前言
Alluxio作为一套构建于底层存储系统之上的中间层,它必不可少的会涉及到于底层系统之间metadata之间的同步问题。外部client请求访问Alluxio系统,然后Alluxio再从底层系统中(为称呼方便,后面都简称为Underlying FileSystem, UFS)查询真实的元数据信息,然后再返回给client。当然为了减少对于UFS的压力,我们当然不会每次都去查UFS。本文我们来聊聊Alluxio内部对此元数据同步处理的设计实现,它是最大可能性做到元数据请求处理的高效性以及数据的精准性的。
Alluxio内部的元数据同步行为
首先,这里我们需要想清楚一个基本的问题:作为一套构建于底层存储系统之上的Cache层,Alluxio内部会存在哪些元数据需要同步的情况。
从元数据同步的源头,目标来划分,总共为2类:
- 1)Alluxio内部metadata先修改,UFS后修改,此过程是从Alluxio到UFS的metadata同步。
- 2)UFS的metadata先被修改,Alluxio随后同步此修改,此过程则为从UFS到Alluxio的metadata同步。
在上述两种情形中,1)较之于2)来说同步控制更为简单一些,因为Alluxio本身作为外部请求的处理入口,它能第一时间知道请求的发生处理,然后它来自己控制后续如何做UFS底层存储系统的metadata同步。Alluxio率先更新为metadata后,对于外界来说,其元数据已经是最新状态的了。这时Alluxio可以选择灵活的策略来更新UFS中滞后的metadata了,比如它可以采用异步更新的方式或者强制同步更新的方式。归纳起来一句话,1)情况下元数据同步更新的主动权完全掌握在Alluxio系统这边。
想比较而言,元数据同步较为复杂的是第二种情况了:底层系统metadata发生改变(存在外部程序直接访问UFS导致metadata发生改变),又没有途径能够通知到Alluxio,而且Alluxio是外界请求访问的服务。
2)的情况如下图右半边图所示,1)则为下图左半图所示情形:
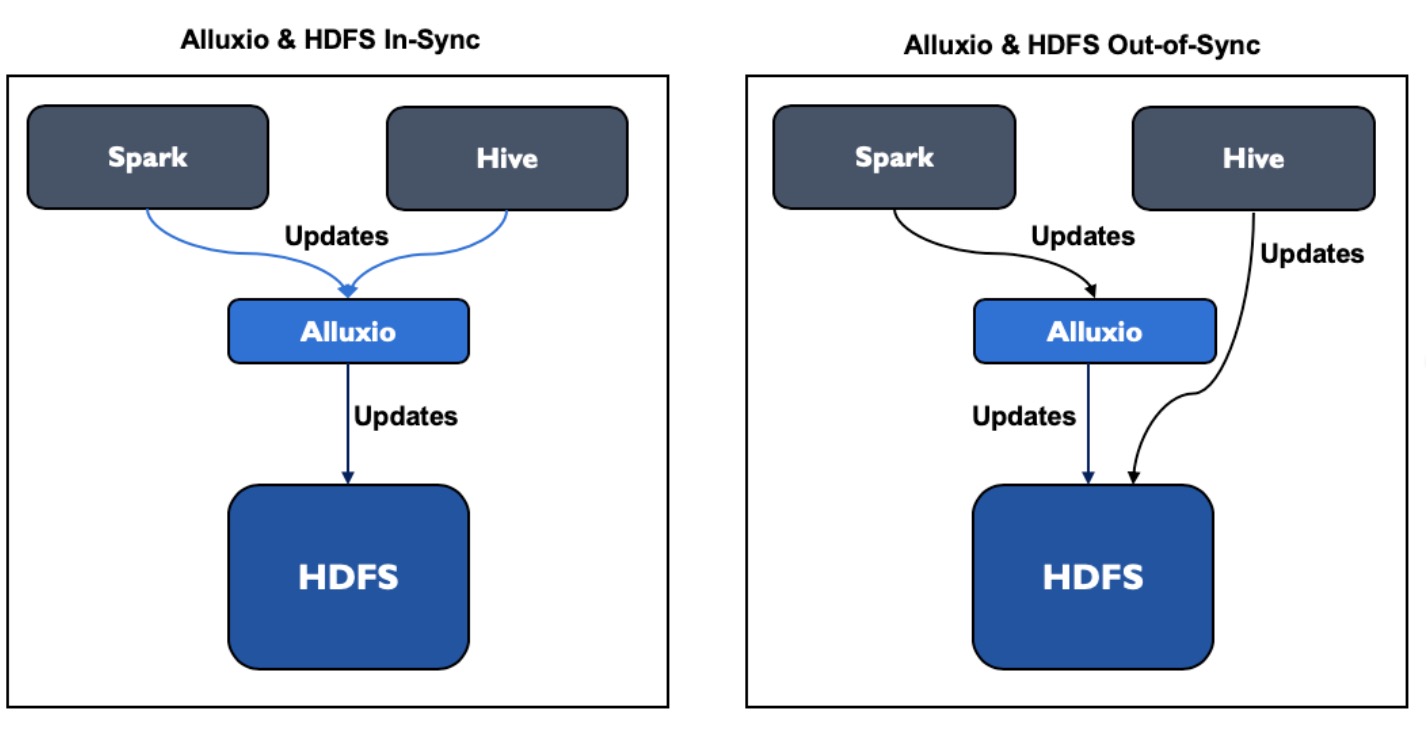
上面右半图显示的就是存在底层存储系统HDFS存在额外更新的情况,需要Alluxio去同步来自Hive这边的对HDFS的额外更新。
下面我们来看看Alluxio内部是如何解决上面这种棘手的情况的。
基于给定时间,Path粒度的UFS Status Cache
既然说存在UFS元数据意外更新的情况,为了保证Alluxio对外数据服务的准确性,我们很容易想到一种极端的做法,就是准实时地去同步HDFS中的metadata。
说到准实时的同步UFS中的metadata,就会涉及到两大核心问题:
- 多久时间的同步,time interval是设定多少,时间过短会导致大量的RPC请求查询UFS,过长又会有数据延时性的问题。
- 同步多少量的metadata,一个目录?一个文件?
针对上面2个主要问题,Alluxio内部实现了一套基于给定时间,Path粒度的UFS Status Cache实现,架构图设计如下所示:
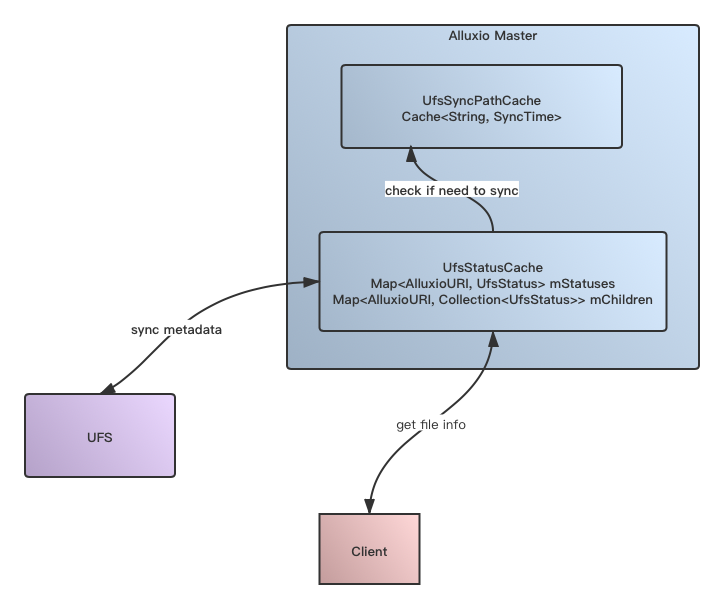
有人可能会对上图理解上有点疑惑,Alluxio本身作为Cache层,为什么还在内部又做了一层Cache?注意这里Cache的对象已经不一样了,上图Cache显示的是从UFS查询到的metadata信息。
上述步骤过程如下所述:
1)Client发起文件信息查询请求
2)Alluxio收到请求,检查其内部UFS Status Cache是否存在未过期(在cache更新时间间隔内)的对应的UFS Status,如果有则返回给Client。
3)如果没有,则发起请求到UFS,进行最新状态文件信息的查询,并加到UFS Status Cache中,同时更新此Path的Status的同步时间。
上图Alluxio内部角色介绍为:
- UfsSyncPathCache,此类用于记录那些被Cache了的Status的Path路径,此类存有各Path最近一次的metadata同步时间。
- UfsStatusCache, 此类cache了实际Path对应的metadata cache,此类同时cache了<path, ufs status>以及<path, children files status>,path对应子文件status的映射关系。其中路径对应孩子文件信息的cache是为了加速目录级别的list查询。
以下是上面这2个类的定义说明:
/**
* This cache maintains the Alluxio paths which have been synced with UFS.
*/
@ThreadSafe
public final class UfsSyncPathCache {
private static final Logger LOG = LoggerFactory.getLogger(UfsSyncPathCache.class);
/** Number of paths to cache. */
private static final int MAX_PATHS =
ServerConfiguration.getInt(PropertyKey.MASTER_UFS_PATH_CACHE_CAPACITY);
/** Cache of paths which have been synced. */
private final Cache<String, SyncTime> mCache;
...
}
/**
* This class is a cache from an Alluxio namespace URI ({@link AlluxioURI}, i.e. /path/to/inode) to
* UFS statuses.
*
* It also allows associating a path with child inodes, so that the statuses for a specific path can
* be searched for later.
*/
@ThreadSafe
public class UfsStatusCache {
private static final Logger LOG = LoggerFactory.getLogger(UfsStatusCache.class);
private final ConcurrentHashMap<AlluxioURI, UfsStatus> mStatuses;
private final ConcurrentHashMap<AlluxioURI, Future<Collection<UfsStatus>>> mActivePrefetchJobs;
// path对应children list的ufs status cache
private final ConcurrentHashMap<AlluxioURI, Collection<UfsStatus>> mChildren;
private final ExecutorService mPrefetchExecutor;
...
}
我们知道存储系统在list大目录情况时的开销是比较大的,因此上面的children file list的cache可以在一定程度上提升请求的响应速度的。
这里主要来看Alluxio是如何做基于时间粒度的metadata cache的,相关代码逻辑如下:
UfsSyncPathCache.java类
/**
* The logic of shouldSyncPath need to consider the difference between file and directory,
* with the variable isGetFileInfo we just process getFileInfo specially.
*
* There are three cases needed to address:
* 1. the ancestor directories
* 2. the direct parent directory
* 3. the difference with file and directory
*
* @param path the path to check
* @param intervalMs the sync interval, in ms
* @param isGetFileInfo the operate is from getFileInfo or not
* @return true if a sync should occur for the path and interval setting, false otherwise
*/
public boolean shouldSyncPath(String path, long intervalMs, boolean isGetFileInfo) {
if (intervalMs < 0) {
// Never sync.
return false;
}
if (intervalMs == 0) {
// Always sync.
return true;
}
// 1)从cache中取出给定path的最近一次的同步时间
SyncTime lastSync = mCache.getIfPresent(path);
// 2)判断是否同步时间已经超过过期间隔时间
if (!shouldSyncInternal(lastSync, intervalMs, false)) {
// Sync is not necessary for this path.
return false;
}
int parentLevel = 0;
String currPath = path;
while (!currPath.equals(AlluxioURI.SEPARATOR)) {
try {
// 3)如果时间超出,则进行父目录的查找,判断父目录是否达到需要更新的时间
currPath = PathUtils.getParent(currPath);
parentLevel++;
lastSync = mCache.getIfPresent(currPath);
if (!shouldSyncInternal(lastSync, intervalMs, parentLevel > 1 || !isGetFileInfo)) {
// Sync is not necessary because an ancestor was already recursively synced
return false;
}
} catch (InvalidPathException e) {
// this is not expected, but the sync should be triggered just in case.
LOG.debug("Failed to get parent of ({}), for checking sync for ({})", currPath, path);
return true;
}
}
// trigger a sync, because a sync on the path (or an ancestor) was performed recently
return true;
}
如上如果需要进行metadata的sync操作,则会触发后续的ufs status的查询然后加到UfsStatusCache中。如果涉及到目录下的文件信息的查询,为了避免可能出现查询子文件数量很多,查询较慢的情况,alluxio做成了异步线程处理的方式。
UfsStatusCache.java
/**
* Submit a request to asynchronously fetch the statuses corresponding to a given directory.
*
* Retrieve any fetched statuses by calling {@link #fetchChildrenIfAbsent(AlluxioURI, MountTable)}
* with the same Alluxio path.
*
* If no {@link ExecutorService} was provided to this object before instantiation, this method is
* a no-op.
*
* @param path the path to prefetch
* @param mountTable the Alluxio mount table
* @return the future corresponding to the fetch task
*/
@Nullable
public Future<Collection<UfsStatus>> prefetchChildren(AlluxioURI path, MountTable mountTable) {
if (mPrefetchExecutor == null) {
return null;
}
try {
Future<Collection<UfsStatus>> job =
mPrefetchExecutor.submit(() -> getChildrenIfAbsent(path, mountTable));
Future<Collection<UfsStatus>> prev = mActivePrefetchJobs.put(path, job);
if (prev != null) {
prev.cancel(true);
}
return job;
} catch (RejectedExecutionException e) {
LOG.debug("Failed to submit prefetch job for path {}", path, e);
return null;
}
}
对于纯单个文件的查询请求,Alluxio采用了简单直接的办法,每次尝试做一次sync操作,如果cache在有效期内,则实际不会做实际metadata同步行为,然后从UFS cache中load metadata返回结果。
@Override
public FileInfo getFileInfo(AlluxioURI path, GetStatusContext context)
throws FileDoesNotExistException, InvalidPathException, AccessControlException, IOException {
Metrics.GET_FILE_INFO_OPS.inc();
long opTimeMs = System.currentTimeMillis();
try (RpcContext rpcContext = createRpcContext();
FileSystemMasterAuditContext auditContext =
createAuditContext("getFileInfo", path, null, null)) {
// 执行sync metadata的操作,实际由cache interval时间控制
if (syncMetadata(rpcContext, path, context.getOptions().getCommonOptions(),
DescendantType.ONE, auditContext, LockedInodePath::getInodeOrNull,
(inodePath, permChecker) -> permChecker.checkPermission(Mode.Bits.READ, inodePath),
true)) {
// If synced, do not load metadata.
context.getOptions().setLoadMetadataType(LoadMetadataPType.NEVER);
}
LoadMetadataContext lmCtx = LoadMetadataContext.mergeFrom(
LoadMetadataPOptions.newBuilder().setCreateAncestors(true).setCommonOptions(
FileSystemMasterCommonPOptions.newBuilder()
.setTtl(context.getOptions().getCommonOptions().getTtl())
.setTtlAction(context.getOptions().getCommonOptions().getTtlAction())));
...
}
还有一种比较典型地需要load metadata的场景是文件或目录不存在于alluxio的情况。
以上就本文所要简单阐述的Alluxio与底层存储系统间元数据的同步方式,Alluxio本身作为底层存储cache层,在内部新维护了UFS的cache来做与底层UFS的status的同步。而且用户可以按照实际场景需要来设定这个cache需要同步的间隔时间。另外一方面,UFS status cache的引入也减少了list查询操作的代价,在这点上比client直接访问底层存储系统做大目录list要高效不少。
引用
[1].https://dzone.com/articles/two-ways-to-keep-files-in-sync-between-alluxio-and