免责声明
本文仅为个人学习笔记,请谨慎参考,如有错误欢迎批评指正。
参考文章
第一篇文章主要看树的重心的部分
第二篇文章才是和本题完全一致
https://blog.csdn.net/a_forever_dream/article/details/81778649
要求:
(1)用伪代码描述求树重心的算法。
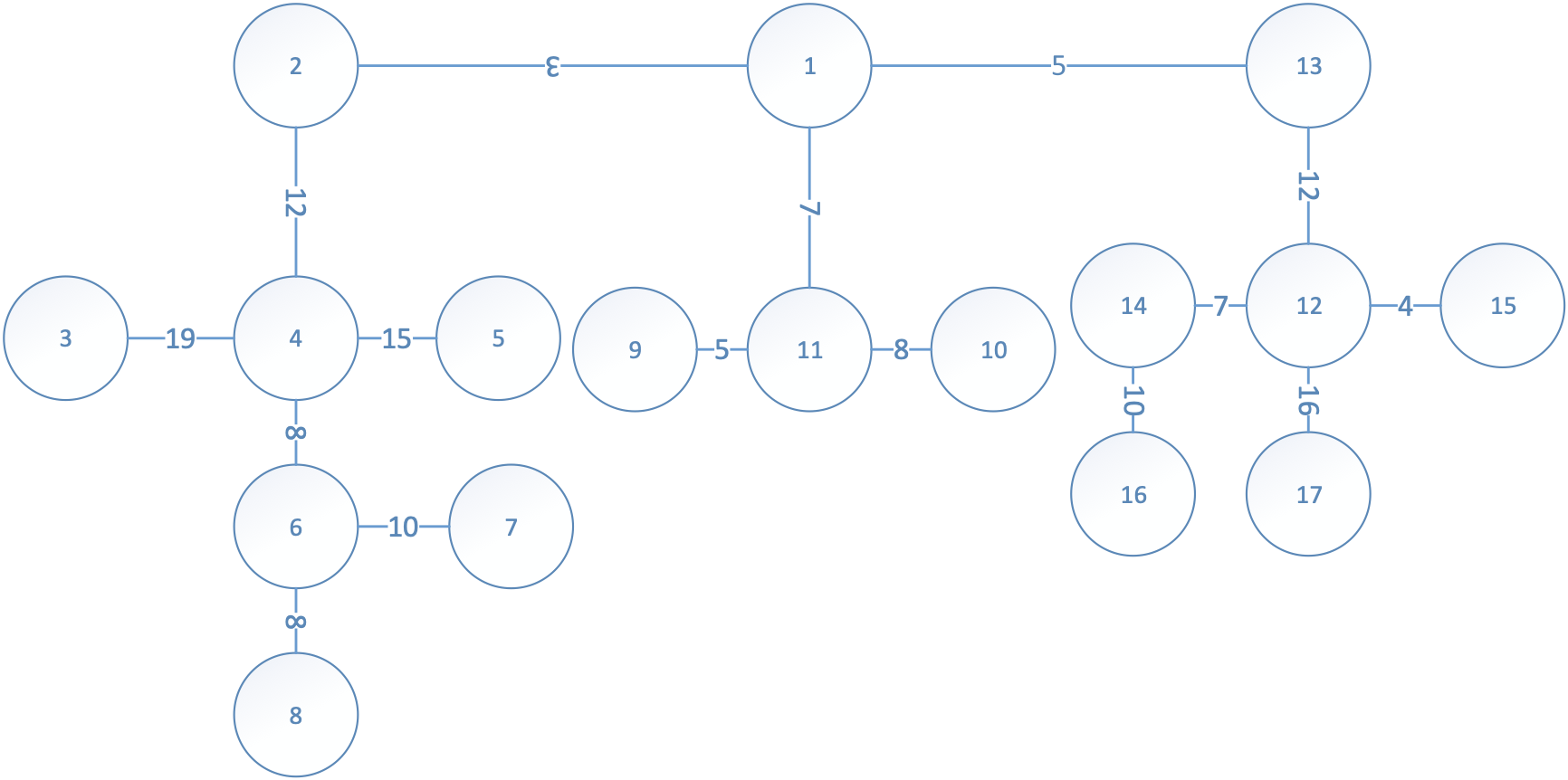
(2)将下面的树作为输入时,写出求解上述问题的求解过程以及求解结果。要求写出求解过程中主要变量的变化过程。
(3)编写程序求解该问题,并分析算法的时间复杂度。
分析
整个流程:
1、找树的重心。
2、算出每个点到重心的距离数组。
3、所有经过重心的点对数 减去 所有经过重心子结点的点对数 得到 合法点对数
4、对重心的子结点重复1、2、3的操作(递归)
1、找树的重心。
树的重心,也叫树的质心。即树的一个结点,把它删掉后的所有子树的最大结点数(相比于删掉其他结点)最小。如图所示:

要求树的重心,也许第一想法是遍历一次所有结点,把每个结点都当成重心,计算每棵子树的结点数,再来进行比较。但这种暴力法是不可取的。它会重复计算很多次相同的路径,我们可以仅扫描一次整棵树就能得到以每个点作为重心的最大子树结点数。这里要用到树的点分治法。分治法,我把它理解成后序遍历的递归调用,但是递归也只能以一个结点为起点进行递归呀,怎么能算出以所有点为起点的最大子树结点数呢?这里我们还是以上面的树为例子。用n表示整棵树的结点数,这里n=5;用size[i]代表以i为根的树的结点数;用max_child[i]代表以i为根的最大子树结点数;用min来更新max_child[i]中的最小值,它用来更新重心,min起始值是很大的数。
按照后续遍历的递归,我们首先能算出点4的size[4]=1,红色部分是n-size[4]=4个结点。之所以能这么分,是因为点4只会有一个父结点,所以红色部分始终能作为它的一棵子树。比较size[4]和n-size[4]的大小,以点4为根的最大子树结点数max_child[4]=4,min更新为max_child[4]的4。
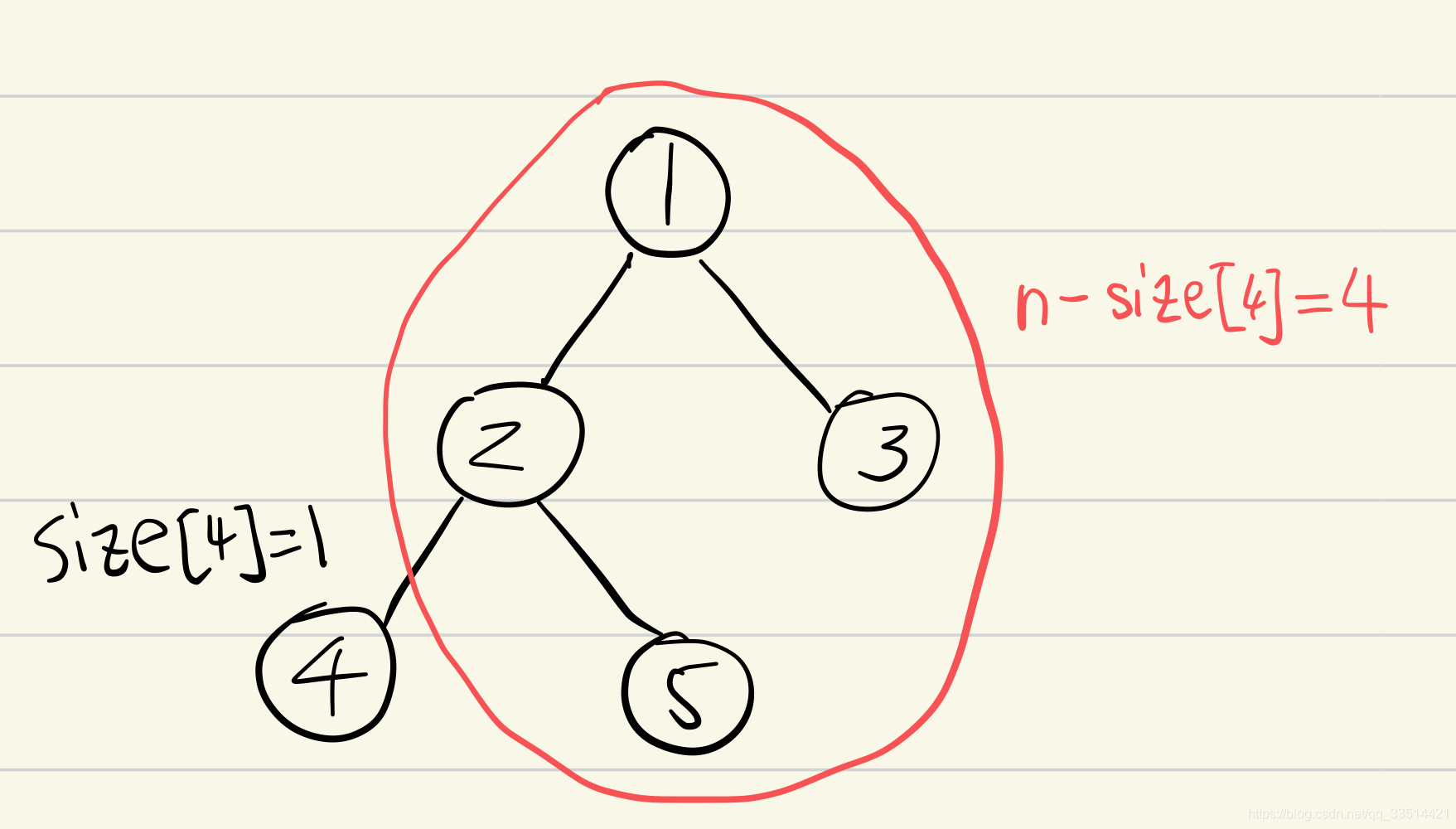
然后是算出点5的size[5]=1,也是类似点4。红色部分是n-size[5]=4个结点,以点5为根的最大子树结点数max_child[5]=4,min不变。
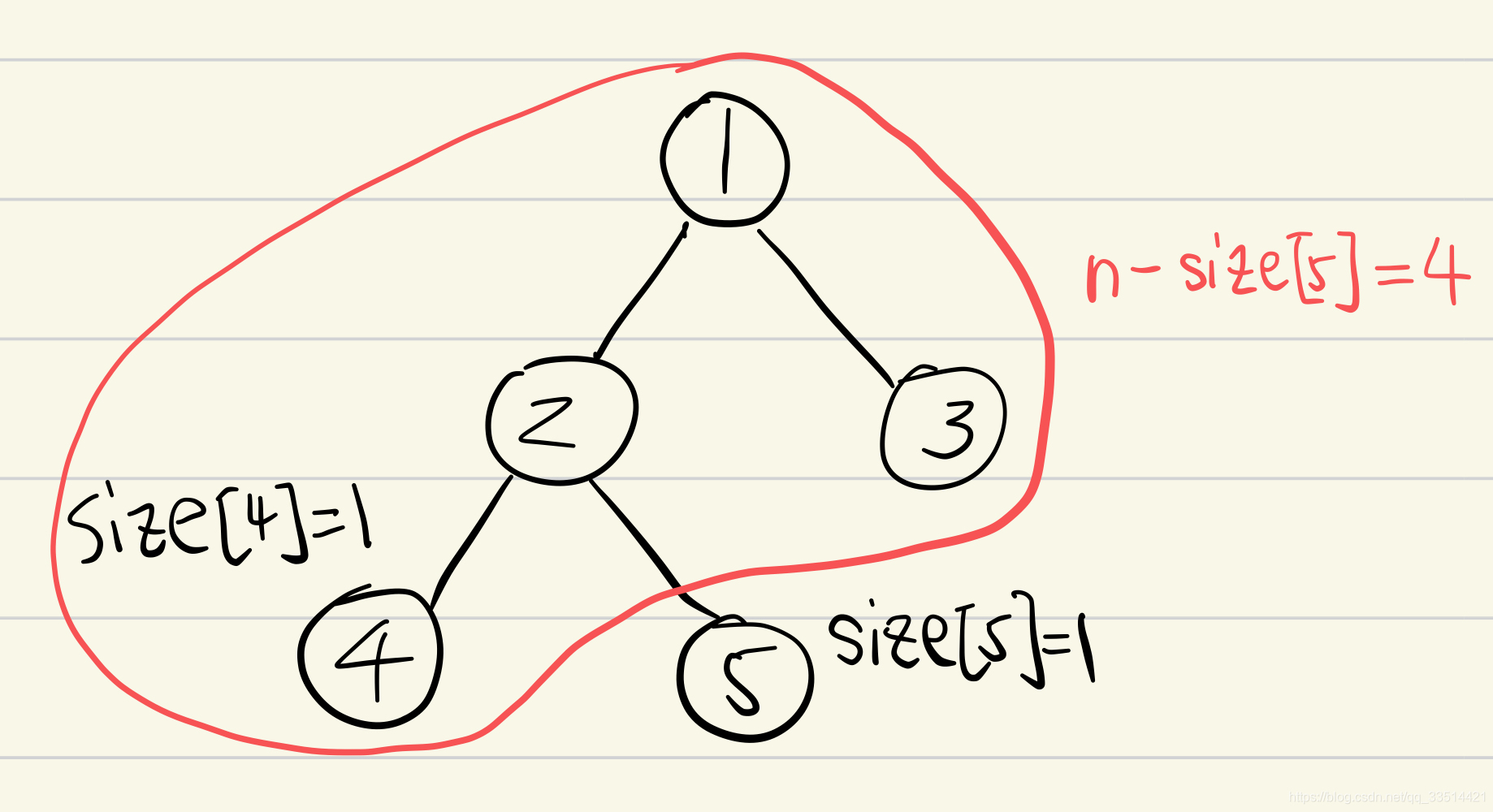
接着是算出点2,也就是它自身的1个结点,加上它的子树点4和点5的size。绿色部分为它的子树,分别为size[4]=1个结点、size[5]=1个结点,红色部分是n-size[2]=2个结点,所以以点2为根的最大子树结点数max_child[2]=2,min更新为2。
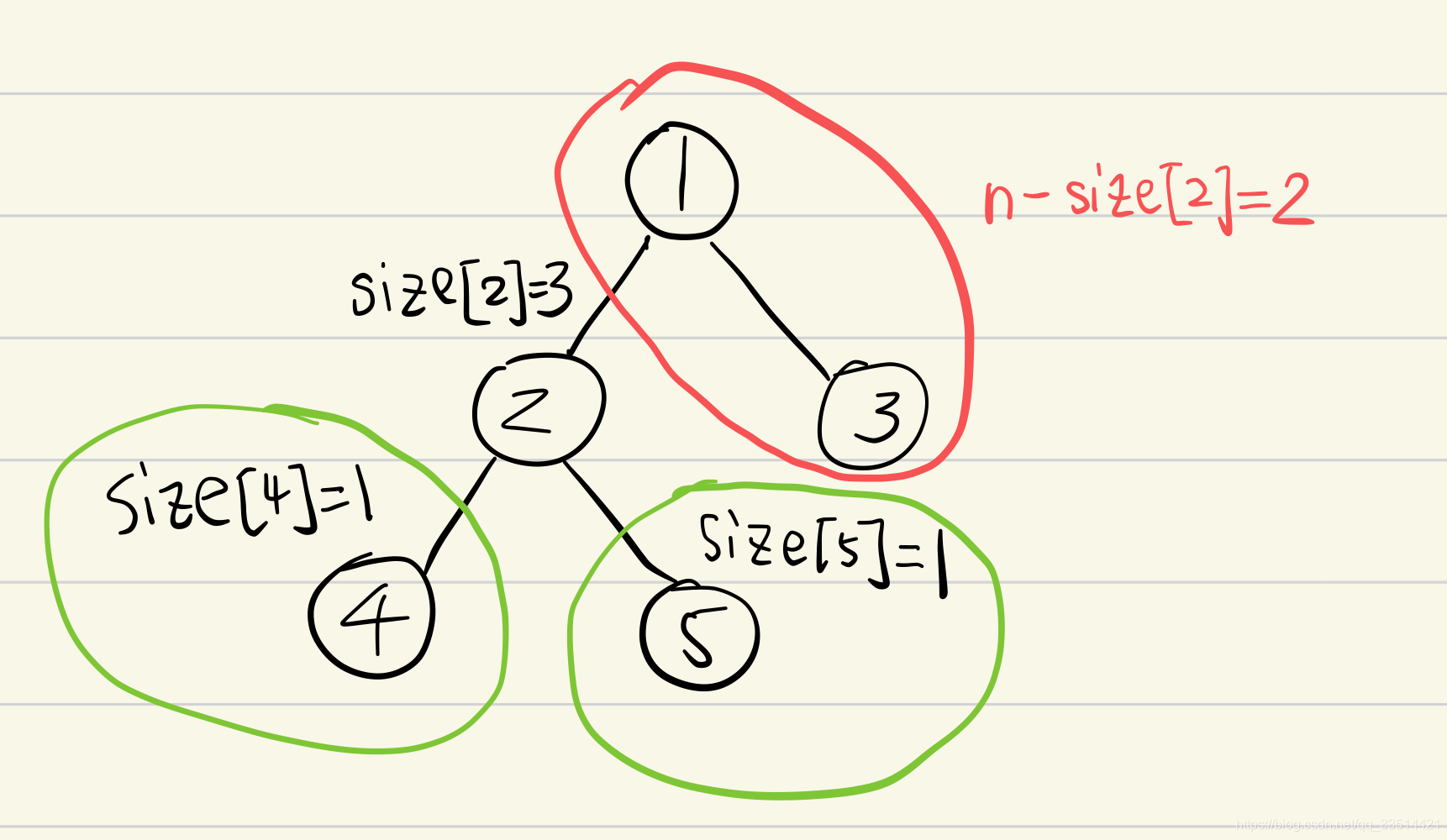
接着是算出点3,也就是它自身的1个结点。红色部分是n-size[3]=4个结点,所以以点3为根的最大子树结点数max_child[3]=4,min不变。

接着是算出点1,也就是它自身的1个结点,加上它的子树点2和点3的size。绿色部分为两棵子树,size[2]=3个结点、size[3]=1个结点。红色部分已经没有了,n-size[1]=0个结点。所以以点1为根的最大子树结点数max_child[1]=3,min不变。

min一旦更新,重心gravity也会更新为对应的结点。只是这里没写出来,看代码就知道了。
所以说,这个递归的开始点选谁不重要,选择任意点都能算出以每个点为根的最大子树结点数,进而求出重心。
求树的重心的代码如下:
// 全局变量
int n=17; // 所有结点数
int size[n];// 以n为根的树的结点数
int max_child[n];// 以n为根的树的最大子树的结点数
int min;// max_child中最小的那个
int first[n+1],edge[(n-1)*2]// 顶点表,边表
int gravity=0;// 被选为重心的结点
// 传入参数
// start 代表当前结点
// parent 代表当前结点的父结点,这里是为了防止遍历start的子结点的时候把父结点也遍历进去了
void getGravity(int start, int parent)
{
// size[start]代表当前结点的个数,初始为1是算上本身
size[start]=1;
// max_child[start]代表当前结点的最大子树结点数
max_child[start]=0;
// 遍历以start结点为起点的所有边(除去连接父结点的边)
for(int i=first[start]; i; i=edge[i].next)
{
// end为当前边的终点(也是start点的子结点)
int end=edge[i].end;
// 如果这个终点已经被遍历或者这个终点是父结点,就跳过
if(visited[end] || end==parent){
continue;
}
// 继续遍历终点的子结点,这里其实就是遍历start的一棵子树的所有结点数
getGravity(end, start);
// 遍历完这棵子树的所有结点后,把子树的结点数加起来
size[start]+=size[end];
// 如果这颗子树的结点数大于max_child,就更新它
if(size[end] > max_child[start]){
max_child[start]=size[end];
}
}
// 上面的循环是用来遍历start的每一棵子树并比较出最大子树结点
// 接下来就是算“红色部分”,也就是n-size[i]部分的结点数,并比较出最终的最大子树结点
if(n-size[start] > max_child[start]){
max_child[start]=n-size[start];
}
// 从max_child中比较出最小的,以找出重心
if(min < max_child[start]){
min=max_child[x];
gravity=start;
}
}这里对树的存储方法是,用顶点表first来存每个点,first[i]代表编号为i的结点的对应的第一条边的编号。边表edge的每一行代表一条边,包含这条边的起点、终点、权重和下一条相同起点的边。因为这些边是无向的,所以一条边在边表里存了两次。
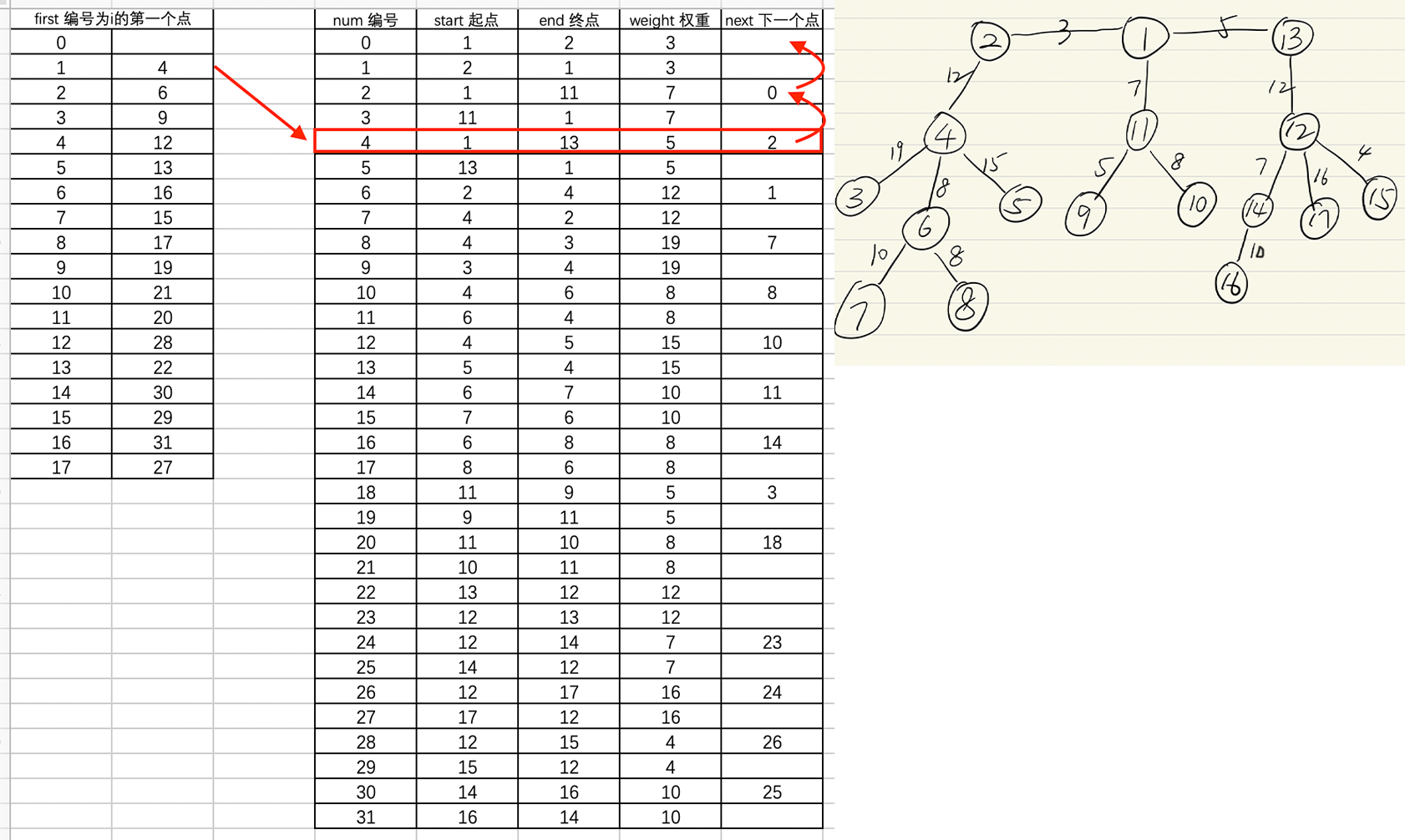
添加树结点和边的代码如下:
int first[n+1],edge[(n-1)*2]// 顶点表,边表
int num=0;
void addNodeAndEdge(int start,int end,int weight)
{
num++;// 编号,没错,要从1开始
edge[num].start=start;// 起点
edge[num].end=end;// 终点
edge[num].weight=weight;// 权重
edge[num].next=first[start];// 下一条相同起点的边
first[start]=num;// 加入顶点
}2、算出每个点到重心的距离数组。
在选出树的重心之后,我们计算所有点到这个重心的距离(即权重),也是用递归的办法。这个应该很好理解,不做过多解释。
int t=0;
// start是传入的点,parent是start的父结点,weight是start和parent连线的权重
// parent在这里是为了防止遍历start的子结点的时候把父结点也遍历进去了
// 因为每个点到start的距离是自上而下地累加,所以传入weight
// 该递归函数的主要作用是返回每个点到重心的距离,所以一开始调用递归函数的时候
// start默认是重心,parent和weight默认是0。
void getDistance(int start, int parent, int weight)
{
// dis数组保存了每个点到重心的距离(权重),为什么用t来做下标而不是点的编号呢
// 因为后面的做法只用数点对的个数,不在乎是谁到谁
// t是从1开始的
dis[++t]=weight;
for(int i=first[start]; i; i=edge[i].next)
{
int end=edge[i].end;
// 如果这个终点已经被遍历或者这个终点是父结点,就跳过
// 这点很重要,因为如果传入的start不是根结点而是根结点的子树的时候
// 它就不会把根结点再遍历一次
if(visited[end] || end==parent){
continue;
}
getDistance(end, start, weight+edge[i].weight);
}
}这一步我们拿到了dis数组,每个点到重心的距离都保存在dis里面了。再次强调,dis的下标和结点编号没关系。还是以前面的例子,如下图所示:
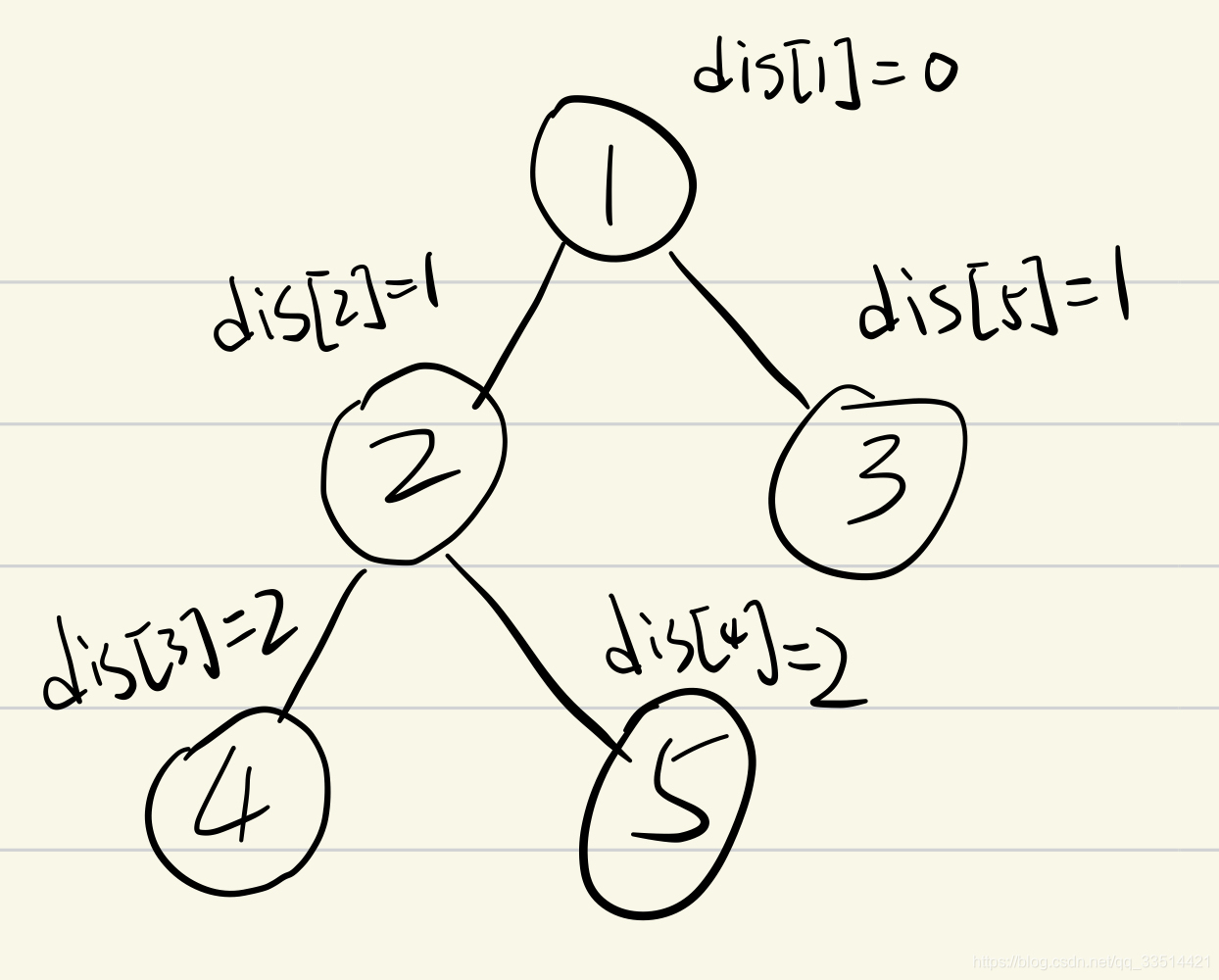
3、所有经过重心的点对数 减去 所有经过重心子结点的点对数 得到 合法点对数
接下来要考虑求长度小于K的路径数。我的第一想法是把dis中小于等于K的点找到,这样我们就选出点到重心距离小于K的点对数,然后再算经过重心且距离小于K的点对数。但是根据第二篇参考文章,并不是这样做的。引用部分第二篇参考文章:
(得到dis数组)之后,这棵子树中相连的路径会经过重心且对答案有贡献(就是距离小于k)的点对(
i,j) (i<j)就会是这样:dis[i]+dis[j] <= K且在去除重心后,i 与 j 不在同一个联通块里。不过显然要满足“不在同一个联通块里”这个条件有点突兀,于是就有了一个小技巧:先不管在不在一个联通块这个条件,算出当前这棵树的符合路径数,之后再将得出的个数减去 以重心的儿子节点为根的子树内 的 点对 路径距离(经过重心)小于等于K的个数,就行了。
它的意思就是我们现在有了每个点到重心的距离之后,我们把dis按照从小到大排序(排序是为了好算出比K小的点对),进行两两相加,把除了重心外的点全部组合,比如:
dis[2]+dis[5]对应2——1——3;
dis[3]+dis[5]对应4——2——1——3;
但是有一种情况是不妙的,比如dis[3]+dis[4]对应4——2——1——2——5。
点4和点5他们之间本来是不用经过重心点1,这怎么排除掉呢?首先找出这种点对的特点。很容易发现,这种点对它们都在一个子树中。4和5都会通过2与重心连接。也就是说,一个点对如果要经过重心的孩子结点,那么它们就是不合法的。有了这个判断条件,我们就可以进行排除。
明白排除的方法之后,现在来讲work函数。它的传入参数是结点start和start到父结点的距离(权重)。
它是用来计算经过start点的所有组合(合法和不合法的都算进去)。在第一次dfs函数中,我们有了重心。work函数,会被重心调用一次,传入的start是重心,weight为0,算出所有经过重心的点对。回到dfs中,遍历重心的所有孩子结点,分别调用一次work,传入的start是孩子结点,weight为孩子结点到重心的权重,算出所有经过当前孩子结点的点对,虽然是经过孩子结点的点对,但是算的距离还是到重心的。因为不管是经过重心的点对,还是经过孩子结点的点对,它们都要和k进行比较,所以它们算的距离都应该是到重心的。
// 传入的start要么是重心,weight=0
// 要么是重心的孩子结点,weight是重心与孩子结点的距离(权重)
int work(int start,int weight) {
t=0;
// 如果start是重心,算出 以重心为根的树中的结点 到start的距离,然后两两组合,选出加起来小于k的点对
// 如果start是重心的孩子结点,算出 以该孩子结点为根 的子树中的结点 到重心的距离,然后两两组合,选出加起来小于k的点对
// eg:重心是S的孩子结点是a,那么算出的点对数是 以a为根的树 的所有结点 两两组合,但是距离算的是 所有结点 到S的距离,因为仍然要判断小于k,和经过重心的点对要一致
// getDistance需要传入weight就是为了 重心的孩子结点的 孩子结点的 dis是到重心的距离
getDistance(start, 0, weight);
// 得到dis数组后,对其进行从小到大排序
// 注意,这里的t已经不是0了,它是全局变量,在getDistance里面遍历了start出发的所有结点
sort(dis+1,dis+1+t);
// pair_num表示经过重心的点对数量
int pair_num=0;
int i=1,j=t;
// 这个while循环就是把两个dis相加的和小于等于K的点对数量计算出来
while (i<j){
while (i<j && dis[i]+dis[j]>K)
j--;
pair_num+=j-i;
i++;
}
return pair_num;
}4、对重心的子结点重复1、2、3的操作(递归)
第一次dfs函数往往随意传入一个结点,找出整棵树的重心,比如就是上图的点1。在这里面,它会用点1调用work函数,求出经过点1的所有点对数ans,包括合法和不合法的。接着在for循环中遍历点1的孩子结点,就是上图的点2和点3,则用点2,点3分别再调用一次work,分别求出经过点2和点3的所有点对数,再用ans减去,就得到合法点对。
也许你会觉得,本来4和5是满足小于k的点对,这里减去了不就没有了?所以减去之后,又要将点2和点3分别传入dfs进行递归,里面会把点4和点5的对给算上。ans是全局变量,会在第一次dfs之后继续进行累加和累减。
// 起始点是start,递归调用会dfs所有的结点
void dfs(int start){
// 以start为起点找到重心
// 注意,虽然一开始我们说了从树的任何一个点开始遍历都能找出一个确定的重心,
// 但是这里从start开始,如果它有父结点,就不要再遍历的,只找以它为根的树的重心
getGravity(start,0);
// 用这个重心算出所有跨过该重心的路径数
ans += work(gravity,0);
// 标记这个重心已访问
visited[gravity]=1;
// 从重心开始访问子结点
for(int i=first[start]; i; i=edge[i].next){
int end=edge[i].end;
if (visited[end]){
continue;
}
// 减去以子结点为根的树的所有跨过子结点的路径数
ans -= work(end, edge[i].weight);
// 从子结点开始继续递归
dfs(end);
}
return;
}然后放上main函数:
int main()
{
// 输入结点个数
scanf("%d",&n);
// 输入每个结点的信息
for(int i=1;i<n;i++)
{
int start, end, weight;
scanf("%d %d %d",&start,&end,&weight);
addNodeAndEdge(start,end,weight);
addNodeAndEdge(end,start,weight);
}
dfs(1);
printf("%d\n", ans);
return 0;
}最后是整体代码,没有进行测试过,主要是没时间了,但是也完全理解代码了,足够应试。
#include <stdio.h>
#define MAX 10000;
// 全局变量
int n; // 所有结点数
int size[n],max_child[n],min=MAX;// 以n为根的树的结点数,以n为根的树的最大子树的结点数
int first[n+1],edge[(n-1)*2]// 顶点表,边表
int visited[n+1];// 标记已访问过的点
int dis[];// 每个点到重心的距离
int gravity=0;// 重心
int num=0,t=0;// 结点编号
int ans=0;// 最终结果:小于等于K的点对数量
void addNodeAndEdge(int start, int end, int weight)
{
num++;// 编号
edge[num].start=start;// 起点
edge[num].end=end;// 终点
edge[num].weight=weight;// 权重
edge[num].next=first[start];// 下一条相同起点的边
first[start]=num;// 加入顶点
}
// 传入重心,以及重心和它的父结点之间的权重
int work(int start,int weight) {
t=0;
// 算出start到各个结点的距离
getDistance(start, 0, weight);
// 得到dis数组后,对其进行从小到大排序
// 注意,这里的t已经不是0了,它是全局变量,在getDistance里面遍历了start出发的所有结点
sort(dis+1,dis+1+t);
// pair_num表示点对数量
int pair_num=0;
int i=1,j=t;
// 这个while循环就是把两个dis相加的和小于等于K的点对数量计算出来
while (i<j){
while (i<j && dis[i]+dis[j]>K) j--;
pair_num+=j-i;
i++;
}
return pair_num;
}
void getDistance(int start, int parent, int weight)//fa表示x的父亲,z表示x到目标点的距离
{
// dis数组保存了每个点到重心的距离(权重),为什么用t来做下标而不是点的编号呢
// 因为后面的做法只用数点对的个数,不在乎是谁到谁
dis[++t]=weight;
for(int i=first[start]; i; i=edge[i].next)
{
int end=edge[i].end;
// 如果这个终点已经被遍历或者这个终点是父结点,就跳过
// 这点很重要,因为如果传入的start不是根结点而是根结点的子树的时候
// 它就不会把根结点再遍历一次
if(visited[end] || end==parent){
continue;
}
getDistance(end, start, weight+edge[i].weight);
}
}
// 传入参数
// start 代表当前结点
// parent 代表当前结点的父结点,这里是为了防止遍历start的子结点的时候把父结点也遍历进去了
void getGravity(int start, int parent)
{
// size[start]代表当前结点的个数,初始为1是算上本身
size[start]=1;
// max_child[start]代表当前结点的最大子树结点数
max_child[start]=0;
// 遍历以start结点为起点的所有边(除去连接父结点的边)
for(int i=first[start]; i; i=edge[i].next)
{
// end为当前边的终点(也是start点的子结点)
int end=edge[i].end;
// 如果这个终点已经被遍历或者这个终点是父结点,就跳过
if(visited[end] || end==parent){
continue;
}
// 继续遍历终点的子结点,这里其实就是遍历start的一棵子树的所有结点数
getGravity(end, start);
// 遍历完这棵子树的所有结点后,把子树的结点数加起来
size[start]+=size[end];
// 如果这颗子树的结点数大于max_child,就更新它
if(size[end] > max_child[start]){
max_child[start]=size[end];
}
}
// 上面的循环是用来遍历start的每一棵子树并比较出最大子树结点
// 接下来就是算“红色部分”,也就是n-size[i]部分的结点数,并比较出最终的最大子树结点
if(n-size[start] > max_child[start]){
max_child[start]=n-size[start];
}
// 从max_child中比较出最小的,以找出重心
if(min < max_child[start]){
min=max_child[x];
gravity=start;
}
}
// 递归地求每个树的经过重心的点对数量
// 起始点是start
void dfs(int start){
// 以start为起点找到重心
// 注意,虽然一开始我们说了从树的任何一个点开始遍历都能找出一个确定的重心,
// 但是这里的意思是,从start开始,它的父结点就不要再遍历的,只找它和它的子树的重心
getGravity(start,0);
// 用这个重心算出所有跨过该重心的路径数
ans += work(gravity,0);
// 标记这个重心已访问
visited[gravity]=1;
// 从重心开始访问子结点
for(int i=first[start]; i; i=edge[i].next){
int end=edge[i].end;
if (visited[end]){
continue;
}
// 减去以子结点为根的树的所有跨过子结点的路径数
ans -= work(end, edge[i].weight);
// 以子结点为根的树继续求重心、所有跨过路径数
dfs(end);
}
return;
}
int main()
{
// 输入结点个数
scanf("%d",&n);
// 输入每个结点的信息
for(int i=1;i<n;i++)
{
int start, end, weight;
scanf("%d %d %d",&start,&end,&weight);
addNodeAndEdge(start,end,weight);
addNodeAndEdge(end,start,weight);
}
dfs(1);
printf("%d\n", ans);
return 0;
}时间复杂度暂时没算。。。