又到一年的年末了,各个“心怀鬼胎”的程序猿们要开始进行准备下,迎接来年跳槽大会了。而面试呢,都躲不掉问下网络编程的一些知识,在此,收集了较全的基础知识点,希望能帮助到大家。
文章目录
1.基础知识
1.1.OSI七层模型
OSI七层模型是以下七层:
- 7应用层(application) : 提供用户服务,具体功能有程序体现 http (用于超文本传输),ftp(文件传输协议)NFS,WAIS pop3(邮件接收) smtp(邮件发送)
6表示层(Presentation) : 数据的压缩优化和加密
5会话层 (session): 建立应用连接,选择合适的传输服务
4传输层 (Transportation): 提供传输服务,进行流量控制
3网络层 (Network): 路由选择(寻址),网络互连
2链路层 (Data Link): 进行数据交换,控制具体消息收发,链路连接
1物理层 (Physical): 提供物理硬件传输,网卡,接口设置,传输介质
七层是国际标准,常用呢把上三层合并成一个为一层,叫应用层;把物理层和链路层合并为链路层。
1.2.TCP协议
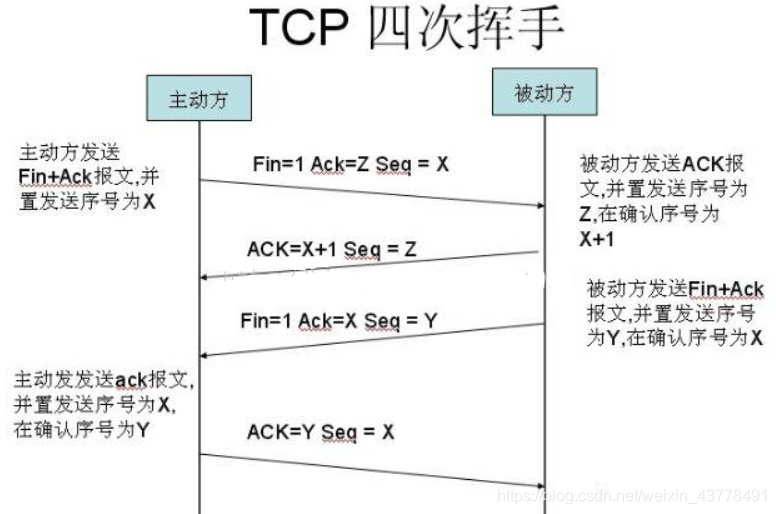
TCP是提供可靠传输的一种协议,可靠两字就来自要连接通信时需要经过三次握手,断开时需要经常四次挥手。具体如图:
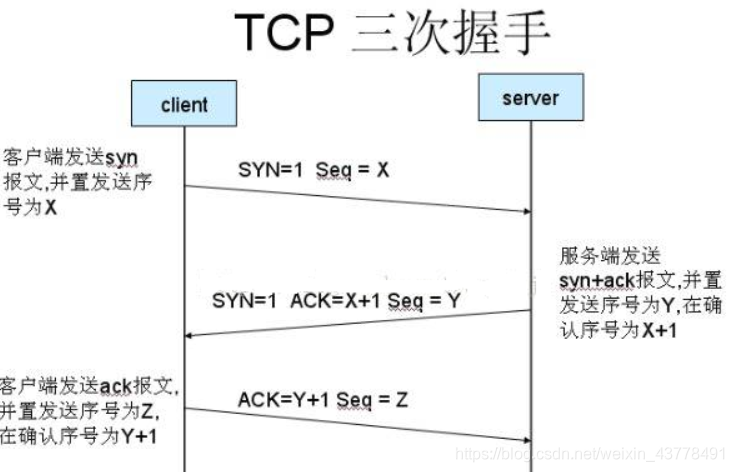
基于这个模型应用而生的数据传输工具就叫流事套接字(SOCK_STREAM),一种 套接字类型。tcp套接字以字节流的方式传输消息,没有消息边界,自然会产生粘包问题,需要人工处理下。
处理粘包:
1. 人为添加消息边界
2. 将消息结构化
3. 控制消息发送速度
举例:在c/s模型简单应用如下:
server端:
#创建套接字对象
server= socket(socket_family=AF_INET,socket_type=SOCK_STREAM,proto=0)
server.bind((address,port)) #绑定地址
server.listen(backlog)#监听
client,addr=s.accept() #阻塞,等待接收连接请求
client.recv(buffersize) #接收客户端发来的消息
client.send(message) #向客户端发送消息
client.close()
server.close() #关闭连接
client端
#创建套接字对象
client= socket(socket_family=AF_INET,socket_type=SOCK_STREAM,proto=0)
client.connect(address) #客户端连接服务器
client.send(message) #向服务端发送消息
client.recv(buffersize) #接收服务端发来的消息
client.close() #关闭连接
1.3.UPD协议
UDP则提供的是非面向连接的、不可靠的数据传输。以数据报的方式传输。适用于一次只传送少量数据、对可靠性要求不高的应用。
UDP的c/s模型:
server端
#创建套接字对象
server= socket(socket_family=AF_INET,socket_type=SOCK_DGRAM,proto=0)
server.bind((address,port)) #绑定地址
data,addr = server.recvfrom(buffersize) #接收客户端发来的消息
server.sendto(message,addr) #向客户端发送消息
server.close() #关闭连接
client端
#创建套接字对象
client= socket(socket_family=AF_INET,socket_type=SOCK_DGRAM,proto=0)
client.sendto(message,addr) #向服务端发送消息
data,addr = client.recvfrom(buffersize) #接收服务端发来的消息
client.close() #关闭连接
1.3.TCP和UPD对比总结
对比下其实tcp和udp的模型很相似。他们间的区别就以下几点:
- tcp套接字以字节流方式传输,数据报套接字以数据报形 式传输
- tcp传输会有粘包,udp不会(有消息边界)
- tcp传输保证传输可靠性,udp则会有部分消息丢失的可能
- tcp需要listen accept 保证连接,udp不需要
- tcp使用send,recv收发消息,udp使用sendto recvfrom
- ※这里也顺带补充下套接字的一些属性。
#创建套接字
sockfd= socket(socket_family,socket_type,proto=0)
server.bind((address,port)) #绑定地址
sockfd.family 获取套接字地址族类型
sockfd.type 获取套接字类型(SOCK_STREAM 流式,SOCK_DGRAM 数据报)
sockfd.getsockname() 获取套接字绑定地址
sockfd.getpeername() 获取连接端的地址信息
sockfd.fileno() 获取套接字的文件描述符
sockfd.setsockopt(level,option,value)
功能 : 设置套接字选项,丰富或者修改套接字属性功能( level 要设置的套接字选项类别 ,option 选择每个类别中具体的选项,value 要设置的值)
1.4.HTTP协议
http协议用途 : 网页的获取,数据的传输
特点 :
1. 应用层协议,传输层采用tcp方式收发消息
2. 简单,灵活,很多语言都有http协议接口
3. 无状态的协议,协议本身不要求记录传输数据
4. http1.1 支持持久连接
网页请求过程:
- 客户端(浏览器)通过tcp传输,发送http请求给服务器
- 服务器收到http请求后进行解析
- 服务端处理具体请求内容,整理需要的数据
- 将数据以http响应的格式回发给客户端(浏览器)
- 浏览器接收响应,显示内容
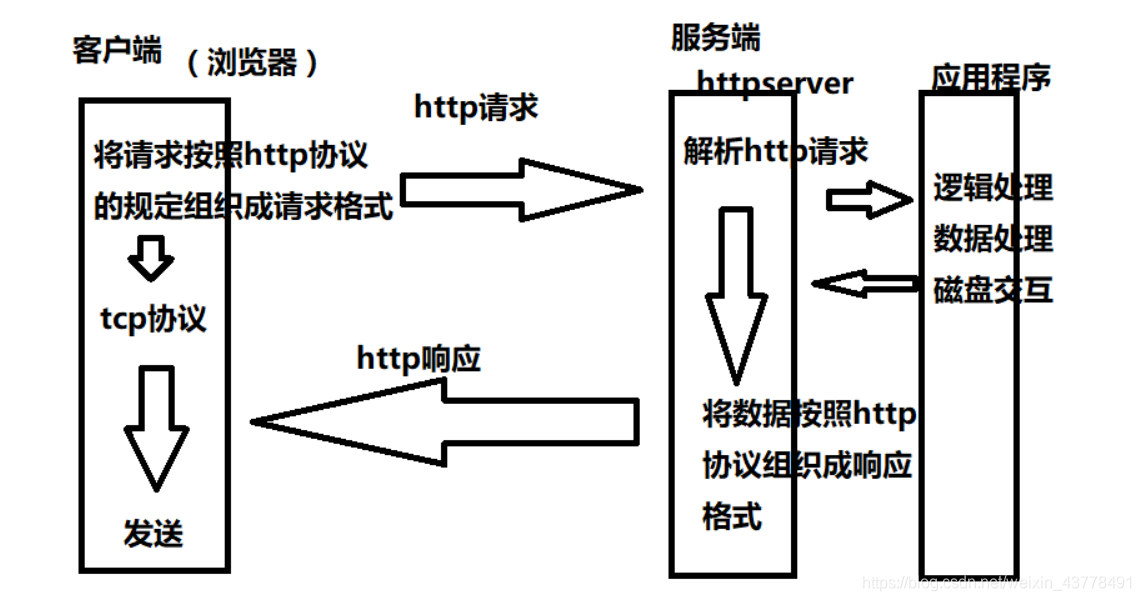
其中有两个重点,一个是http请求格式和http相应格式(当然还有json和cookie,做爬虫的老铁们肯定不陌生)
http请求格式:
请求行(请求类别 请求内容 协议版本)
请求头(对请求内容的基本描述)
空行 !!!很关键
请求体(请求参数和提交内容)
http相应格式:
响应行(协议版本 响应码 附加信息)
响应头(对响应内容的描述信息)
空行
相应体 (回复给客户端的具体内容)
2.IO模型
IO ,什么是IO操作:
和终端交互 : input print
和磁盘交互 : read write
和网络交互 : recv send
2.1.阻塞IO
因为某种条件没有达成造成的函数阻塞的IO操作则是阻塞IO,
2.2.非阻塞IO
当然将原本阻塞的函数通过属性的设置改变阻塞行为,变为非阻塞IO。
常见有两种。
sockfd.setblocking(bool) #设置套接字为非阻塞IO
sockfd.settimeout(sec) #设置套接字超时时间
2.3.IO多路复用
同时监控多个IO事件,选择其中能够执行的IO进行IO 事件处理. 以此形成可以同时操作多个IO的行为模型则是IO多路复用。方法有以下三种
2.3.1.select 方法
rs,ws,xs=select(rlist, wlist, xlist[, timeout]) #创建方法,用于监控IO事件,阻塞等待IO事件发生。
例子有点长,我单独写在一篇里,连接为:https://blog.csdn.net/weixin_43778491/article/details/86557115
这里有几个注意事项。注意 : 1. IO多路复用占用计算机资源较少,效率较高
2. wlist 中如果有IO则select立即返回处理
3. 在IO处理过程中不要出现死循环,影响IO 监控
2.3.2.poll方法
使用方法
-
创建套接字 ,poll对象,建立fileno查找字典
server =socket ()
p = poll()
fdmap={server.fileno:server} #server.fileno即为server的IO对象 -
设置套接字为关注
p.register(server.fileno(),event) #event 为要关注的事件 -
循环监控IO
while True:
events=p.poll()
for fd,e in events:
pass -
处理发生的IO
2.3.3.epoll方法
使用方法 : 基本同poll相同
- 将生成对象函数改为 epoll
- 将所有关注IO事件类型变为EPOLL类型
epoll特点 :
- epoll是linux的专属多路复用方法
- epoll效率比select和poll要高
- epoll可以监控更多的IO (select 最多1024)
- epoll支持更多的触发事件类型(EPOLLET边缘触发)
3.多任务编程
一种思想,充分利用计算机的多核资源,同时运行多个任务,以提高程序的执行效率
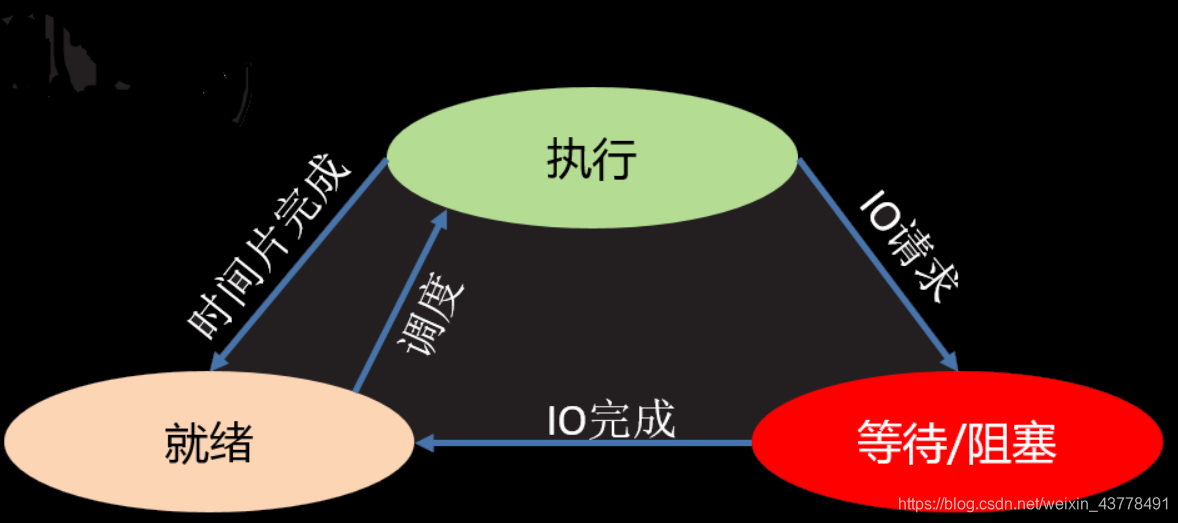
3.1.进程的创建
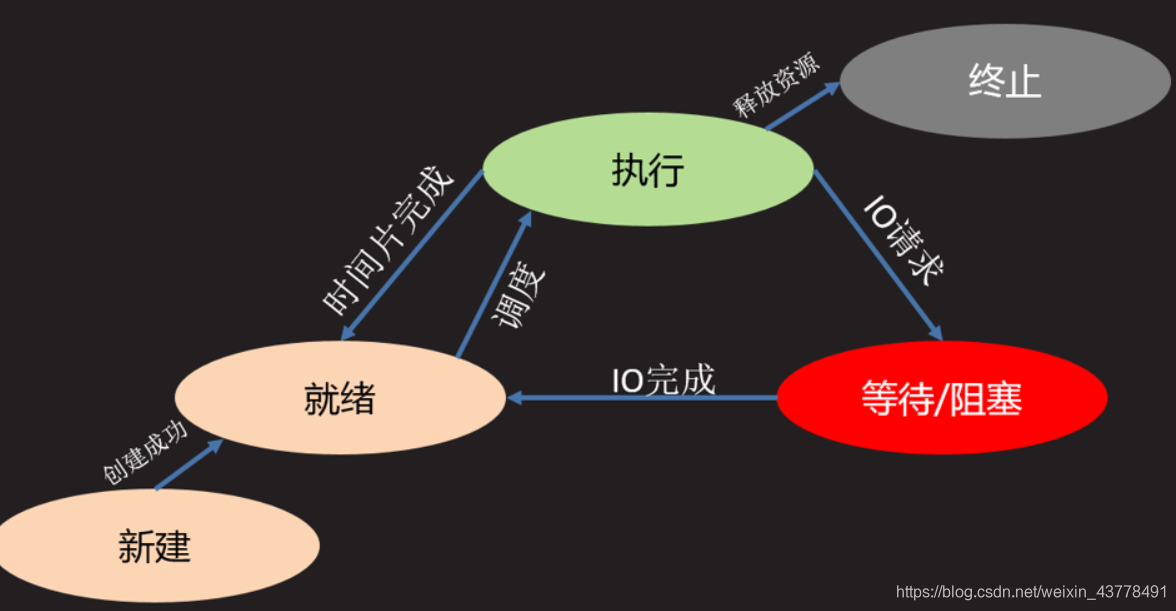
进程:程序在计算机中的一次运行过程。进程有两个模型,一个叫进程三态,一个叫五态。如图:
3.1.1.fork
使用模型:
pid = os.fork()
if pid < 0:
print("error")
elif pid == 0:
function1() #子进程做的事情
else:
function2() #父进程做的事情
这里就经常有个叫僵尸进程的面试问题:
僵尸进程 : 子进程先于父进程退出,且父进程没有处理子进 程退出行为,此时子进程就会成为僵尸进程。僵尸进程虽然结束但是会存留部分进程信息在内存中,大量 的僵尸进程会消耗系统资源,因此应该避免僵尸进程产生。
解决方法:通过创建二级子进程去解决,让二级子进程变成孤儿进程
当然也可以设置信号来处理,也是变成孤儿进程: signal.signal(signal.SIGCHLD,signal.SIG_IGN)
3.1.2.Process
使用模型:
def func(*args):
pass
p = Process(target=func,[name=‘process’], args=(),kwargs={})
p.start()
p.join()
这里的join可以处理僵尸进程
这里的进程有些属性说明下:
p.name 进程名称
p.pid 进程号
p.is_alive() 进程状态(查看是否在生命周期)
p.daemon()
默认是False 表示主进程退出,不会影响子进程继续运行,如果设置为True 此时主进程退出,子进程也会结束
要求在start()前设置
3.1.3.Pool
进程池:创建一定量的进程作为进程池,用来处理事件. 事件处理完毕后,进程不退出,而是继续等待处理其他事件.直到所有待处理事件处理完毕后统一销毁进程.增加了进程的重复利用,降低资源消耗.
使用模型:
pool = Pool(processes ) #processes为进程数量
pool.apply_async(func,args,kwds) #func 事件函数,args 元组 给函数按位置传参,kwds 字典 给函数按键值传参,这里是异步放入要执行的事件函数
(pool.apply(func,args,kwds)是同步放入要执行的事件函数)
pool.close()
pool.join()
3.2.进程间的通信
进程空间相对独立,资源无法直接获取.此时在不同的进程间需要进行消息传输,即进程间通信。
| 管道 | 消息队列 | 共享内存 | |
|---|---|---|---|
| 开辟空间 | 内存 | 内存 | 内存 |
| 读写方式 | 两端读写 | 先进先出 | 覆盖之前内容 |
| 效率 | 一般 | 一般 | 较高 |
| 使用特点 | 多用于父子进程 | 第三方库较多 | 操作需要注意争夺内存资源 |
3.2.1.管道 (pipe)
原理:在内存中开辟管道空间,生成管道操作对象,进程间使用同一组管道对象进行读写实现通信
这里设计到单管道和双管道。
3.2.2.消息队列 (queue)
原理:在内存中建立队列模型,进程通过队列对象将消息存入到队列,或者从队列取出消息,完成进程。遵从先进先出原则。
3.2.3.共享内存
原理: 在内存中开辟一个区域,对多进程可见,进程可以 写入内容或读取内容,但是每次写入的内容都会覆盖之前的。由于覆盖,则会产生争夺内存资源问题。使用时需要配合同步互斥一起使用。
3.2.4.信号量 Semaphore 和信号 signal
Semaphore 原理 : 给定一个数量,对多个进程可见.多个进程可以通过方法操作这个数量,达到协同工作的目的这个就是控制数量,和内容通信无关。
使用模型
sem = Semaphore(num) #创建信号量
sem.acquire() #将消耗一个信号量,当信号量为0会阻塞
func() #需要做的函数,
sem.release() #当函数事件执行完毕则增加一个信号量资源。
signal 原理 : 通过获取进程号,对其发出系统信号,来控制进程。
使用模型:
def fun3(sig,frame):
os.kill(os.getppid(),SIGUSR1)
def fun4(sig,frame):
os.kill(p.pid,SIGINT)
def spy():
signal(SIGINT,fun3)
while True:
fun2()
p = Process(target=fun1)
p.start()
signal(SIGUSR1,fun4)
th2.join()
3.3.线程
线程定义:
- 线程也是多任务编程方法
- 线程也可以使用计算机多核资源
- 线程被称为轻量级的进程,也是运行状态的概念
- 一个进程中可以包含多个线程,线程是进程的一 部分
- 线程是系统分配内核的最小单位
线程特征:
- 线程也是运行状态,有生命周期,消耗计算机资 源
- 多个线程之间独立运行互不干扰
- 一个进程内的线程共享进程资源
- 线程的创建删除消耗的系统资源远远小于进程
- 线程也有自己独立的资源,栈空间,命令集,ID等
线程的同步互斥 !!!很重要
共享资源(临界资源): 多个线程都可以操作的资源称为 共享资源
临界区 : 指一段代码,对临界资源操作的代码段
同步: 同步是一种合作关系,为完成任务,多个进程或者 线程之间形成一种协调调度,按照必要的步骤有 序执行一系列操作
互斥: 互斥是一种制约关系,当一个进程或者线程使用 临界资源时会进行加锁处理,此时另一个进程或 者线程就无法操作,直到解锁后才能操作
3.3.1线程的创建threading
和进程的创建差不多。就不重复了。
3.3.2线程的通信Event,Lock
通信方法 :使用进程空间中的全局变量通信
注意事项 : 共享资源争夺,往往需要同步互斥机制协调
协调有两个办法,要给是Event
通过设置事件对象的设置状态来,协调。即A线程需要等B线程运行结束时,设置事件对象为true时才可以运行,否则阻塞。
e = Event() #创建事件对象
e.set() 将e变为被设置状态
e.wait([timeout]) 果e是未设置的状态则阻塞
e.clear() 清除e的设置
lock 这个原理也差不多。
A,B线程用同一个lock锁, 当A线程运行了,就使用了lock,当运行完再释放lock,B线程运行也要使用lock,当lock被A线程使用了则只能等待A用完才能继续运行。
3.4协程
定义 : 纤程,微线程.是为非抢占式多任务产生子程序的计 算机程序组件.协程允许不同入口点,在不同位置暂停或者开始执行,简单来说,协程就是可以暂停执行的函数。
协程原理: 记录一个函数栈的上下文,进行协程的切换调度. 当一个协程函数暂停执行时会将上下文栈帧保存 起开,在切换回来时恢复到原来的执行位置,从而 继续执行。
协程优点:
1. 协程可以同时处理多个任务
2. 协程本质是单线程,资源消耗少
3. 协程无需切换的开销,无需同步互斥
协程缺点:
1. 无法利用计算机多核
4.总结(一些常见面试题)
大部分答案在前面都有介绍
1.进程线程的区别有哪些
进程是系统资源分配的最小单位,线程是系统CPU运算的最小单位
一个进程是由1个或者多个线程。
进程的空间独立,数据相互不干扰,所以需要占用较多系统资源,线程是共有享进程的资源,占用的资源较少,线程拥有高并发特性
真正在CPU上运行的是线程
2.在什么情况下使用进程或线程
多进程适合在CPU密集的操作(例如科学计算,位数较多的运算)
多线程适合IO密集的操作(读写较多的操作,爬虫)
3、什么是同步互斥,你在什么情况下使用,如何使用
同步互斥中,存在一个叫共享资源,指多个线程可以操作的资源。同步互斥指的是为了完成任务,多个进程或线程进行协调调度
,单必须按照必要的步骤有序执行一系列操作,当一个进程或线程使用一个共享资源的适合,其他资源不能进行操作,直到解锁才行
4、死锁是什么?如何避免死锁
两个进程或者线程在执行的时候,发生相互抢资源的现象导致,两个互相等待的现象,若无外力作用一直等待的情况。
避免方法:
1,在加多个锁的时候设置超时,若超时,解开自身的锁,其他资源运行后再执行
2,每个锁变序号,加锁的时候按照序号去加,(5个哲学家在圆桌上吃饭的问题,左右手的两个筷子问题)
3,!!!(银行家贷款分配资源问题,并行时每次总会给能满足条件的客户优先进行放款)
从当前状态出发,逐个按安全序列检查各客户谁能完成其工作,然后假定其完成工作且归还全部贷款,再进而检查下一个能完成工作的客户,…。
如果所有客户都能完成工作,则找到一个安全序列,
5、进程间通信方法有哪些?各自有什么特点?
pipe管道 queue 消息队列manager().queue() Value 共享空间 Array
开辟空间 内存 内存 内存
读写效率 一般 一般 较高
特点 父子进程间 第三方库多 需注意资源的抢夺
pipe管道有两种, 半双工管道和双工管道,且只能在有亲缘关系的进程中使用。
信号量:通过计数器的方式,控制多个线程多共享资源的访问,用于多线程间的同步,一般作为锁机制。
消息队列: 消息的链表,存放在内核中,可以承载字节流等
共享内存:映射一段能被其他进程所访问的内存,由一个进程创建,多个进程可以访问。常配合其他通信机制配合
套接字。
6、进程池原理是什么,怎么用
在需要使用大量的进程去完成任务时,此时就需要使用进程池,进程池是由一定量的进程创建的,当进程的任务完成时,不销毁,
继续等待处理其他事件,直到所有待处理事件处理完成后统一销毁,增加了进程的重复利用,降低资源消耗。
7、你是如何处理僵尸进程的
1.创建二级子进程。
2.父进程处理已结束的子进程。