时间序列
01时间序列模型
介绍:
时间序列是按时间顺序排列的、随时间变化且相互关联的数据序列。分析时间序列的方法构成数据分析的一个重要领域,即时间序列分析。时间序列根据所研究的依据不同,可有不同的分类。
1.按所研究的对象的多少分,有一元时间序列和多元时间序列。
2.按时间的连续性可将时间序列分为离散时间序列和连续时间序列两种。
3.按序列的统计特性分,有平稳时间序列和非平稳时间序列。如果一个时间序列的概率分布与时间t无关,则称该序列为严格的平稳时间序列。如果序列的一、二阶矩存在,而且对任意时刻 t 满足:(1)均值为常数;(2)协方差为时间间隔τ的函数。则称该序列为宽平稳时间序列,也叫广义平稳时间序列。我们所研究的时间序列主要是宽平稳时间序列。
4.按时间序列的分布规律来分,有高斯型时间序列和非高斯型时间序列。
确定性时间序列分析方法:
时间序列预测技术就是通过对预测目标自身时间序列的处理,来研究其变化趋势的。一个时间序列往往是以下几类变化形式的叠加或耦合。
(1)长期趋势变动。它是指时间序列朝着一定的方向持续上升或下降,或停留在某一水平上的倾向,它反映了客观事物的主要变化趋势。
(2)季节变动。
(3)循环变动。通常是指周期为一年以上,由非季节因素引起的涨落起伏波形相似的波动。
(4)不规则变动。通常它分为突然变动和随机变动。

02移动平均发
移动平均法:移动平均法是根据时间序列资料逐渐推移,依次计算包含一定项数的时序平均数,以反映长期趋势的方法。当时间序列的数值由于受周期变动和不规则变动的影响,起伏较大,不易显示出发展趋势时,可用移动平均法,消除这些因素的影响,分析、预测序列的长期趋势。移动平均法有简单移动平均法,加权移动平均法,趋势移动平均法等。


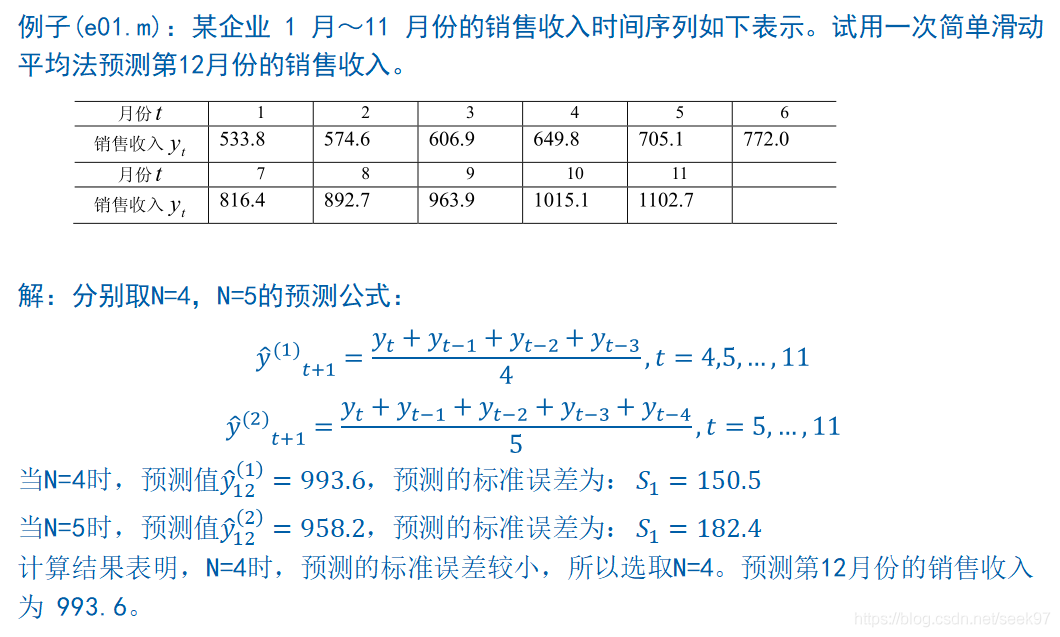
clc,clear
y=[533.8 574.6 606.9 649.8 705.1 772.0 816.4 892.7 963.9 1015.1 1102.7];
m=length(y);
n=[4,5]; %n 分别取4和5
for i=1:length(n)
%循环序列,求平均
for j=1:m-n(i)+1
yhat{i}(j)=sum(y(j:j+n(i)-1))/n(i);
end
y12(i)=yhat{i}(end);
s(i)=sqrt(mean((y(n(i)+1:m)-yhat{i}(1:end-1)).^2));
end
y12,s结果:
y12 =
993.6000 958.1600
s =
150.5121 182.3851简单移动平均法只适合做近期预测,而且是预测目标的发展趋势变化不大的情况。如果目标的发展趋势存在其它的变化,采用简单移动平均法就会产生较大的预测偏差和滞后。在简单移动平均公式中,每期数据在求平均时的作用是等同的。但是,每期数据所包含的信息量不一样,近期数据包含着更多关于未来情况的信心。因此,把各期数据等同看待是不尽合理的,应考虑各期数据的重要性,对近期数据给予较大的权重,这就是加权移动平均法的基本思想。

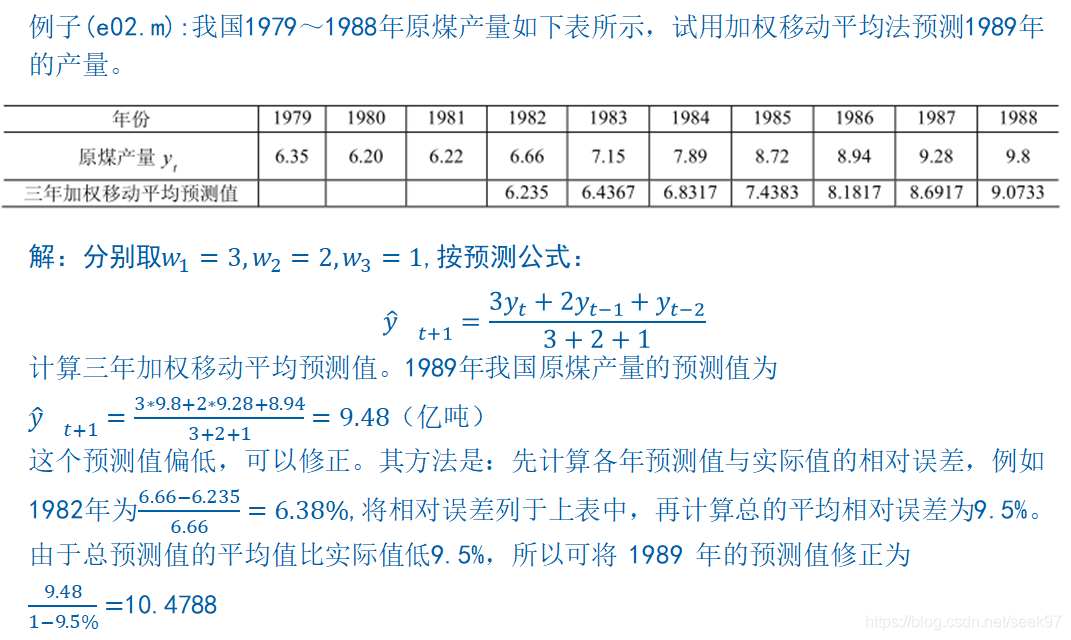
y=[6.35 6.20 6.22 6.66 7.15 7.89 8.72 8.94 9.28 9.8];
w=[1/6;2/6;3/6];
m=length(y);n=3;
yhat=zeros(1,m-n+1);
for i=1:m-n+1
yhat(i)=y(i:i+n-1)*w;
end
yhat
err=abs(y(n+1:m)-yhat(1:end-1))./y(n+1:m)
T_err=1-sum(yhat(1:end-1))/sum(y(n+1:m))
y1989=yhat(end)/(1-T_err)结果:
>> e02
yhat =
6.2350 6.4367 6.8317 7.4383 8.1817 8.6917 9.0733 9.4833
err =
0.0638 0.0998 0.1341 0.1470 0.0848 0.0634 0.0741
T_err =
0.0950
y1989 =
10.4788
简单移动平均法和加权移动平均法,在时间序列没有明显的趋势变动时,能够准确反映实际情况。但当时间序列出现直线增加或减少的变动趋势时,用简单移动平均法和加权移动平均法来预测就会出现滞后偏差。因此,需要进行修正,修正的方法是作二次移动平均,利用移动平均滞后偏差的规律来建立直线趋势的预测模型。这就是趋势移动平均法。
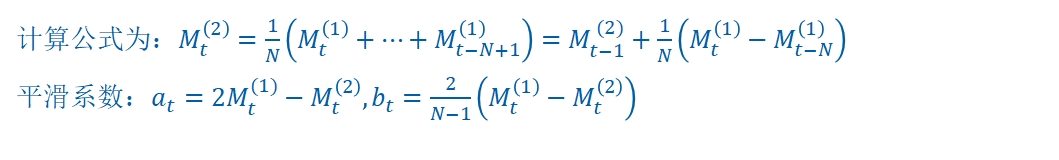
例子(e03.m):我国1965~1985年的发电总量如下表所示,试预测1986年和1987年的发电总量。
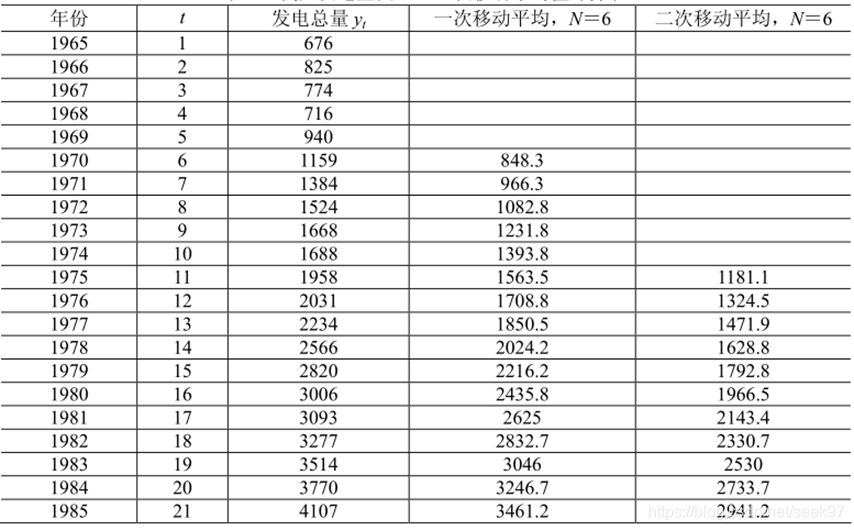
clc,clear
load y.txt %加载发电量
m1=length(y);
n=6; %n 前6个值取平均
for i=1:m1-n+1
yhat1(i)=sum(y(i:i+n-1))/n;
end
yhat1
m2=length(yhat1);
for i=1:m2-n+1
yhat2(i)=sum(yhat1(i:i+n-1))/n;
end
yhat2
plot(1:21,y,'*')
a21=2*yhat1(end)-yhat2(end)
b21=2*(yhat1(end)-yhat2(end))/(n-1)
y1986=a21+b21
y1987=a21+2*b21结果:
yhat1 =
1.0e+03 *
1 至 11 列
0.8483 0.9663 1.0828 1.2318 1.3938 1.5635 1.7088 1.8505 2.0242 2.2162 2.4358
12 至 16 列
2.6250 2.8327 3.0460 3.2467 3.4612
yhat2 =
1.0e+03 *
1.1811 1.3245 1.4719 1.6288 1.7928 1.9665 2.1434 2.3307 2.5300 2.7337 2.9412
a21 =
3.9811e+03
b21 =
207.9778
y1986 =
4.1891e+03
y1987 =
4.3971e+03 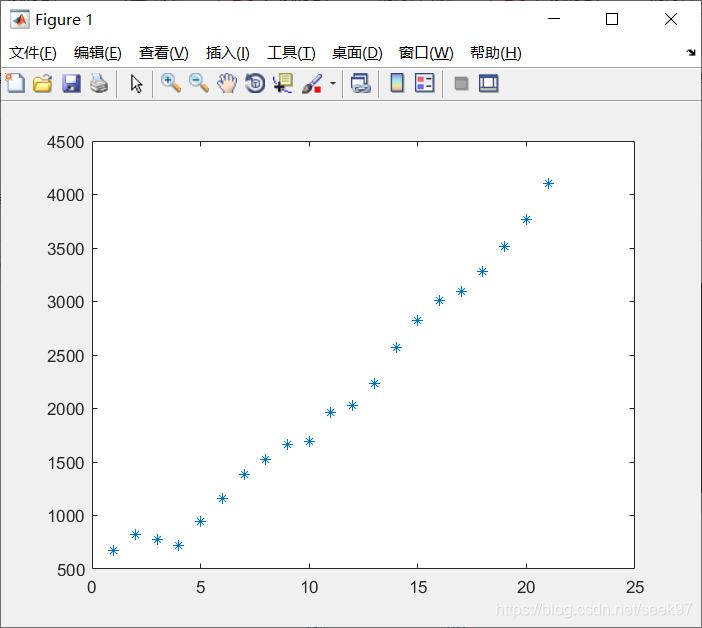

03指数平滑法




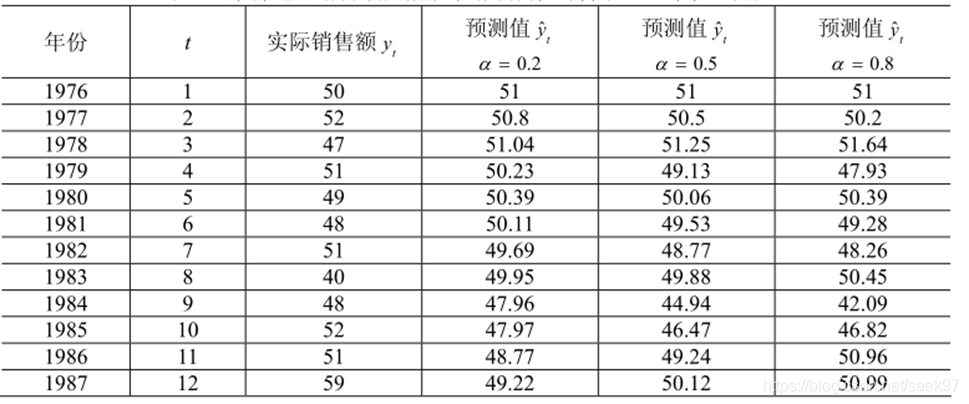
例子(e04.m):某市 1976~1987 年某种电器销售额如下表所示。试预测 1988 年该电器销售额。



clc,clear
load dianqi.txt %加载实际销售额
yt=dianqi; n=length(yt);
alpha=[0.2 0.5 0.8];m=length(alpha);
yhat(1,1:m)=(yt(1)+yt(2))/2;
for i=2:n
yhat(i,:)=alpha*yt(i-1)+(1-alpha).*yhat(i-1,:);
end
yhat
err=sqrt(mean((repmat(yt,1,m)-yhat).^2))
yhat1988=alpha*yt(n)+(1-alpha).*yhat(n,:)结果:
yhat =
51.0000 51.0000 51.0000
50.8000 50.5000 50.2000
51.0400 51.2500 51.6400
50.2320 49.1250 47.9280
50.3856 50.0625 50.3856
50.1085 49.5313 49.2771
49.6868 48.7656 48.2554
49.9494 49.8828 50.4511
47.9595 44.9414 42.0902
47.9676 46.4707 46.8180
48.7741 49.2354 50.9636
49.2193 50.1177 50.9927
err =
4.5029 4.5908 4.8426
yhat1988 =
51.1754 54.5588 57.3985