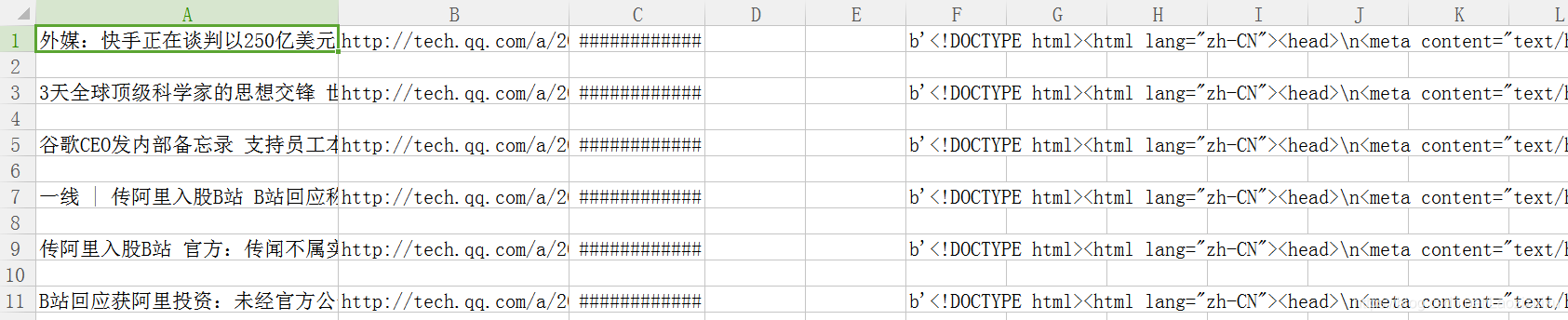
昨天收到一道面试题爬取http://tech.qq.com/articleList/rolls/的新闻,当时看到的时候简直简单爆了,事实证明的确是,将将将,就是这个页面,很普通啊,开干。。。
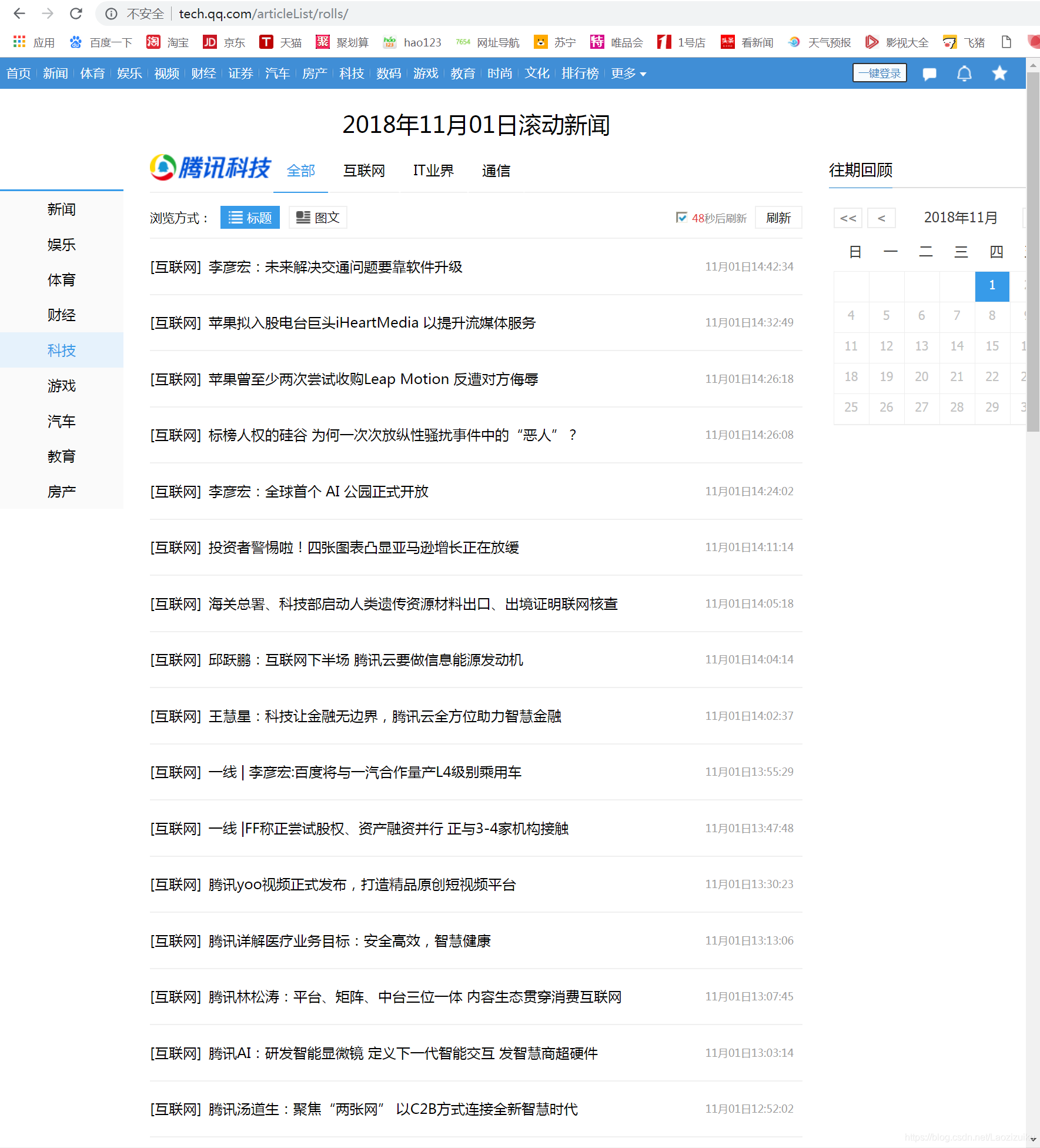
1.首先发现在查看源代码的时候看不见这些数据,所以需要js抓一下,注意到url的最后一个参数是个时间戳,然后就是headers里一定要放上referer,不然获取不到的(就因为这个referer,让我手足无措的找了半个小时哪的问题,所以说一定要细心)
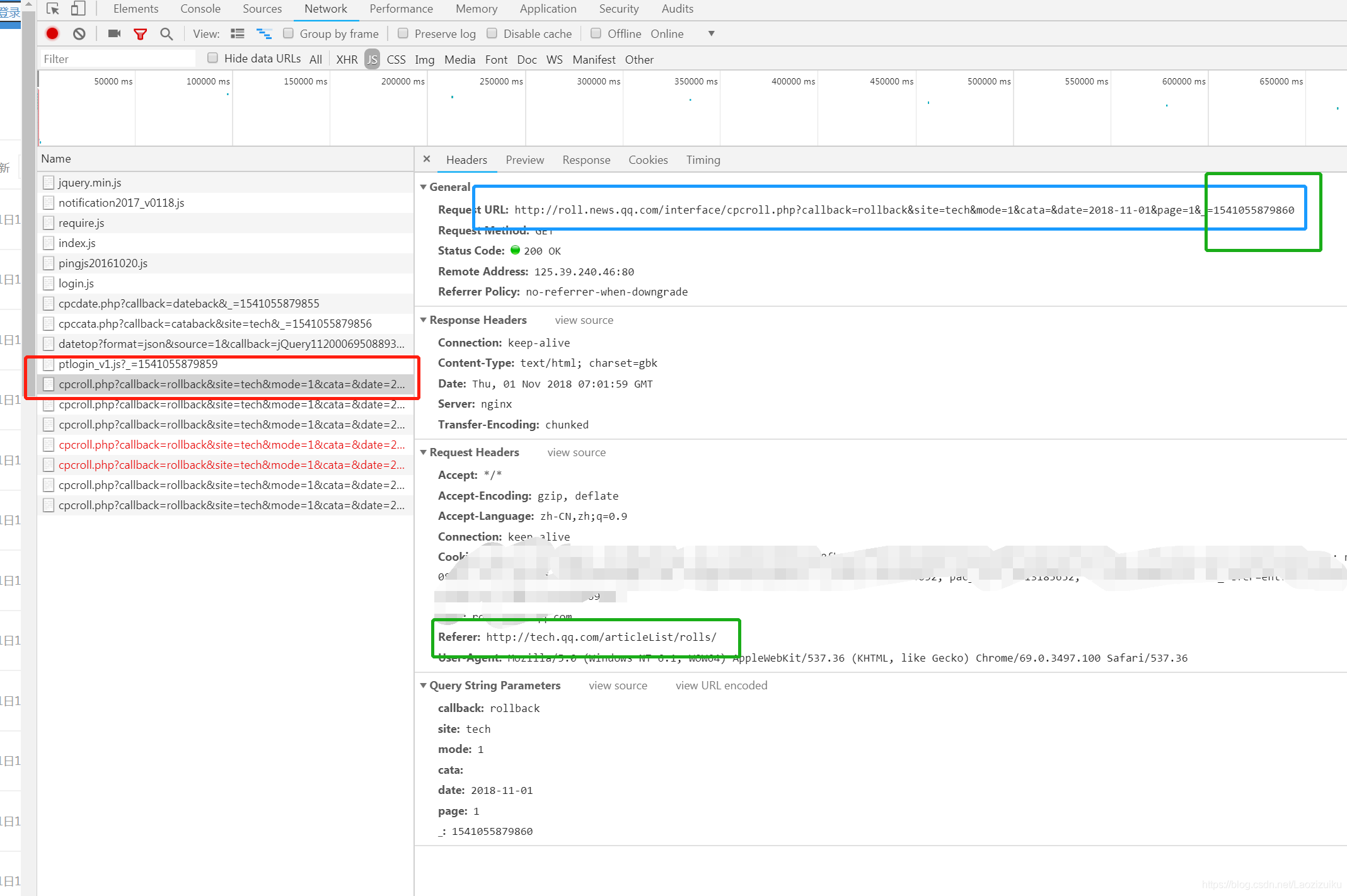
2.requests.get(url),获取一下内容,你就会神奇的发现,已经爬下来了,嘤嘤嘤~
now=int(time.time()*1000)
# 新闻获取的接口,其中page可以切换1,2页,now可以切换时间
url="http://roll.news.qq.com/interface/cpcroll.php?callback=rollback&site=tech&mode=1&cata=&date=2018-10-31&page=1&_=%s"%now
headers={
'Connection': 'keep - alive',
'User-Agent': 'Mozilla/5.0 (Android 4.4; Mobile; rv:41.0) Gecko/41.0 Firefox/41.0',
'Referer': 'http://tech.qq.com/articleList/rolls/'
}
response=requests.get(url,headers=headers)
text=response.text.strip()
print(text)
3.因为获取到的值不是,dict或者是json的样子,所以做一个正则提取出json,然后eval转成dict,然后就可以搞事情了
pattern = re.compile(r'.*rollback\((.*)\)')
m = pattern.match(text)
if m :
string=m.group(1)
dict=eval(string)
for each in dict['data']['article_info']:
title=each['title']
url=each['url'].replace("\\","")
time_tech=each['time']
img=each['img']
desc=each['desc']4.保存成csv,因为本来打算存数据库的,后来想想还是直接存成文件吧,省事,还有就是不知道我的open(file,“a+”)不能读,可能是直接到最后一行了?所以我就在不存在的时候创建一个,存在就open(file,“r+”), html_word(url)只是一个爬取具体新闻页的东西的函数,如果需要可以丰富一下,所以直接上完整代码
#coding=utf-8
import requests
import time
import re
import csv
import os
# 爬取新闻页内容,只是保存了整个的内容
def html_word(url):
response=requests.get(url)
text=response.text.encode('utf-8')
return text
now=int(time.time()*1000)
# 新闻获取的接口,其中page可以切换1,2页,now可以切换时间
url="http://roll.news.qq.com/interface/cpcroll.php?callback=rollback&site=tech&mode=1&cata=&date=2018-10-31&page=1&_=%s"%now
headers={
'Connection': 'keep - alive',
'User-Agent': 'Mozilla/5.0 (Android 4.4; Mobile; rv:41.0) Gecko/41.0 Firefox/41.0',
'Referer': 'http://tech.qq.com/articleList/rolls/'
}
response=requests.get(url,headers=headers)
text=response.text.strip()
print(text)
pattern = re.compile(r'.*rollback\((.*)\)')
m = pattern.match(text)
if m :
string=m.group(1)
dict=eval(string)
for each in dict['data']['article_info']:
title=each['title']
url=each['url'].replace("\\","")
time_tech=each['time']
img=each['img']
desc=each['desc']
# 存放到csv文件中
filename='Stu_csv.csv'
if not os.path.exists(filename):
course = open(filename,'w',encoding='utf8')
course.close()
with open(filename,"r+") as csvfile:
reader = csv.reader(csvfile)
column = (row[1] for row in reader if row)
if url in column:
print("我存在了")
continue
else:
word=html_word(url)
csv_write = csv.writer(csvfile, dialect='excel')
# 写入具体内容
csv_write.writerow((title,url,time_tech,img,desc,word))
print("我执行了一次")
ok,有什么问题可以随时问哦