目录
音频简介
经常见到这样的描述: 44100HZ 16bit stereo 或者 22050HZ 8bit mono 等等.
44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2字节)记录, 双声道(立体声);
22050HZ 8bit mono: 每秒钟有 22050 次采样, 采样数据用 8 位(1字节)记录, 单声道;
当然也可以有 16bit 的单声道或 8bit 的立体声, 等等。
采样率
采样率 是指:声音信号在“模→数”转换过程中单位时间内采样的次数。采样值是指每一次采样周期内声音模拟信号的积分值。
对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH);
而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位(左声道)和低八位(右声道)分别代表两个声道。
人对频率的识别范围是 20HZ - 20000HZ, 如果每秒钟能对声音做 20000 个采样, 回放时就足可以满足人耳的需求. 所以 22050 的采样频率是常用的, 44100 已是CD音质, 超过48000的采样对人耳已经没有意义。这和电影的每秒 24 帧图片的道理差不多。
储存空间
每个采样数据记录的是振幅, 采样精度取决于储存空间的大小:
1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
如果是双声道(stereo), 采样就是双份的, 文件也差不多要大一倍.
这样我们就可以根据一个 wav 文件的大小、采样频率和采样大小估算出一个 wav 文件的播放长度。
譬如 “Windows XP 启动.wav” 的文件长度是 424,644 字节, 它是 “22050HZ / 16bit / 立体声” 格式(这可以从其 “属性->摘要” 里看到),
那么它的每秒的传输速率(位速, 也叫比特率、取样率)是 22050162 = 705600(bit/s), 换算成字节单位就是 705600/8 = 88200(字节/秒),
播放时间:424644(总字节数) / 88200(每秒字节数) ≈ 4.8145578(秒)。
但是这还不够精确, 包装标准的 PCM 格式的 WAVE 文件(*.wav)中至少带有 42 个字节的头信息, 在计算播放时间时应该将其去掉:
所以就有:(424644-42) / (22050162/8) ≈ 4.8140816(秒). 这样就比较精确了.
关于声音文件还有一个概念: “位速”, 也有叫做比特率、取样率, 譬如上面文件的位速是 705.6kbps 或 705600bps, 其中的 b 是 bit, ps 是每秒的意思;
压缩的音频文件常常用位速来表示, 譬如达到 CD 音质的 MP3 是: 128kbps / 44100HZ.
wave文件格式
概述
WAVE文件是计算机领域最常用的数字化声音文件格式之一,它是微软专门为Windows系统定义的波形文件格式(Waveform Audio),由于其扩展名为"*.wav"。
WAVE是录音时用的标准的WINDOWS文件格式,文件的扩展名为“WAV”,数据本身的格式为PCM或压缩型。
WAV文件格式是一种由微软和IBM联合开发的用于音频数字存储的标准,它采用RIFF文件格式结构,非常接近于AIFF和IFF格式。符合 PIFF Resource Interchange File Format规范。所有的WAV都有一个文件头,这个文件头音频流的编码参数。
WAV对音频流的编码没有硬性规定,除了PCM之外,还有几乎所有支持ACM规范的编码都可以为WAV的音频流进行编码。
多媒体应用中使用了多种数据,包括位图、音频数据、视频数据以及外围设备控制信息等。RIFF为存储这些类型的数据提供了一种方法,RIFF文件所包含的数据类型由该文件的扩展名来标识,能以RIFF文件存储的数据包括:
音频视频交错格式数据(.AVI) 、波形格式数据(.WAV) 、位图格式数据(.RDI) 、MIDI格式数据(.RMI) 、调色板格式(.PAL) 、多媒体电影(.RMN) 、动画光标(.ANI) 、其它RIFF文件(.BND)。
wave文件有很多不同的压缩格式,所以,正确而详细地了解各种WAVE文件的内部结构是成功完成压缩和解压缩的基础,也是生成特有音频压缩格式文件的前提。
最基本的WAVE文件是PCM(脉冲编码调制)格式的,这种文件直接存储采样的声音数据没有经过任何的压缩,是声卡直接支持的数据格式,要让声卡正确播放其它被压缩的声音数据,就应该先把压缩的数据解压缩成PCM格式,然后再让声卡来播放。
Wave文件的内部结构
注:由于WAV格式源自Windows/Intel环境,因而采用Little-Endian字节顺序进行存储。
WAVE文件是以RIFF(Resource Interchange File Format, “资源交互文件格式”)格式来组织内部结构的。
RIFF文件结构可以看作是树状结构,其基本构成是称为"块"(Chunk)的单元,最顶端是一个“RIFF”块,下面的每个块有“类型块标识(可选)”、“标志符”、“数据大小”及“数据”等项所组成。块的结构如表1所示:
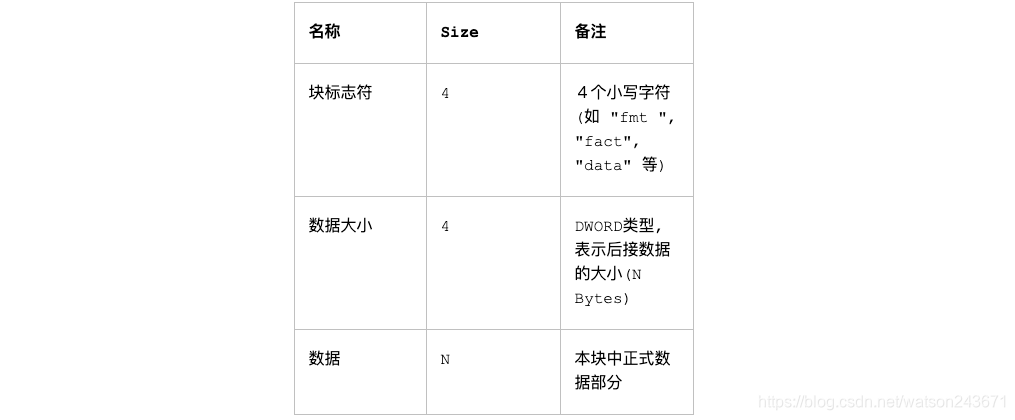
上面说到的“类型块标识”只在部分chunk中用到,如 “WAVE” chunk中,这时表示下面嵌套有别的chunk。
当使用了 “类型块标识” 时,该chunk就没有别的项(如块标志符,数据大小等),它只作为文件读取时的一个标识。先找到这个“类型块标识”,再以它为起点读取它下面嵌套的其它chunk。
每个文件最前端写入的是RIFF块,每个文件只有一个RIFF块。从 Wave文件格式详细说明 中可以看到这一点。
非PCM格式的文件会至少多加入一个 “fact” 块,它用来记录数据(注意是数据而不是文件)解压缩后的大小。这个 “fact” 块一般加在 “data” 块的前面。
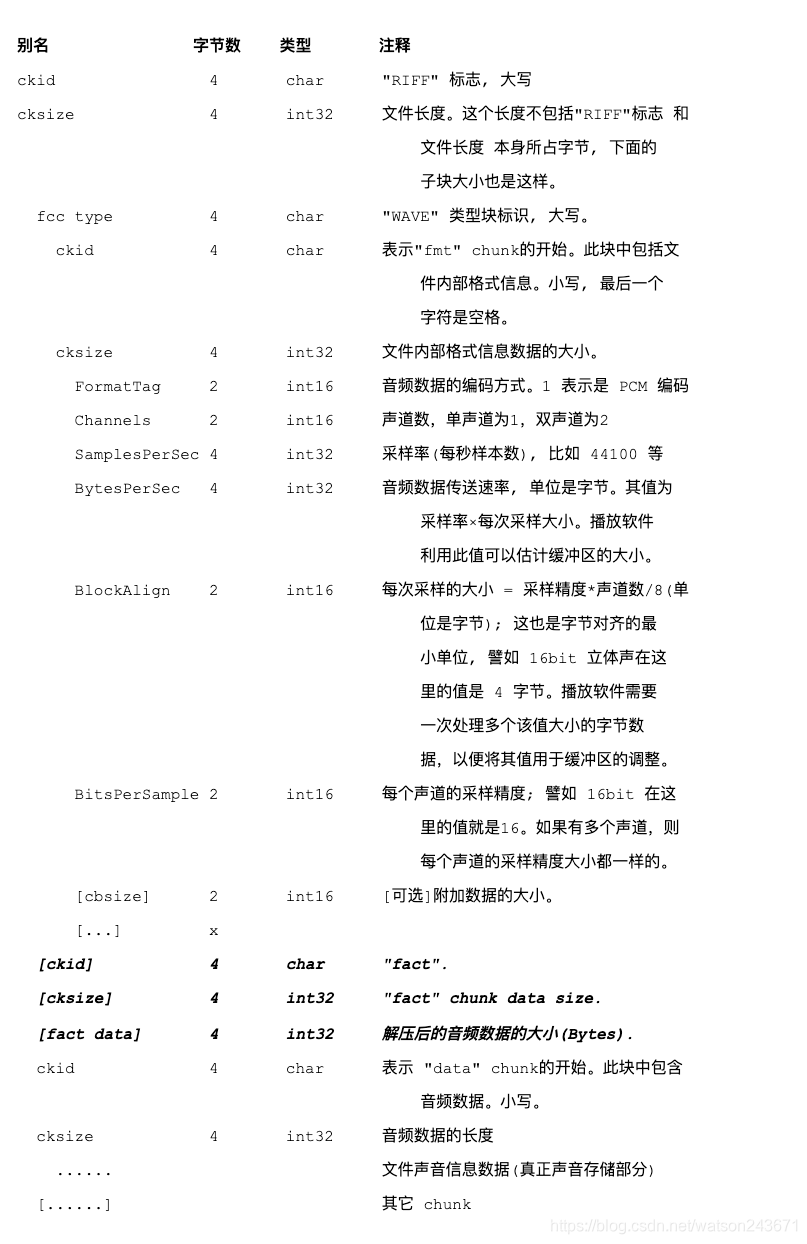
WAVE文件是由若干个Chunk组成的。按照在文件中的出现位置包括:RIFF WAVE Chunk, Format Chunk, Fact Chunk(可选), Data Chunk。
具体见下图:
-------------------------------------------
| RIFF WAVE Chunk |
| ID = "RIFF" |
| RiffType = "WAVE" |
-------------------------------------------
| Format Chunk |
| ID = "fmt " |
-------------------------------------------
| Fact Chunk(optional) |
| ID = "fact" |
-------------------------------------------
| Data Chunk |
| ID = "data" |
-------------------------------------------
图 Wav格式包含Chunk示例
Fact Chunk
=======================================
| |所占字节数| 具体内容 |
=======================================
| ID | 4Bytes | "fact" |
---------------------------------------
| Size | 4Bytes | 4 |
---------------------------------------
| data | 4Bytes |解压后的音频数据的大小(B)|
---------------------------------------
图 Fact Chunk
Wave文件格式详细说明
Windows平台上WAVEFORMAT结构的认识
PCM和非PCM的主要区别是声音数据的组织不同,这些区别可以通过两者的WAVEFORMAT结构来区分。
下面以PCM和IMA-ADPCM来进行对比。
WAVE的基本结构 WAVEFORMATEX 结构定义如下:
1 typedef struct
2 {
3 WORD wFormatag; //编码格式,包括WAVE_FORMAT_PCM,WAVEFORMAT_ADPCM等
4 WORD nChannls; //声道数,单声道为1,双声道为2;
5
6 DWORD nSamplesPerSec; //采样频率;
7
8 DWORD nAvgBytesperSec; //每秒的数据量;
9
10 WORD nBlockAlign; //块对齐;
11
12 WORD wBitsPerSample; //WAVE文件的采样大小;
13
14 WORD cbSize; // The count in bytes of the size of extra
15 // information(after cbSize). PCM中忽略此值
16 } WAVEFORMATEX;
IMAADPCMWAVEFORMAT结构定义如下:
1 Typedef struct
2 {
3 WAVEFORMATEX wfmt;
4
5 WORD nSamplesPerBlock;
6
7 } IMAADPCMWAVEFORMAT;
IMA-ADPCM中的的wfmt->cbsize不能忽略,一般取值为2,表示此类型的WAVEFORMAT比一般的WAVEFORMAT多出2个字节。这两个字符也就是nSamplesPerBlock。
“fact” chunk的内部组织
在非PCM格式的文件中,一般会在WAVEFORMAT结构后面加入一个 “fact” chunk, 结构如下:
datafactsize是这个chunk中最重要的数据,如果这是某种压缩格式的声音文件,那么从这里就可以知道他解压缩后的大小。对于解压时的计算会有很大的好处!
“data” chunk的内部组织
typedef struct{
char[4]; //“fact”字符串
DWORD chunksize;
DWORD datafactsize; // 音频数据转换为PCM格式后的大小。
} factchunk;
从 “data” chunk的第9个字节开始,存储的就是声音信息的数据了,(前八个字节存储的是标志符 “data” 和后接数据大小size(DWORD)。这些数据可以是压缩的,也可以是没有压缩的。
PCM数据格式
PCM(Pulse Code Modulation)也被称为 脉码编码调制。PCM中的声音数据没有被压缩,如果是单声道的文件,采样数据按时间的先后顺序依次存入。(它的基本组织单位是BYTE(8bit)或WORD(16bit))
一般情况下,一帧PCM是由2048次采样组成的,参考 。
如果是双声道的文件,采样数据按时间先后顺序交叉地存入。如图所示:
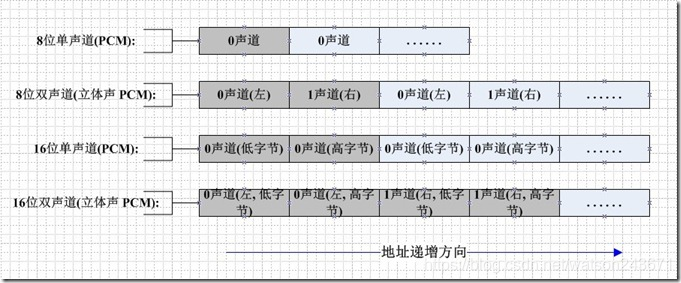
PCM的每个样本值包含在一个整数i中,i的长度为容纳指定样本长度所需的最小字节数。
首先存储低有效字节,表示样本幅度的位放在i的高有效位上,剩下的位置为0,这样8位和16位的PCM波形样本的数据格式如下所示。
样本大小 数据格式 最小值 最大值
8位PCM unsigned int 0 225
16位PCM int -32767 32767
参考资料
[1]http://redsoft.ycool.com/post.2232742.html
[2]http://dev.firnow.com/course/3_program/hb/hbxl/20100803/518348.html
[3]http://hi.baidu.com/kindyb/blog/item/0a314f8859489c93a4c27297.html
[4]http://hi.baidu.com/kindyb/blog/item/353f4813df8799055aaf5397.html
[5]http://hi.baidu.com/kindyb/blog/item/2f31daa93f5ed4fb1e17a291.html
[6]http://hi.baidu.com/bigbigant/blog/item/7b91aa01e46dd4021d958317.html