagacity-sqltoy
- gitee: https://gitee.com/sagacity/sagacity-sqltoy
- idea 插件(可直接在idea中检索安装): https://github.com/threefish/sqltoy-idea-plugins
更新内容
1、分页支持总记录数和单页数据并行查询,提升效率
xml配置模式:parallel="true"
<sql id="qstart_fastPage">
<!-- 分页优化器,通过缓存实现查询条件一致的情况下在一定时间周期内缓存总记录数量,从而无需每次查询总记录数量 -->
<!-- alive-max:最大存放多少个不同查询条件的总记录量; alive-seconds:查询条件记录量存活时长(比如120秒,超过阀值则重新查询) -->
<!-- parallel: 是否并行count和记录查询开关; parallel-maxwait-seconds:并行查询最大等待时长(可以不填) -->
<page-optimize parallel="true" alive-max="100" alive-seconds="120" />
<value>
<![CDATA[
select t1.*,t2.ORGAN_NAME
-- @fast() 实现先分页取10条(具体数量由pageSize确定),然后再进行管理
from @fast(select t.*
from sqltoy_staff_info t
where t.STATUS=1
#[and t.STAFF_NAME like :staffName]
order by t.ENTRY_DATE desc
) t1
left join sqltoy_organ_info t2 on t1.organ_id=t2.ORGAN_ID
]]>
</value>
<!-- 这里为极特殊情况下提供了自定义count-sql来实现极致性能优化 -->
<!-- <count-sql></count-sql> -->
</sql>
// java直接设置:new PageOptimize().parallel(true)
PaginationModel<StaffInfoVO> result = sqlToyLazyDao
.findPageByQuery(pageModel,
new QueryExecutor("qstart_fastPage").values(staffVO)
.pageOptimize(new PageOptimize().parallel(true)).resultType(StaffInfoVO.class))
.getPageResult();
- 分页优化过程介绍
https://my.oschina.net/u/4234377/blog/3233919
- 简要介绍sqltoy的几个特点(jpa式的对象crud大家早习以为常不作介绍)
sqltoy 提供了最简洁的动态 sql 编写
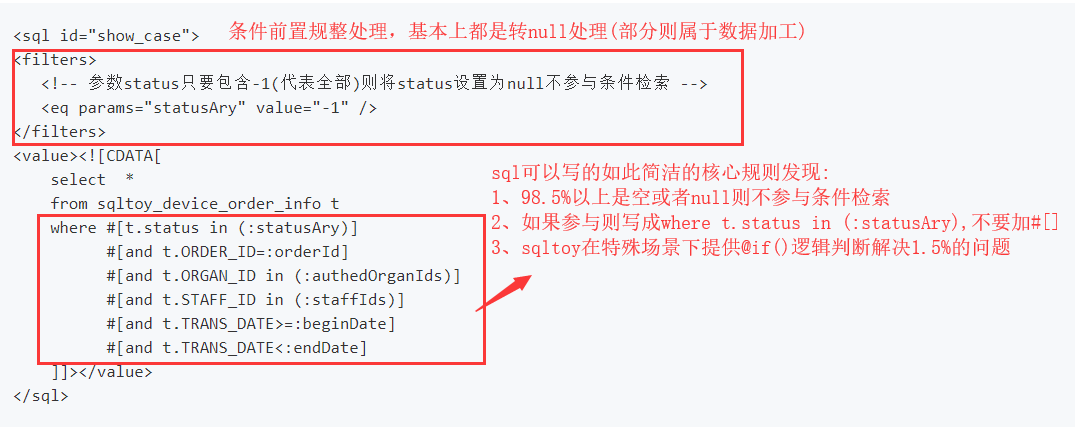
我们对比一下mybatis的实现(从可阅读、可维护等视角看):

- 缓存翻译,利用缓存减少关联查询,简化sql同时大幅提升效率
- 极致分页优化
- 并行查询
// 使用并行查询同时执行2个sql,条件参数是2个查询的合集
String[] paramNames = new String[] { "userId", "defaultRoles", "deployId", "authObjType" };
Object[] paramValues = new Object[] { userId, defaultRoles, DEPLOY_ID,GROUP };
List<QueryResult<TreeModel>> list = super.parallQuery(
Arrays.asList(ParallQuery.create().sql("webframe_searchAllModuleMenus").resultType(TreeModel.class),
ParallQuery.create().sql("webframe_searchAllUserReports").resultType(TreeModel.class)),
paramNames, paramValues);
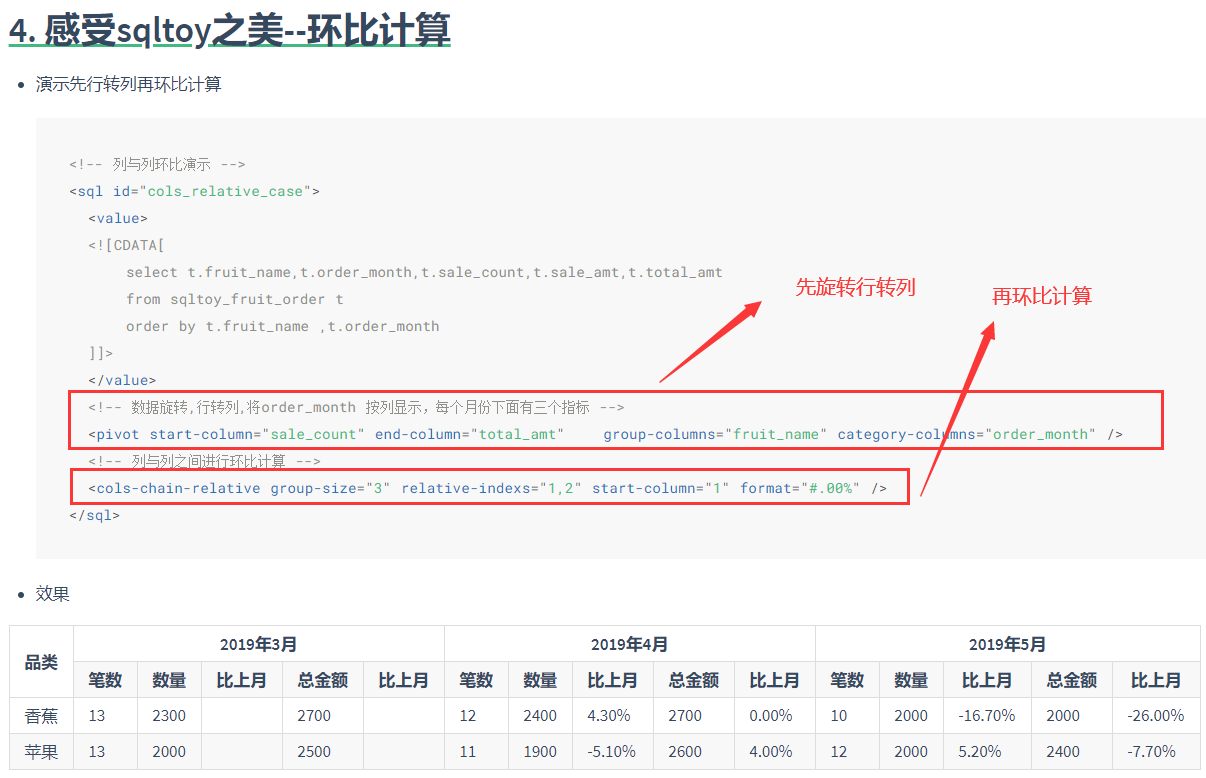
- 数据旋转
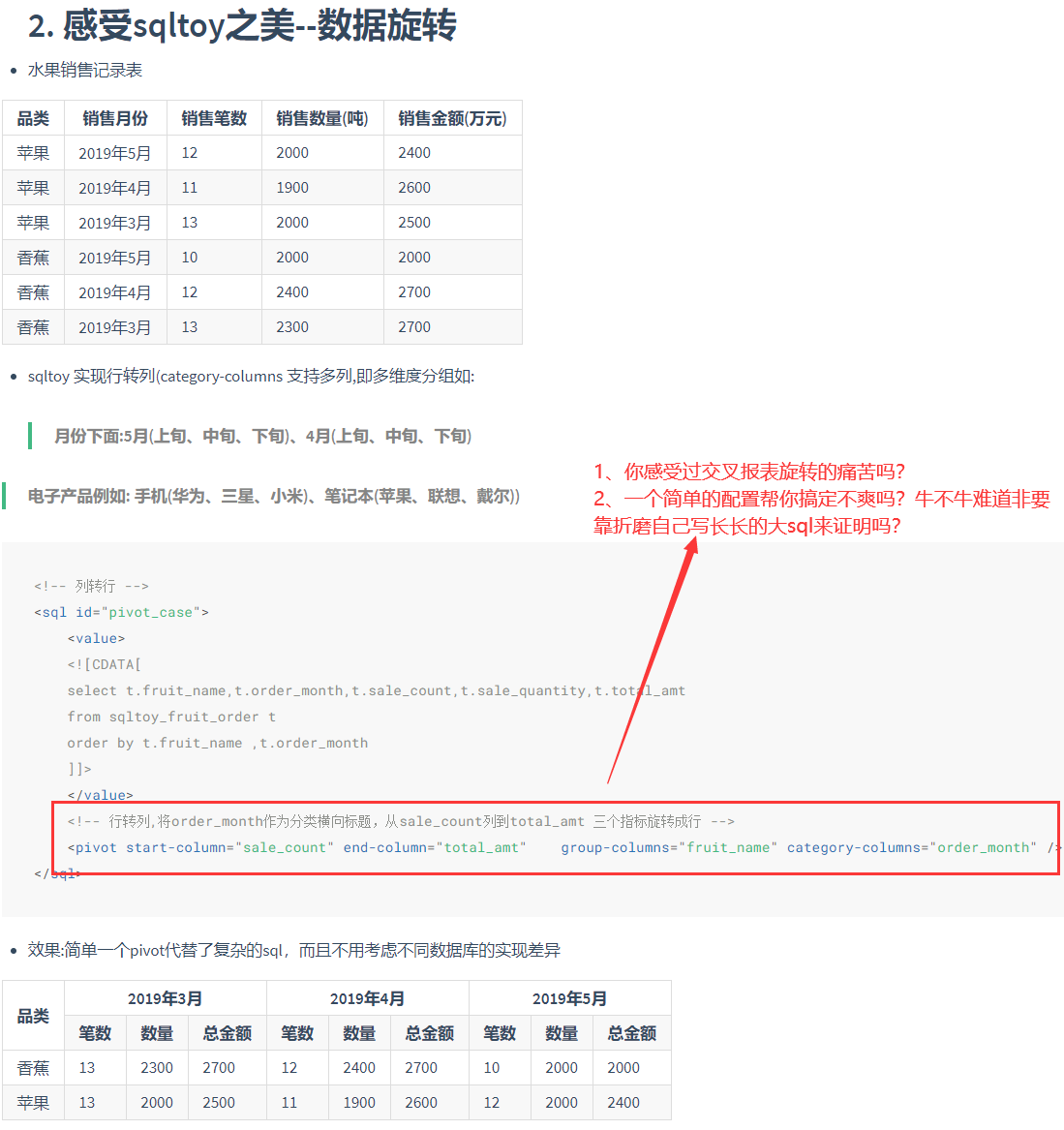
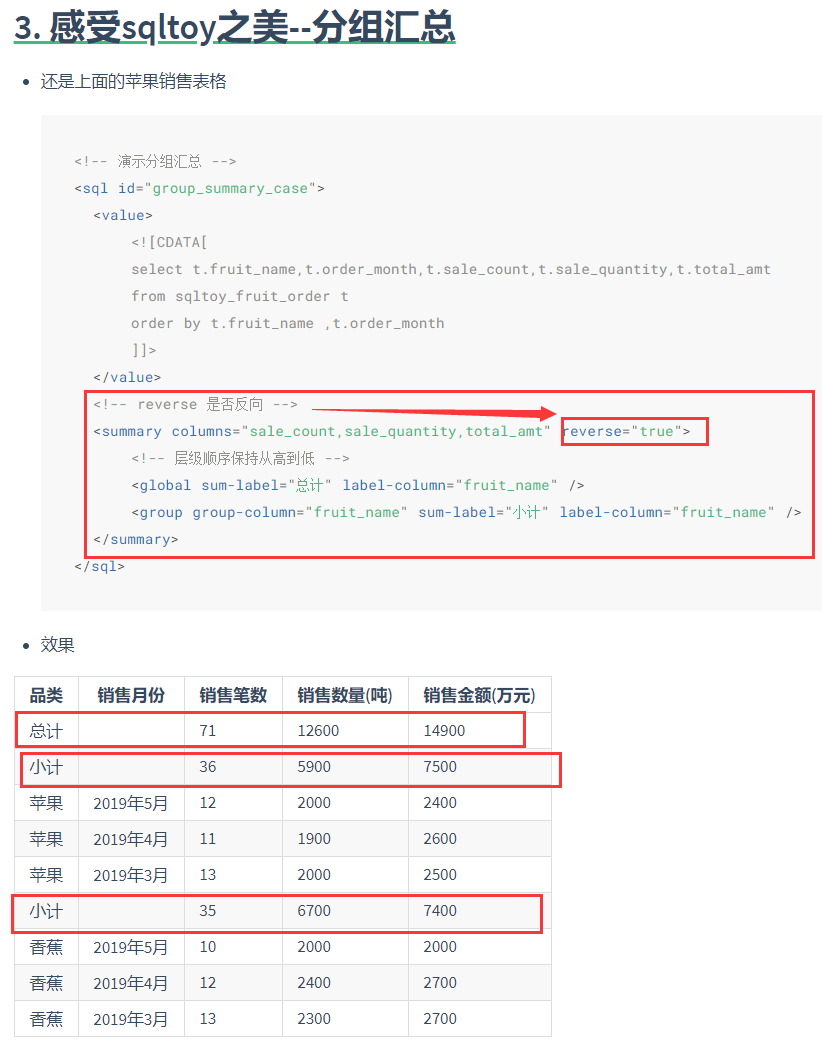
- 无限极分组统计(含汇总求平均),算法配置简单又跨数据库!
- 同比环比