要解决一个机器学习问题,我们不能仅仅通过将算法应用到提供的数据上。比如.fit() 。我们首先需要构建一个数据集。
将原始数据转换为数据集的任务称为特征工程。
例如,预测客户是否坚持订阅特定产品。这将有助于进一步提高产品或用户体验,还有助于业务增长。
原始数据将包含每个客户的详细信息,如位置、年龄、兴趣、在产品上花费的平均时间、客户续订订阅的次数。这些细节是数据集的特性。创建数据集的任务是从原始数据中了解有用的特性,并从对结果有影响的现有特性中创建新特性,或者操作这些特性,使它们可以用于建模或增强结果。整个过程被简称为特性工程。
有多种方法可以实现特征工程。根据数据和应用程序不同来分类。
在本文中,我们将了解为什么使用特征工程和特征工程的各种方法。
为什么使用特征工程?
特征工程出现在机器学习工作流程的最初阶段。特性工程是决定结果成败的最关键和决定性的因素。

许多Kaggle比赛都是通过基于问题创建适当的功能而获胜的。例如,在一场汽车转售比赛中,获胜者的解决方案包含一个分类特征——普通汽车的颜色,稀有汽车的颜色。这一特性增加了汽车转售的预测效果。既然我们已经理解了特性工程的重要性,现在让我们深入研究用于实现的各种标准方法。
现在让我们了解如何实现特性工程。以下是广泛使用的基本特征工程技术,
-
编码
-
分箱
-
归一化
-
标准化
-
处理缺失值
-
数据归责技术
编码
有些算法只处理数值特征。但是,我们可能有其他数据,比如在我们的例子中“用户观看的内容类型”。为了转换这种数据,我们使用编码。
One-Hot编码
将分类数据转换为列,并将每个惟一的类别作为列值,这是一种One-Hot编码。
下面是实现One-Hot编码的代码片段,
encoded_columns = pd.get_dummies(data['column'])
data = data.join(encoded_columns).drop('column', axis=1)
当分类特征具有不那么独特的类别时,这种方法被广泛使用。我们需要记住,当分类特征的独特类别增加时,维度也会增加。
标签编码
通过为每个类别分配一个唯一的整数值,将分类数据转换为数字,称为标签编码。
比如“喜剧”为0,“恐怖”为1,“浪漫”为2。但是,这样划分可能会使分类具有不必要的一般性。
当类别是有序的(特定的顺序)时,可以使用这种技术,比如3代表“优秀”,2代表“好”,1代表“坏”。在这种情况下,对类别进行排序是有用的。
下面是要实现标签编码器的代码片段。
from sklearn.preprocessing import ColumnTransformer
labelencoder = ColumnTransformer()
x[:, 0] = labelencoder.fit_transform(x[:, 0])
分箱
另一种相反的情况,在实践中很少出现,当我们有一个数字特征,但我们需要把它转换成分类特征。分箱(也称为bucketing)是将一个连续的特性转换成多个二进制特性的过程,通常基于数值。
#Numerical Binning Example
Value Bin
0-30 -> Low
31-70 -> Mid
71-100 -> High#Categorical Binning Example
Value Bin
Germany-> Europe
Italy -> Europe
India -> Asia
Japan -> Asia
分箱的主要目的是为了使模型更健壮,防止过拟合,但这对性能有一定的影响。每次我们丢弃信息,我们就会牺牲一些信息。
正则化
归一化(也称为最小最大归一化)是一种缩放技术,当应用它时,特征将被重新标定,使数据落在[0,1]的范围内。
特征的归一化形式可通过如下方法计算:
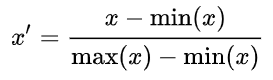
归一化的数学公式。
这里’ x ‘是原始值而’ x '是归一化值。
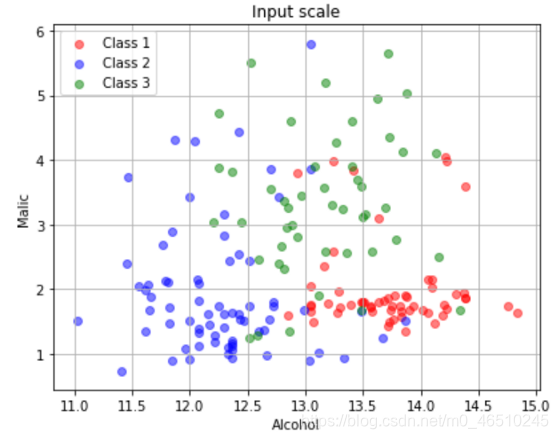
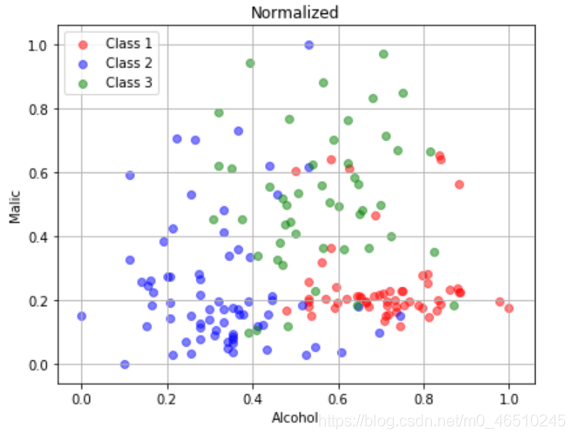
在原始数据中,alcohol在[11,15],malic在[0,6]。归一化数据中,alcohol在[0,1]之间,malic在[0,1]之间。
标准化
标准化(也叫Z-score归一化)是一种缩放技术,当它被应用时,特征会被重新调整,使它们具有标准正态分布的特性,即均值为0,标准差为=1;其中,μ 为平均值(average),σ为与平均值的标准差。
计算样本的标准分数(也称z分数)如下:
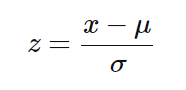
标准化的数学公式
这将特征在[-1,1]之间进行缩放
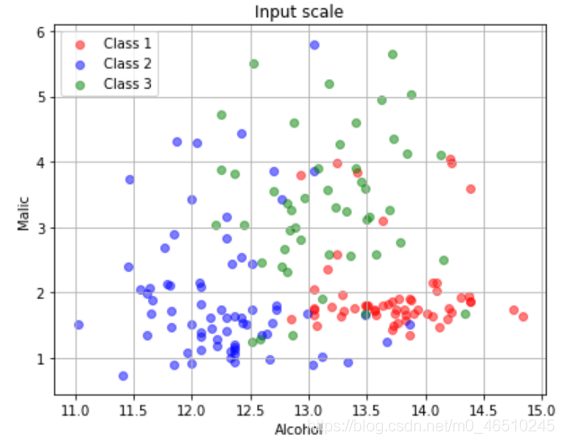

在原始数据中,alcohol在[11,15],malic在[0,6]。在标准化数据中,二者居中于0。
处理缺失值
数据集可能包含一些缺失的值。这可能是在输入数据的失误或出于保密方面的考虑。无论原因是什么,减少它对结果的影响是至关重要的。下面是处理缺失值的方法,
-
简单地删除那些缺少值的数据点(当数据很大而缺少值的数据点较少时,这样做更可取)
-
使用处理缺失值的算法(取决于实现该算法的库)
-
使用数据注入技术(取决于应用程序和数据)
数据归责技术
数据填充就是简单地用一个不会影响结果的值替换缺失的值。
对于数值特征,缺失的值可以替换为:
- 0或默认值
#Filling all missing values with 0
data = data.fillna(0)
- 重复率最高的值
#Filling missing values with mode of the columns
data = data.fillna(data.mode())
- 该特征的均值(受离群值影响,可以用特征的中值替换)
#Filling missing values with medians of the columns
data = data.fillna(data.median())
对于分类特征,缺失的值可以替换为:
- 重复率最高的值
#Most repeated value function for categorical columns
data['column_name'].fillna(data['column_name'].value_counts()
.idxmax(), inplace=True)
- “其他”或任何新命名的类别,这意味着对数据点的估算
在本文中,我们了解了广泛使用的基本特性工程技术。我们可以根据数据和应用程序创建新特性。但是,如果数据很小而且质量不好,这些方法可能就没有用了。
作者:Ramya Vidiyala
deephub翻译组:孟翔杰