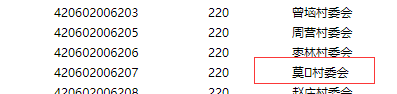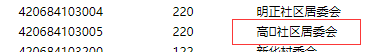为了项目后续数据需要做准备,开始渐进深入去学习爬虫,最近做了一个实战样例demo,写了一个爬虫,获取全国统计用区划代码。数据来源,国家统计局:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/
整体分析一下,这个网站的布局样式简直不忍直视,可以说是一览无遗,基本上啥都没有,突出了政府网站一贯的简洁高效风格。
我将按照代码顺序,差穿插着说明开发思路过程。
代码目录:
数据库表设计:
CREATE TABLE `nbs_region` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`nbs_code` varchar(20) DEFAULT NULL COMMENT '国家统计局统计用区划code',
`nbs_parent_code` varchar(20) DEFAULT NULL COMMENT '国家统计局父级统计用区划code',
`nbs_level` varchar(16) DEFAULT NULL COMMENT '国家统计局区域层级',
`nbs_name` varchar(128) DEFAULT NULL COMMENT '国家统计局名称',
`nbs_town_country_code` varchar(10) DEFAULT NULL COMMENT '国家统计局城乡分类代码【五级才有值】',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '数据记录创建时间',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '数据记录修改时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `nbs_code` (`nbs_code`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='国家统计局全国五级行政区划【http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/】';
先介绍下用到的基础python文件。
Bean包下两个类,NbsRegionDTO用于存放爬取解析后的数据,便于最后存库,字段和数据库对应。
'''
国家统计局行政区划实体类
'''
class NbsRegionDTO:
# 统计用区划代码
nbs_code = ''
#'国家统计局父级统计用区划code',
nbs_parent_code = ''
# '国家统计局区域层级', 1 - 5
nbs_level = 0
# '国家统计局名称',
nbs_name = ''
# 城乡分类代码 五级才有数据
nbs_town_country_code = ''
#定义构造方法
def __init__(self,nbs_code,nbs_parent_code,nbs_level,nbs_name,nbs_town_country_code):
self.nbs_code = nbs_code
self.nbs_parent_code = nbs_parent_code
self.nbs_level = nbs_level
self.nbs_name = nbs_name
self.nbs_town_country_code = nbs_town_country_code
ParseErrorClass 用于封装爬取过程中出现问题的数据信息,便于最后集中处理。'''
解析暂时出现异常的数据实体类
'''
class ParseErrorClass:
# 当前 父节点code
parent_code = ''
# 当前 父节点区划等级
parent_level = 0
# 当前待解析url
to_parse_url = ''
# 定义构造方法
def __init__(self, parent_code, parent_level, to_parse_url):
self.parent_code = parent_code
self.parent_level = parent_level
self.to_parse_url = to_parse_url
util包下有两个工具类文件
UrlGetUtil 用于抓取相关url页面,里面提供两种方法,request.get() 和 urlopen() ,两种方式都是可行的。
import sys
from urllib.request import urlopen
from pip._vendor import requests
'''
工具类
'''
class UrlGetUtil:
'''
url 待抓取url
tarBianMa 目标编码,eg: 'gbk'
'''
def getByRequestGet(self,url,tarBianMa):
response = requests.get(url)
#print(response.encoding) #查看现有编码
response.encoding = tarBianMa # 改变编码
#print(response.encoding)#查看改变后的编码
html = response.text
return html
'''
url 待抓取url
tarBianMa 目标编码,eg: 'gbk'
'''
def getByUrlOpen(self,url,tarBianMa):
#10s超时
html_obj = urlopen(url,timeout = 10)
html = html_obj.read().decode(tarBianMa)
return htmlDataBaseUtil 提供两个方法,用于获取连接对象和光标对象import pymysql
'''
数据库操作工具类
'''
class DataBaseUtil:
'''获取连接对象'''
def getConnObj(self,host_param,unix_socket_param,user_param,passwd_param,db_param):
conn = pymysql.connect(host=host_param,unix_socket=unix_socket_param,user=user_param,passwd=passwd_param,db=db_param,charset='utf8')
return conn
'''
获取光标对象
参数:连接对象conn
'''
def getCurObj(self,conn):
return conn.cursor()
另外还有三个文件,NbsMain是程序运行入口,NbsCycleSpider用于深层次递归爬取下级行政区划数据,SaveData用于存储数据到数据库。
★SaveData中主要就是一个批量插入数据到mysql的方法。
1,方法参数传进来是一个集合,里面存放一个个封装好的数据NbsRegionDTO对象,为了便于后面批量插入,先把集合参数tar_obj_set处理转成列表套元组的形式。
2,准备数据库连接参数,用户名,密码,数据库,ip等老几样数据,获取连接对象和光标对象。
3,执行sql,关于批量插入的注意事项,代码中的注释有详述
4,最后,记得关闭连接和光标,防止泄露。
'''
国家统计局 数据入库存储
'''
from NbsRegionSpider.Util.DataBaseUtil import DataBaseUtil
#批量插入
def nbsDataToSaveBatch(tar_obj_set):
#参数处理成列表套元组的形式
tar_list = list() #或 tar_list = []
for tar_obj in tar_obj_set:
tar_tuple = (tar_obj.nbs_code,tar_obj.nbs_parent_code,tar_obj.nbs_level,tar_obj.nbs_name,tar_obj.nbs_town_country_code)
tar_list.append(tar_tuple)
# 数据库信息
dataBaseUtilObj = DataBaseUtil()
host_param = 'xxxx.xx.xx.xx'
unix_socket_param = ''
user_param = 'root'
passwd_param = 'xxxxx'
db_param = 'qqq'
conn = dataBaseUtilObj.getConnObj(host_param,unix_socket_param,user_param,passwd_param,db_param)
cur = dataBaseUtilObj.getCurObj(conn)
#执行sql
cur.execute("use qqq")
# 注意这里使用的是executemany而不是execute,下边有对executemany的详细说明
'''
另外,针对executemany
execute(sql) : 接受一条语句从而执行
executemany(templet,args):能同时执行多条语句,执行同样多的语句可比execute()快很多,强烈建议执行多条语句时使用executemany
templet : sql模板字符串, 例如 ‘insert into table(id,name,age) values(%s,%s,%s)’
args: 模板字符串中的参数,是一个list,在list中的每一个元素必须是元组!!! 例如: [(1,‘mike’),(2,‘jordan’),(3,‘james’),(4,‘rose’)]
'''
cur.executemany('insert into nbs_region(nbs_code,nbs_parent_code,nbs_level,nbs_name,nbs_town_country_code) values (%s,%s,%s,%s,%s)',tar_list)
conn.commit()
cur.close()
conn.close()★NbsMain:
基本逻辑
在NbsMain中解析省一级数据,然后在NbsCycleSpider中递归该省的下级数据的深度爬虫,把每一层的爬取结果集合,返回到上一级,再同本级结果集合取并集来合并所有结果,同时把出现爬取异常的数据暂存到错误数据集合全局变量error_data_set,最终返回爬取结果集到NbsMain中,然后执行该省数据的存储入库,然后循环下一个省份的处理。最后再处理上述过程中产生的错误数据集合error_data_set,进行重试爬取并入库,进行循环,每次循环,创建一个error_data_set_second 来保存出现的错误数据,本次数据入库后,更新error_data_set = error_data_set_second,直到最后,error_data_set容量为0 为止。
之所以不直接操作error_data_set 而是每次用一个新的error_data_set_second,是为了避免再迭代error_data_set的时候,又对其进行删除、添加的操作,导致出现迭代异常。
import time
from urllib.request import urlopen
from bs4 import BeautifulSoup
from NbsRegionSpider.Bean.NbsRegionDTO import NbsRegionDTO
from NbsRegionSpider.NbsCycleSpider import cycleSpider
from NbsRegionSpider.SaveData import nbsDataToSaveBatch
from NbsRegionSpider.Util.UrlGetUtil import UrlGetUtil
'''国家统计局省级区域数据爬取 程序入口'''
base_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
urlGetUtilObj = UrlGetUtil()
#两种方式二选一来爬取url页面
#urlopern方式
html = urlGetUtilObj.getByUrlOpen(base_url,'gbk')
# request.get 方式
#html = urlGetUtilObj.getByRequestGet(base_url,'gbk')
'''
异常:Some characters could not be decoded, and were replaced with REPLACEMENT CHARACTER.
https://www.cnblogs.com/HANYI7399/p/6080070.html
'''
#bs = BeautifulSoup(html, 'html.parser', from_encoding = "iso-8859-1")
bs = BeautifulSoup(html,'html.parser')
#找出存放省信息的tr行
trs = bs.findAll('tr',{'class':'provincetr'})
#先取出所有的省数据节点
data_item_set = set()
for tr in trs:
tds = tr.findAll('td')
for td in tds:
a_flag = td.a
if a_flag is None:
continue
data_item_set.add(a_flag)
#全局变量,存储爬取过程中出现错误的数据
error_data_set = set()
# 每一轮节点的循环都是对一个省的数据处理
for a_flag in data_item_set:
# 本省所有行政区划结果集
tar_obj_set = set()
#解析数据
province_name = a_flag.get_text()# 获取省名称
print('-'*12 +province_name+'---爬取开始'+ '-'*12)
province_code = ''
to_spider_url = a_flag['href']
if len(province_name) == 0:
continue
if len(to_spider_url) != 0:
province_code = ''.join(filter(str.isdigit, to_spider_url))#列表转字符串,获取省一级code
# 省一级数据封装成实体
tarObj = NbsRegionDTO(province_code,'',1,province_name,'')
grade_2_url = base_url + to_spider_url #基础路径拼接当前路径 相当于 下一级的url解析路径
tar_obj_set.add(tarObj)
#调用循环方法,去解析子层级区域
tar_obj_set_result = cycleSpider(province_code,1,grade_2_url,error_data_set)
# 合并两个集合结果集【取并集】
tar_obj_set = tar_obj_set | tar_obj_set_result
print('-'*12 +province_name+'---爬取结束'+'-'*12)
time.sleep(10)
#本省数据入库存储
try:
nbsDataToSaveBatch(tar_obj_set)
except Exception as e:
print('-'*12 +province_name+'---数据入库存储异常')
print(e)
#全国数据初次处理完毕,开始处理整体过程中失败的数据,重试
print('------开始处理初次全国爬取失败的数据,共------'+str(len(error_data_set))+'条')
while(len(error_data_set) > 0):
error_data_set_second = set()
for item in error_data_set:
tar_save_set = cycleSpider(item.parent_code, item.parent_level, item.to_parse_url,error_data_set_second)
#存储入库
try:
nbsDataToSaveBatch(tar_save_set)
except Exception as e:
print('---全国爬取过程的错误数据重试爬取后入库存储异常,---')
print(e)
for item in tar_save_set:
print(item.nbs_code + '-'*6 + item.nbs_parent_code + '-'*6 + str(item.nbs_level) + '-'*6 + item.nbs_name + '-'*6 + item.nbs_town_country_code)
#更新error_data_set
print('------再次失败的数据,共------' + str(len(error_data_set_second)) + '条')
error_data_set = error_data_set_second
time.sleep(10)NbsCycleSpider:
'''
多层级循环递归调用解析区域,然后返回数据集合
'''
import socket
import time
from urllib.error import HTTPError
from urllib.request import urlopen
from bs4 import BeautifulSoup
from NbsRegionSpider.Bean.NbsRegionDTO import NbsRegionDTO
from NbsRegionSpider.Bean.ParseErrorClass import ParseErrorClass
from NbsRegionSpider.Util.UrlGetUtil import UrlGetUtil
def cycleSpider(parent_code,parent_level,to_parse_url,error_data_set):
# 本次爬取行政区划数据结果集
tar_obj_set = set()
#按层级使用不同的解析标签关键字
tr_flag = ''
current_level = parent_level + 1#级别级别
if current_level == 2:
tr_flag = 'citytr'
elif current_level == 3:
tr_flag = 'countytr'
elif current_level == 4:
tr_flag = 'towntr'
elif current_level == 5:
tr_flag = 'villagetr'
else:
pass
#解析
try:
urlGetUtilObj = UrlGetUtil()
# urlopern方式
html = urlGetUtilObj.getByUrlOpen(to_parse_url,'gbk')
# request.get 方式
# html = urlGetUtilObj.getByRequestGet(to_parse_url,'gbk')
except socket.timeout:
print('parent_code = '+parent_code+'---待解析URL:' + to_parse_url + '请求超时')
# 暂时跳过,将出现异常的待解析数据暂存起来
error_data_set.add(ParseErrorClass(parent_code, parent_level, to_parse_url))
return tar_obj_set
except HTTPError as e:
print('parent_code = '+parent_code+'---待解析URL:' + to_parse_url + '出现http错误:')
print(e)
# 暂时跳过,将出现异常的待解析数据暂存起来
error_data_set.add(ParseErrorClass(parent_code, parent_level, to_parse_url))
return tar_obj_set
except Exception as e:
print('parent_code = '+parent_code+'---待解析URL:'+to_parse_url+'请求出现异常')
print(e)
#暂时跳过,将出现异常的待解析数据暂存起来
error_data_set.add(ParseErrorClass(parent_code,parent_level,to_parse_url))
return tar_obj_set
else:
pass
bs = BeautifulSoup(html, 'html.parser')
#获取本页所有数据节点
trs = bs.findAll('tr', {'class': tr_flag})
for tr in trs:
#注意,5极页面有三个td,和别的等级页面中的相同td位置,存放数据不是一样的类型,所以进行判断
td_1 = tr.find('td')#第一个td节点
current_code = td_1.get_text()
current_url = ''
current_name = ''
current_town_country_code = ''
td_2 = td_1.next_sibling#第二个td节点
if(current_level == 5):
current_town_country_code = td_2.get_text()
current_name = td_2.next_sibling.get_text()
else:
td_1_a = td_1.a
if td_1_a is not None: #比如青海省西宁市市辖区 ,才到三级,就咩有下级了,所以a标签为None对象
current_url = td_1_a['href']
current_name = td_2.get_text()
#打印开始日志
if (current_level == 2):
print('-'*8 + current_name)
elif(current_level == 3):
print('-' * 4 + current_name)
#封装数据
tarObj = NbsRegionDTO(current_code, parent_code, current_level, current_name, current_town_country_code)
tar_obj_set.add(tarObj)
# 递归调用,获取下级数据
tar_obj_set_result = set()
if (current_level != 5 and current_url != ''): # 五级一定没有下级
# 当前解析页面截取最后一个'/'之前的url ,再拼接当前页面的href 就是下一级别的解析url
pos = to_parse_url.rfind("/")
next_url_data = to_parse_url[:pos] + '/' + current_url
tar_obj_set_result = cycleSpider(current_code,current_level,next_url_data,error_data_set)
# 合并两个集合结果集【取并集】 并返回
tar_obj_set = tar_obj_set | tar_obj_set_result
if(current_level == 2 or current_level == 3):
time.sleep(10)
return tar_obj_set
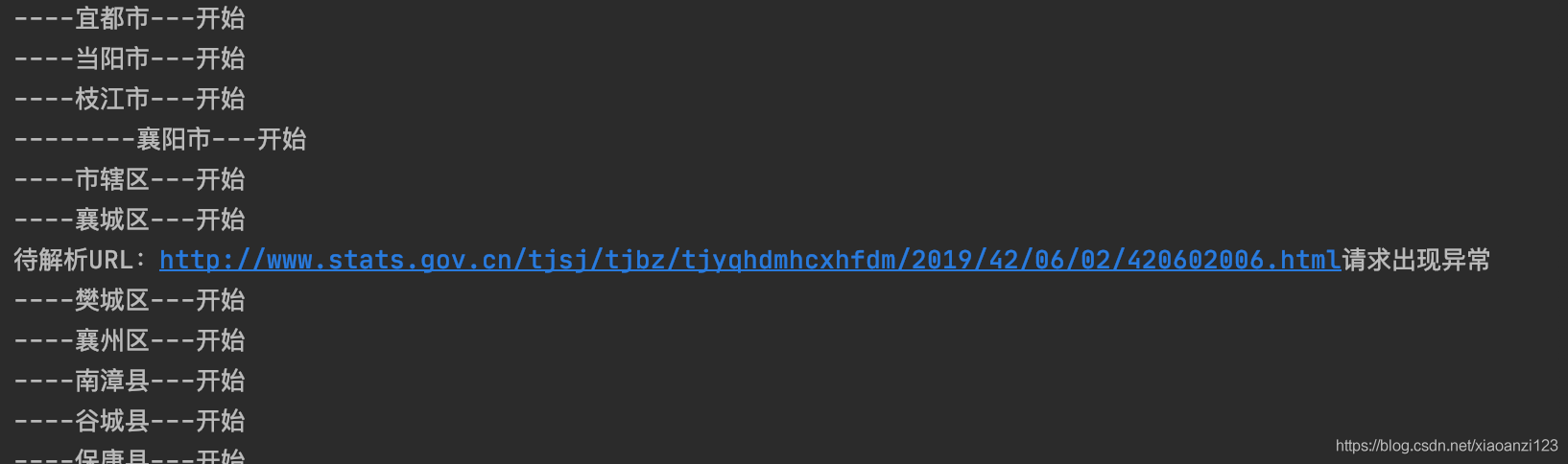
部分运行日志:
代码中已经写了详细的步骤注释,理解起来应该没有什么问题。不过还有很大的改进空间,比如改当前的深度爬取为广度爬取,可以有效降低服务器负载等,后续不断积累经验,越来越好吧。欢迎批评指正交流。
-----------------------------------20200911补充:
实际运行发行最后一直有三个url链接无法成功,一直在循环重试、失败着打印日志。别的数据都正常。这三个url为:
待解析URL:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/02/420602006.html
待解析URL:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/84/420684103.html
待解析URL:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/51/06/81/510681114.html
异常如下:'gbk' codec can't decode byte 0xfe in position 3068: illegal multibyte sequence
是编码问题,然而别的数据都是用的gbk都没问题,这个已经也在网页源代码中确认,说明这三个url有问题。
参考文章:https://blog.csdn.net/zangbianer/article/details/84526011 ,使用gb18030 问题解决。
为了针对这三个数据处理,我对原有代码做了一点重构:
新建新的类M,代码如下,专门用于处理一直失败的数据,同时为了复用代码,把原来NbsMain中的对错误数据处理的代码抽取出来,放到下面的handle_error_retry()中。然后把爬取链接参数处的gbk改为gb18030,运行下面的M代码,即可。
'''
对于一直处理报错的url,最终手动处理
'''
import time
from NbsRegionSpider.Bean.ParseErrorClass import ParseErrorClass
from NbsRegionSpider.NbsCycleSpider import cycleSpider
from NbsRegionSpider.SaveData import nbsDataToSaveBatch
'''
出现错误的数据重试方法
'''
def handle_error_retry(error_data_set):
while (len(error_data_set) > 0):
error_data_set_second = set()
for item in error_data_set:
tar_save_set = cycleSpider(item.parent_code, item.parent_level, item.to_parse_url, error_data_set_second)
# 存储入库
try:
nbsDataToSaveBatch(tar_save_set)
except Exception as e:
print('---全国爬取过程的错误数据重试爬取后入库存储异常,---')
print(e)
for item in tar_save_set:
print(item.nbs_code + '-' * 6 + item.nbs_parent_code + '-' * 6 + str(
item.nbs_level) + '-' * 6 + item.nbs_name + '-' * 6 + item.nbs_town_country_code)
# 更新error_data_set
print('------再次失败的数据,共------' + str(len(error_data_set_second)) + '条')
error_data_set = error_data_set_second
time.sleep(10)
data_set = set()
'''
所有的数据中就只有这三个一直失败,别的都成功,异常如下:
'gbk' codec can't decode byte 0xfe in position 3068: illegal multibyte sequence
网页编码的确时gbk没错的,参考文章:https://blog.csdn.net/zangbianer/article/details/84526011
改为 gb18030成功解决。
又看了下这三个url网页,发现每一页中都有一条数据的地名中,包含特殊字符,网页上显示的是一个小方格。罪魁祸首就是他了。
一共这三个名字包含未知字符的地点的code是:510681114209 420684103005 420602006207
'''
data_set.add(ParseErrorClass('420602006000', 4,'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/02/420602006.html'))
data_set.add(ParseErrorClass('420684103000', 4,'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/84/420684103.html'))
data_set.add(ParseErrorClass('510681114000', 4,'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/51/06/81/510681114.html'))
handle_error_retry(data_set)
这三个url中的元凶被我给揪了出来;