注意:点击图片可以放大查看
程序执行过程:
因为软件和硬件之间隔着一个操作系统,我们将我们写好的源代码编译生成了汇编代码,但是不可执行,因为不同的操作系统操作要求不同,这时我们就需要通过链接生成可执行文件来实现不同操作系统需要的要求。
可以将源代码理解为是生猪,编译的过程就相当宰杀,汇编代码就相当于宰杀完成的猪肉,链接就相当于将猪肉做饭的过程,可执行文件相当于做好的饭菜,这样就可以供我们食用了,如下图所示。

编译器的作用:将复杂的逻辑分解成简单的逻辑,即将C/C++代码编译生成与之一一对应的汇编代码
汇编代码包括三部分:赋值语句、跳转语句、计算语句
程序在编译的时候会将内存分为下图所示的几个区域来存储不同的代码,目的是为了保证安全,因为C/C++语言是可以操作内存的语言,万一不小心将指针指向了代码区域并且修改了,这样程序就挂掉了。

代码区和常量区是只读不写的,栈区和堆区是又可读又可写
栈区:一开始就会给分配1024KB大小的空间,用于存储临时变量。
为什么要用栈来存储临时变量呢? 因为临时变量是需要占用内存的,占用完成的内存我们都需要将其释放掉,如果我们采用分配内存的方式来找到空间再释放的方式会消耗大量的性能。
采用栈为什么就不会消耗大量的性能呢? 因为栈中有ebp时针(游标1)用来存储初始使用变量的位置,每使用一个临时变量就会占用栈的一部分空间,再拿esp寄存器(游标2)存储最高点使用变量的位置,使用完成这些变量之后我们释放掉时,根部不要采用清空栈的方式,只需要将esp指针和ebp指针重合即可清空,如下图结构示意图所示。
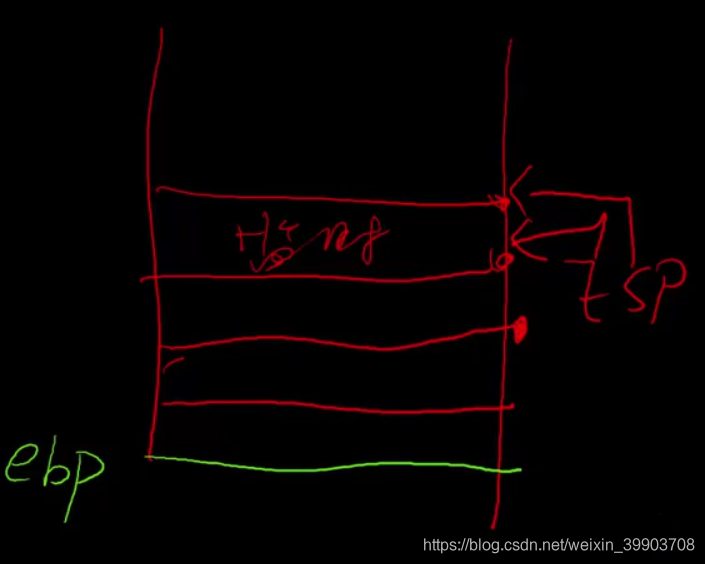
栈不仅存储临时变量,还会存储函数跳转后返回的地址。
程序调用函数时就会执行别的函数体里面的东西,下图分析一下程序调用函数的执行过程:有专门的代码空间存储一个个的小的片段(函数),程序执行的时候是根据程序计数器来执行,我们执行到 call print,这是就会跳转到print函数,执行完print函数之后我们还需要回到原来执行的位置。
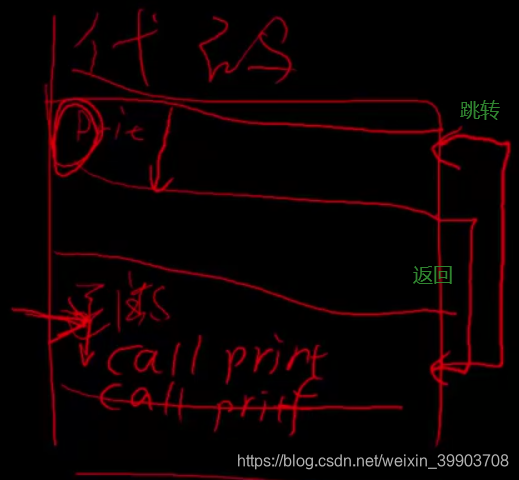
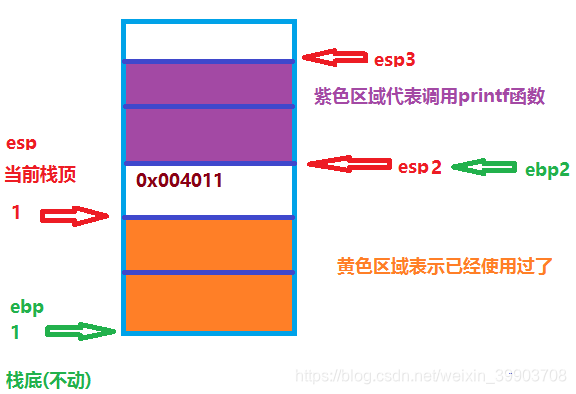
怎么回到原来执行的位置呢?这时我们就可以使用栈:当我们程序执行到esp的1位置时,遇到call时我们会将当前函数的地址0x004011存储到栈中(此时esp上移到2位置)与此同时我们将ebp的1位置移动到ebp的2位置此时我们还需要将ebp的1位置记录一下。开始执行print函数(紫色区域),此时esp上移到3的位置,printf函数执行完成之后我们将esp的3位置移动到esp的2位置这样就实现了将函数的释放,return回到了调用printf函数的位置ebp2,然后继续执行下面的其它函数。
堆区:分配出来一段空间,程序员需要使用时使用。堆与栈的区别是:堆不像栈一样排列着,它是什么时候想用就可以拿来使用,但是使用完之后必须自己来释放,如果自己不释放的话就会出现内存泄露的问题。