引文:
“云应用”:终端与服务(云)端互动的应用,终端操作同步云端,通过云端备份保留终端数据。
它把传统软件“本地安装、本地运算”的使用方式变为”即取即用”的服务。
说白了就是,大厂把你的东西放在云上,你拿个浏览器就能操纵他们。包括云函数、云平台、云虚拟机、云服务器、云集群、云数据库、云网站、云男友、云女友……
云函数介绍
这个云函数好在哪里呢。你把你的程序写完挂在那里,托管给它就ok。设置个自动触发。它就会按时执行函数。所以它能干什么,那就看你的想象力了。
比如说之前看某位仁兄写过一个某学校的自动体温填报的python程序,说是要放到服务器上设置定时任务自动执行。这就太蠢了,为了一个程序弄了个系统了出来,大炮打蚊子。而放在云函数上执行就再好不过了。
| 云函数 | 云服务器 | |
| 费用 | 免费额度:100万次/月 | 10元/月 |
| 量级 | 函数级 | 系统级 |
| 操作难度 | 安装依赖、写好函数就行 | 需要从一个系统开始 |
| 触发器 | 有专门的触发器,非常简洁 | 设置系统定时任务,麻烦 |
他写的整个程序还是很符合云应用的部署场景的。那我们就遵照中华民族的传统美德,助人为乐的帮他解决一下代码的部署问题。下面就直接大段引用这位仁兄的代码实现过程了。代码实现过程之后是由我来写的部署过程。
原理:
体温的提交就是发一条post请求而已(如下图所示)。只要复制这条post请求,让机器每天在指定时间发送就可以了。
技术关键:
获取cookie。经过这几天的不断尝试,发现cookie是否有效决定能否填报成功。
此cookie持续时间很短。
我的实现方案:
- 获取提交体温时的post,并且转换成python代码段使得该post可以无限次重复利用。
- 获取新的cookie替换掉代码段中的旧cookie
- 把前两步写成一个程序放在服务器上,每天定时运行。
(帮这位仁兄打个码)
具体实现过程
一、拥有随时发送post的能力
先到填报网站把需要填的都填了
打开开发者工具,点到network,然后提交体温
找到那一条post请求,按右键-> copy -> copy as curl
进入这个网站,可以把curl直接转换成python代码
至此,我们已经可以随时发送post,然后该考虑如何获取新的cookie了。由于该小程序的页面跳转很多,我选择通过自动化测试工具,使用南开账号密码登陆,然后拿到cookie。具体的页面跳转逻辑可以参考第一天的探索记录
https://blog.csdn.net/weixin_42175197/article/details/107378107
二、随时获取最新的cookie
按照链接里文章所提供的网页跳转逻辑,用浏览器驱动和自动化测试直接写就行。没什么好讲的。
三、把前两步拼装起来,直接放代码了
/* 代码说明:
* 经过验证,发现url中的时间戳不起作用。出于周全的考虑,还是重写了url里的时间戳。
* 最后把主函数里的唯一一个语句的两个参数换成自己的学号和密码(需要通过南开大学统一认证)。后附验证网址
* 在家同学的版本需要按照步骤一,重新改一下data部分,毕竟原代码里填的是我家的地址。
* 当然,如果你懂url解码的的话,可以直接从data q2和q10show里面改就好。下面放一个解码网站的链接
*/
南开大学统一身份认证网址
https://sso.nankai.edu.cn/sso/login?service=https://i.nankai.edu.cn/user/simpleSSOLogin
编码和解码
http://tool.chinaz.com/tools/urlencode.aspx
在家同学的版本
import time import json import requests from selenium import webdriver #根据账号密码获取cookie def getCookie(uName,pWord): browser = webdriver.Chrome() browser.implicitly_wait(10) url = 'https://feishu.nankai.edu.cn/?appid=229' browser.get(url) browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div[2]/div/div[1]/div/div').click() browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div[1]/div/div[2]/div/div[7]/div').click() browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div/div/div[3]/div/div[3]/div/div/input').send_keys('nankai') browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div/div/div[3]/div/div[5]').click() browser.find_element_by_id('inputUrpid').send_keys(uName) browser.find_element_by_id('inputPassword').send_keys(pWord) browser.find_element_by_xpath('/html/body/div[3]/div[2]/form/div[3]/div[2]/button').click() time.sleep(10) try:#处理弹窗 alert = browser.switch_to.alert while(alert): alert.accept() time.sleep(1) alert = browser.switch_to.alert finally: c = browser.get_cookies()[0]['value'] print('get cookie: ',c,' from accout', {'uName':uName,'pWord':pWord}) browser.close() return c #传入新的cookie并发送post def post(cookie): headers = { 'authority': 'jkcj.nankai.edu.cn', 'accept': '*/*', 'x-requested-with': 'XMLHttpRequest', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', 'content-type': 'application/x-www-form-urlencoded; charset=UTF-8', 'origin': 'https://jkcj.nankai.edu.cn', 'sec-fetch-site': 'same-origin', 'sec-fetch-mode': 'cors', 'sec-fetch-dest': 'empty', 'referer': 'https://jkcj.nankai.edu.cn/mobile/register/', 'accept-language': 'zh-CN,zh;q=0.9', 'cookie': 'PHPSESSID='+cookie ,#把cookie换成传进来的参数 } params = ( ('time', str(int(1000*time.time())*1000)), ) data = { #这里需要重写一下data,要不然报出去是我家的地址 'data': '{"q1":"36.2","q16":"36.2","q17":"36.2","q2":"\u5929\u6D25","q10_show":"\u6D25\u5E02/\u5929\u6D25\u5E02/\u6D77\u533A","q10":"120000/120000/120116","q9":"\u5BBF\u820D","q4":"N","q5":"N","q20":"N","q11":"N","q12":"N","q13":"green","q18":"2","q19":"2","q8":""}', 'status': '1' } r = requests.post('https://jkcj.nankai.edu.cn/healthgather/index/addGather',headers=headers, params=params, data=data) print('Send !') #把前两步打包 def Send(uName,pWord): cookie = getCookie(uName,pWord) post(cookie) print() #这里换成自己的学号密码 if __name__ == '__main__': Send('17129**','password')留校同学的版本
import time import json import requests from selenium import webdriver #根据账号密码获取cookie def getCookie(uName,pWord): browser = webdriver.Chrome() browser.implicitly_wait(10) url = 'https://feishu.nankai.edu.cn/?appid=229' browser.get(url) browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div[2]/div/div[1]/div/div').click() browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div[1]/div/div[2]/div/div[7]/div').click() browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div/div/div[3]/div/div[3]/div/div/input').send_keys('nankai') browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div/div/div[3]/div/div[5]').click() browser.find_element_by_id('inputUrpid').send_keys(uName) browser.find_element_by_id('inputPassword').send_keys(pWord) browser.find_element_by_xpath('/html/body/div[3]/div[2]/form/div[3]/div[2]/button').click() time.sleep(10) try:#处理弹窗 alert = browser.switch_to.alert while(alert): alert.accept() time.sleep(1) alert = browser.switch_to.alert finally: c = browser.get_cookies()[0]['value'] print('get cookie: ',c,' from accout', {'uName':uName,'pWord':pWord}) browser.close() return c #传入新的cookie并发送post def post(cookie): headers = { 'authority': 'jkcj.nankai.edu.cn', 'accept': '*/*', 'x-requested-with': 'XMLHttpRequest', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', 'content-type': 'application/x-www-form-urlencoded; charset=UTF-8', 'origin': 'https://jkcj.nankai.edu.cn', 'sec-fetch-site': 'same-origin', 'sec-fetch-mode': 'cors', 'sec-fetch-dest': 'empty', 'referer': 'https://jkcj.nankai.edu.cn/mobile/register/inschool.html?time=time='+str(int(1000*time.time())), 'accept-language': 'zh-CN,zh;q=0.9', 'cookie': 'PHPSESSID='+cookie ,#把cookie换成传进来的参数 } params = ( ('time', str(int(1000*time.time())*1000)), ) data = { 'data': '{"q1":"36.2","q16":"36.2","q17":"36.2","q2":"\u5929\u6D25","q10_show":"\u5929\u6D25\u5E02/\u5929\u6D25\u5E02/\u6EE8\u6D77\u65B0\u533A","q10":"120000/120000/120116","q9":"\u5BBF\u820D","q4":"N","q5":"N","q20":"N","q11":"N","q12":"N","q13":"green","q18":"2","q19":"2","q8":""}', 'status': '1' } r = requests.post('https://jkcj.nankai.edu.cn/healthgather/Inschool/addInschoolGather',headers=headers, params=params, data=data) print('Send !') #把前两步打包 def Send(uName,pWord): cookie = getCookie(uName,pWord) post(cookie) print() #这里换成自己的账号密码 if __name__ == '__main__': Send('17129**','password')
四、可参考的网站
1.体温填报网站登陆的跳转逻辑
https://blog.csdn.net/weixin_42175197/article/details/107357825
2.南开大学统一认证门户,验证自己的账号密码
https://sso.nankai.edu.cn/sso/login?service=https://i.nankai.edu.cn/user/simpleSSOLogin
3.抓post和发post
https://www.cnblogs.com/LXP-Never/p/11382216.html
4.将curl转换成其他语言
5.编码和解码
http://tool.chinaz.com/tools/urlencode.aspx
6.python库导入
pip install request pip install selenum7.谷歌浏览器驱动下载地址和使用方法
https://blog.csdn.net/dpl12/article/details/102795562
8.自动化测试工具的用法
https://www.jianshu.com/p/3aa45532e179
9.服务器自动执行python脚本
https://www.cnblogs.com/dahuag/p/8994036.html
总结:
一.认识世界和改造世界必须勇于创新:
创新是前进的保障,必须坚决反对教条主义。任何事物的生命力都在于创新,只有创新才能发展。而创新又是噫坚持和继承为前提的。只有把继承和创新统一起来,才能真正顺应时代和实践的呼唤,提现与时俱进的要求。
二.从必然走向自由
认识世界和改造世界的过程就是从必然走向自由的过程。人类的发展史,就是不断的必然走向自由的历史。
自由——人在活动中通过【认识和利用必然】所表现的自觉自主的状态。
必然——固有的规律。
自由是【对必然的认识】和【对客观世界的改造】。
某位导师曾说:“自由就在于根据对自然界的必然性的认识来支配我们自己和外部自然……
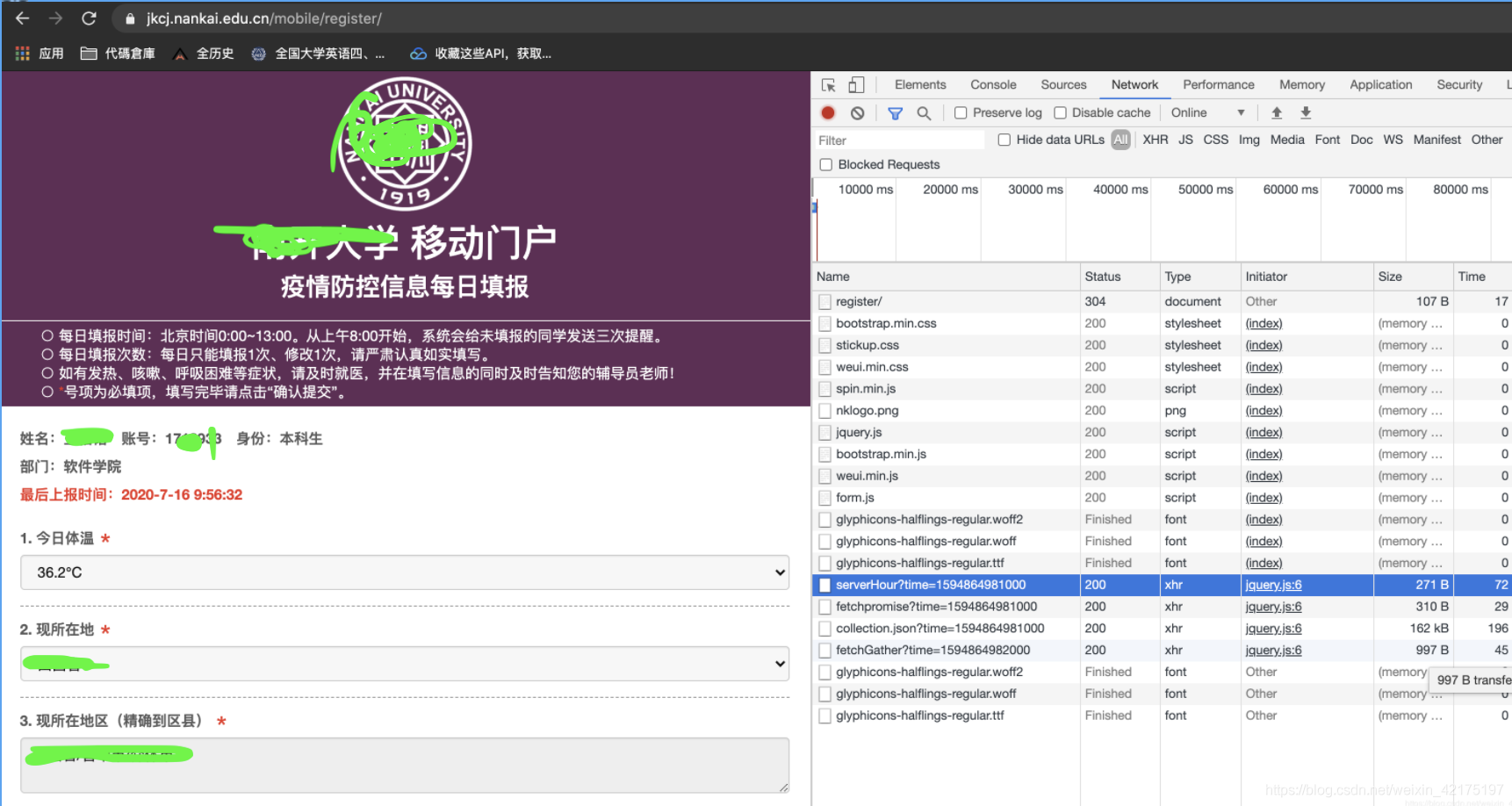
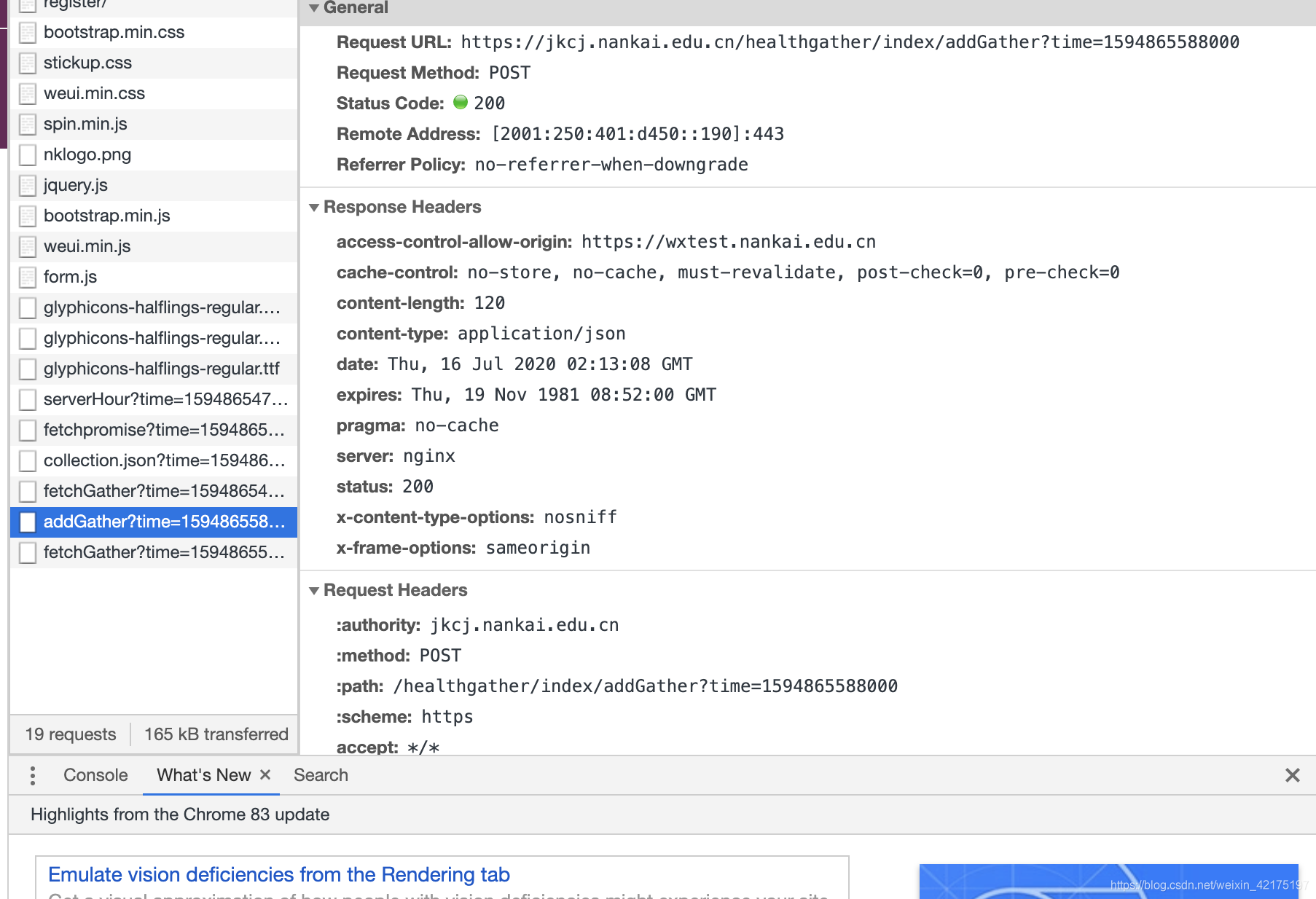
部署过程:
总体思路:
- 把代码在本地运行起来
- 把本地的运行环境打包放到云函数环境里。要把python的依赖、chrome浏览器和它的驱动都放上去。
- 把运行好的代码复制粘贴到云函数里面
- 测试成功后,设置一个触发器
技术关键:思路里的第二点较难实现
实现过程
一、本地运行代码
先把那位仁兄的代码在本地跑起来再说。运行的话,需要三个东西,python、chrome浏览器、chrome浏览器驱动。同时python需要pip install selenium和request两个库。参照那位仁兄给的链接就可以都学会。
恰巧我和那位仁兄也是一个学校的,把他的代码拿来,装好依赖后,改一改学号和密码就跑起来了。
而且竟然可以突破填写时间和填写次数的限制!!!真神奇!!!


二、打包环境
这里是我失败的地方,经过长达十五个小时的尝试,还是没有解决问题。但总结出了以下的经验。
这个云函数的关键在于:chrome浏览器好几百兆,怎么把它传到云函数上这个问题卡死了我整个伟大构想。我总共尝试了三种方案。下面简单总结一下。
1. 亚马逊
亚马逊的云服务是最先进的,没有之一。云函数在它这里叫【lambda】,而且它有这样的服务:直接把chrome转成了api,你就不需要上传浏览器了,导入它的官方包用就行了,下面的链接是它的项目地址。应该说是最省心的一种方案。然而,亚马逊毕竟出身不好,往上倒几代全是资本家不说,又非我族类,其心必异。由于众所周知的原因,他用不了。
2.阿里云
阿里云提供的服务叫做【函数计算】,执行环境是linux,可以通过fun、fcli、docker把你的环境打包上传,更方便一点,直接在ide里面下载插件alibaba cloud kitool,一键上传你的环境。但由于这个更侧重的是serverless什么的,我学艺不精不太懂。只想着怎么把chrome浏览器传上去。它的文件大小限制是50m,而浏览器多达数百m,遂失败。由于此时心情已经极度暴躁,遂放弃。第二天调整心态,决定翻出来几年前的老古董phantomJS无头浏览器,只有数十m,但由于过于不稳定,没法运行代码,遂舍弃。后经过咨询阿里云专业技术人员,了解到可以为我的函数挂在nas文件系统,nas是不限大小的,鼓捣一番后没弄明白。又看了阿里云的oss存储服务,鼓捣一番后没弄明白。由于此时心情已经极度暴躁,遂放弃。
3.腾讯云
腾讯云提供的服务叫【云函数】,执行环境也是linux,也可以打包环境上传,但是我在函数界面找不到上传的按键。。。腾讯的特色应该是cloud studio,拿个浏览器就能写代码,还可以多人同时一起写,也能一键部署到云应用上。但由于此时心情已经极度暴躁,遂放弃。
4. 其他方案
用node使用浏览器是较为方便的,似乎有不用上传浏览器,只加载npm包就能直接用的办法。但由于没什么耐心看下去,遂放弃。
| 平台 | 失败的方案 | 失败原因 |
|---|---|---|
| 亚马逊 | lambda+lambdium | 非我族类 |
| 阿里云 | 直接上传chrome浏览器 | 文件过大 |
| 使用phantomJS无头浏览器 | 不稳定 | |
| 使用oss对象存储服务 | 没弄明白 | |
| 使用nas挂载 | 没弄明白 | |
| 使用docker+fun+fcli一键上传环境 | 没弄明白 | |
| 使用插件alibaba cloud kitool一键上传环境 | 没弄明白 | |
| 腾讯云 | 直接上传chrome浏览器 | 找不到上传按键 |
| 使用云应用开发平台cloud studio | 没弄明白 | |
| 其他 | 使用node.js | 没弄明白 |
三、使用服务器实现自动化
自我辩解:在事物的发展中,既有决定性因素,又有多样性因素。决定性因素决定着事物不断向前发展,而多样性因素使得事物前进的线路不是直线,而是迂回的。比如这件事情中,我探索的热情和不断增加的知识就是决定性因素,而各种部署方案的选择就是多样性因素。从平面空间上看我是绕了一圈回到了起点(还是用了服务器来搭载),但如果放在立体空间中我其实是站在了更高的平面的投影点上,即经历了否定之否定的过程,螺旋形的上升了一次。正所谓“看山是山,看山不是山,看山还是山;看云服务是云服务器,看云服务不是云服务器,看云服务还是云服务器”。
为了让自己的心情变的舒畅,也为了让外行人看不懂,云服务器选择阿里云的字符界面linux。
下面将会是从新建服务器开始的每一步详细步骤(为此我特地把服务器重装了一遍,边写博客边做)
新建一个服务器实例
使用vnc远程登陆
输入远程连接密码(不是系统密码。第一次登陆要点修改进行设置)
 使用root用户名和系统密码进入系统
使用root用户名和系统密码进入系统
点击右上角的复制命令可以把本地的文本传进去。如果是比较短的命令还是自己手打把。
先来安装 selenium 和 requests
pip3 install selenium
pip3 install requests
然后安装chrome,这个比较麻烦。需要用到vim编辑器,这里就不讲vim的用法了。
vim /etc/yum.repos.d/google-chrome.repo 输入一下文本然后保存:
[google-chrome]
name=google-chrome
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch
enabled=1
gpgcheck=1
gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub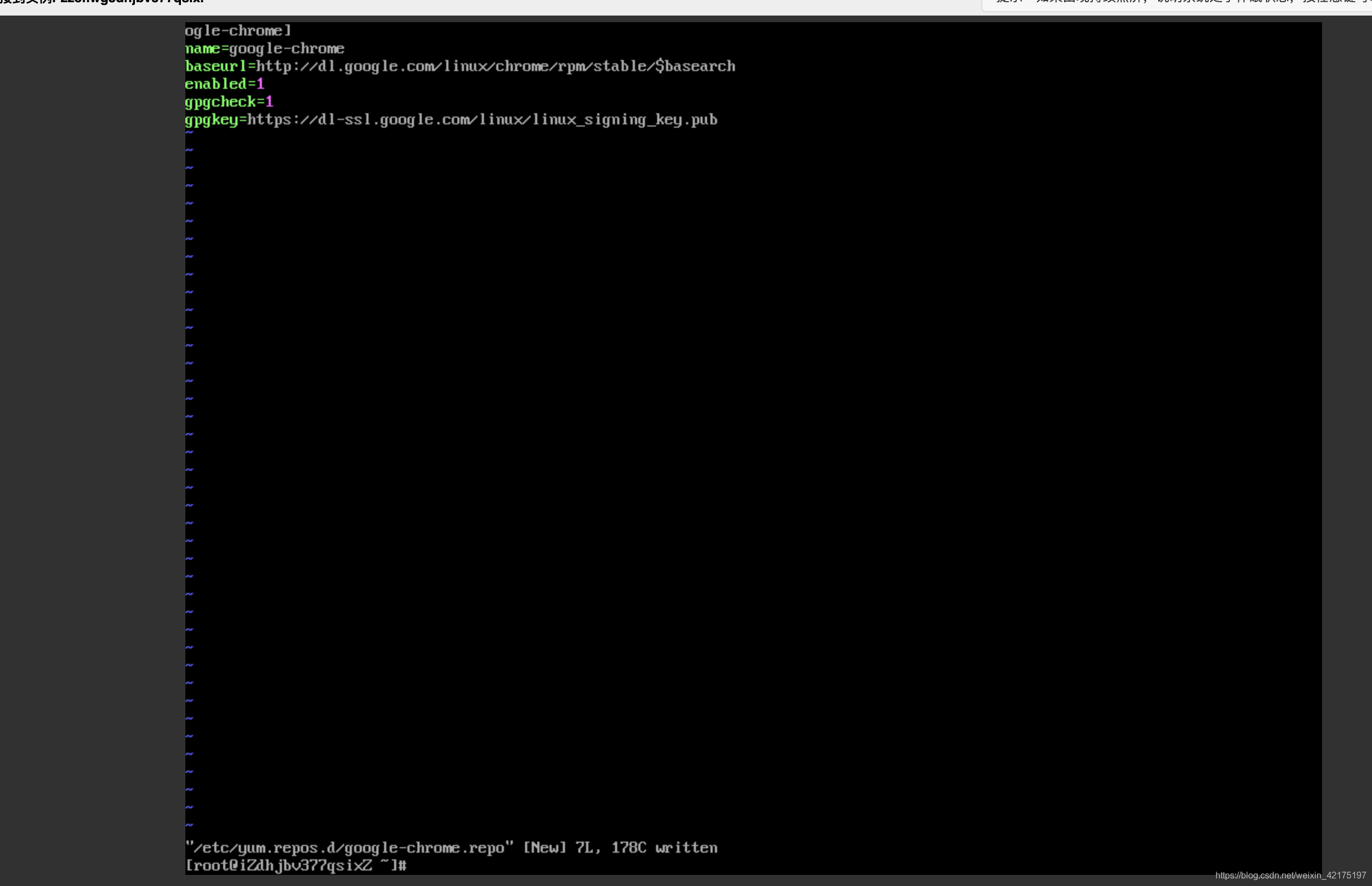
然后用以下命令安装chrome
yum install google-chrome-stable --nogpgcheck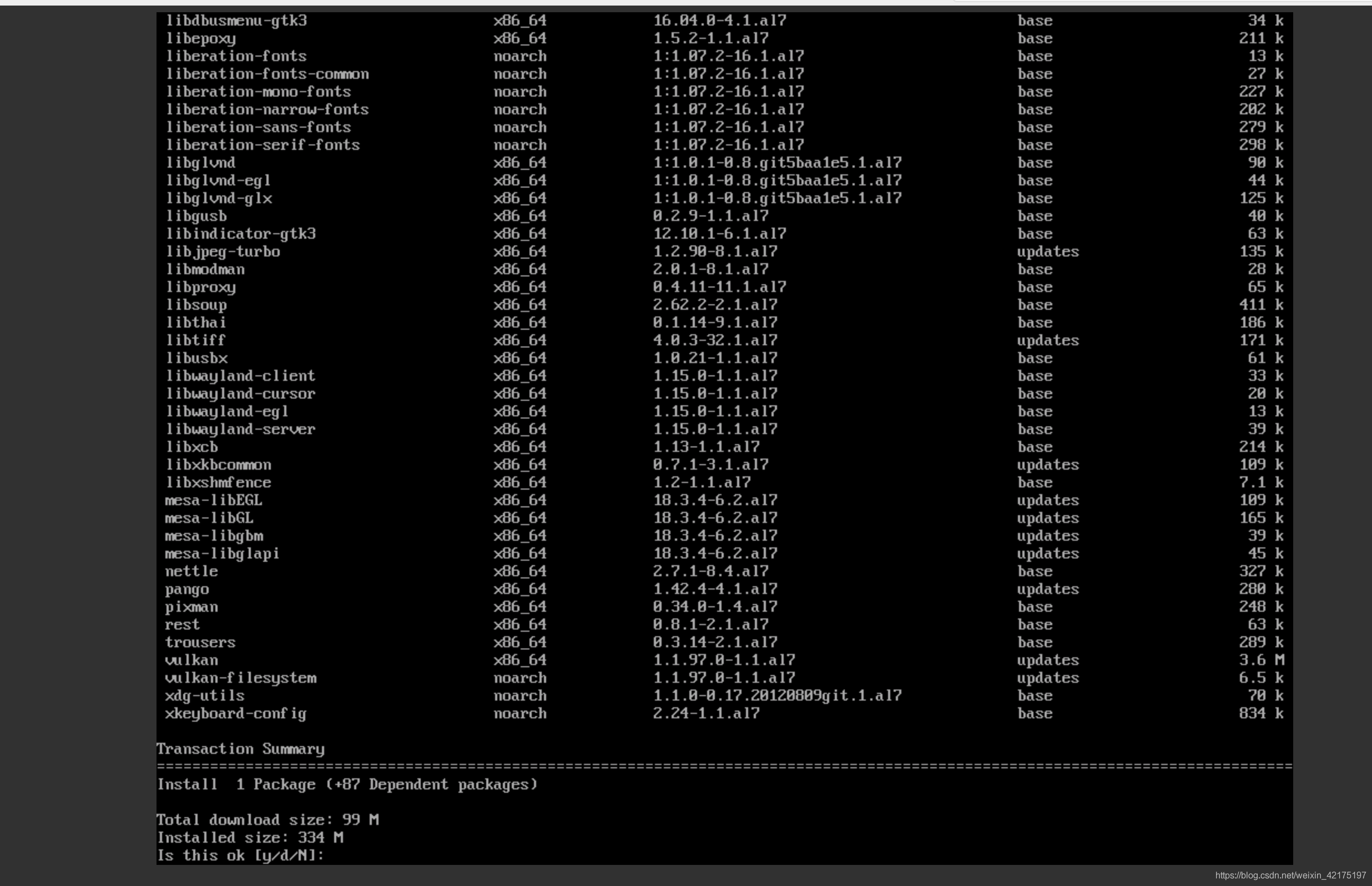
期间会让确认,输入y敲回车就好
完成安装后查看版本
google-chrome --version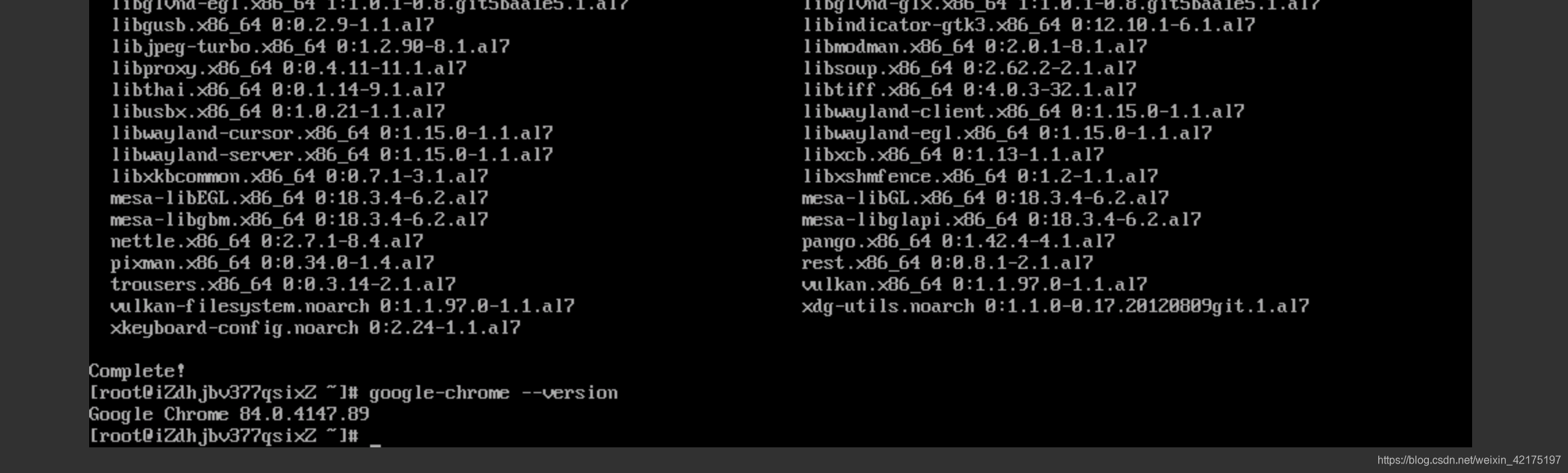
记住这个版本号,比如我的是84.0.4147,然后进入淘宝镜像站
找到自己的版本点进去
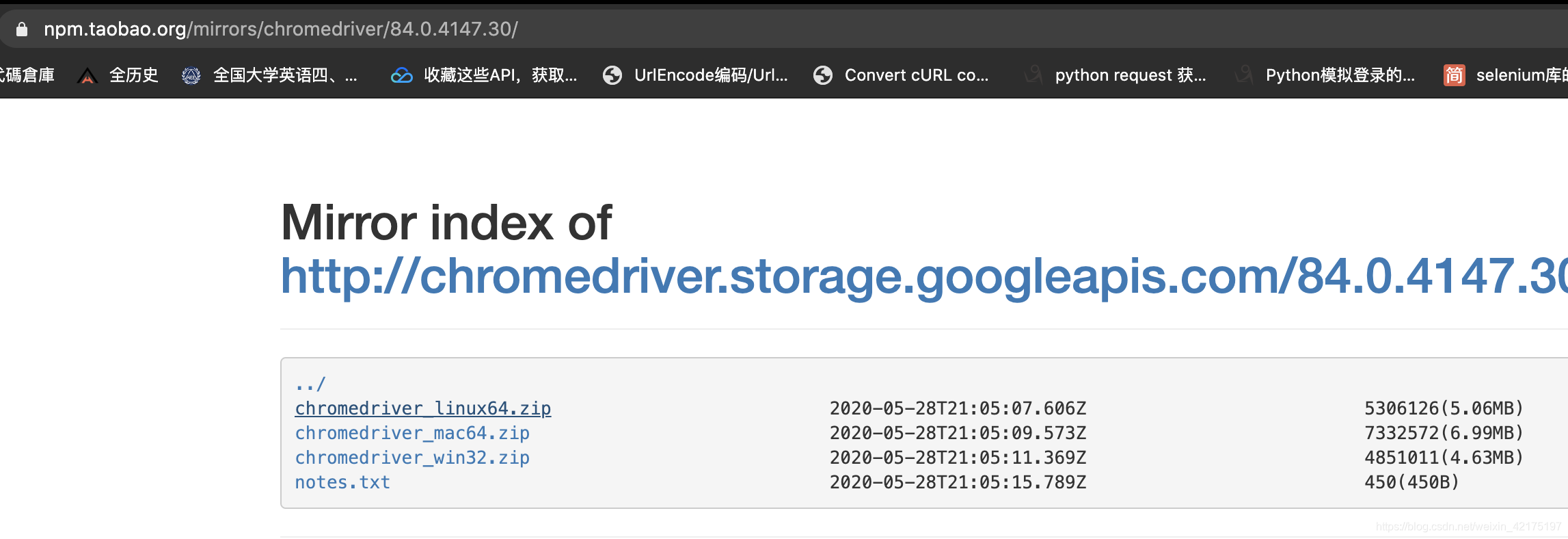
我们选择linux版本的,但我们不能直接下载。因为我们在字符界面得用命令行下载。。所以我们拼接一个字符串命令
wget http://chromedriver.storage.googleapis.com/84.0.4147.30/chromedriver_linux64.zip
下载成功后我们不能直接用,要下载一个解压的程序
yum install unzip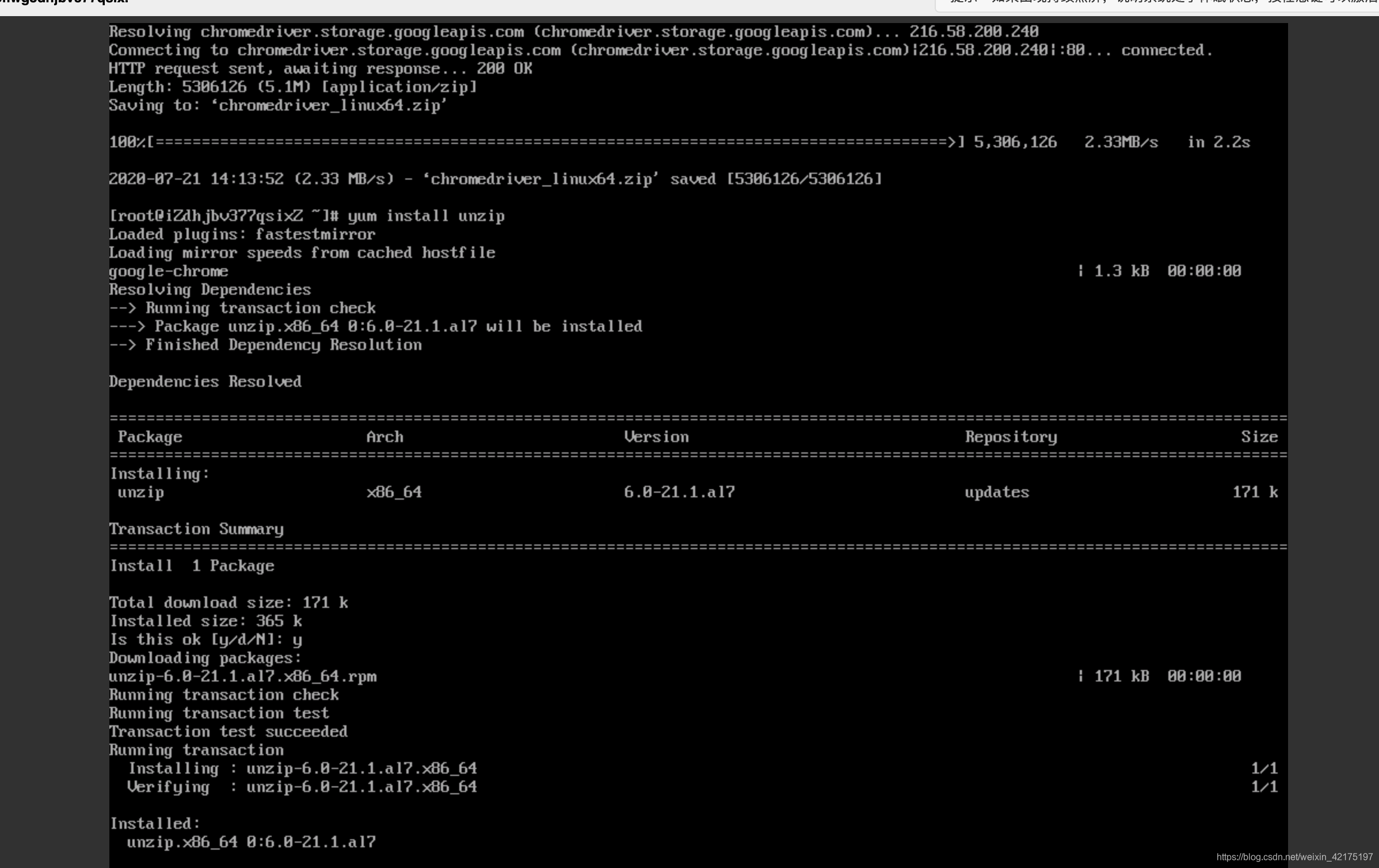
然后解压并修改权限。然后输入输入ls查看当前目录文件,已经在这里了
unzip chromedriver_linux64.zip
chmod 755 chromedriver
ls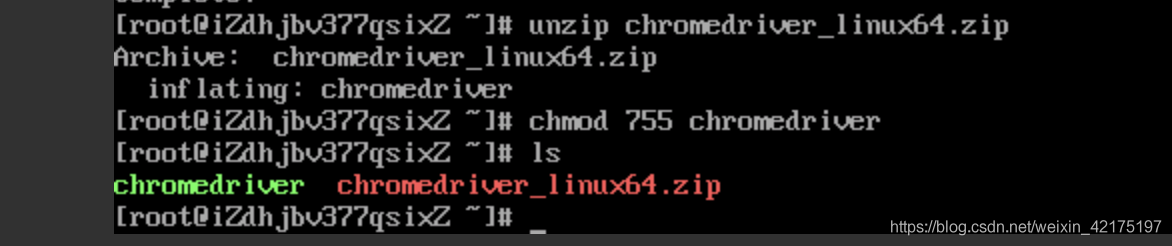
至此,服务器环境都配好了。下一步我们要开始弄代码了。
由于是字符界面,我们必须使用无头浏览器。那我们现在本地电脑上重写一下那位仁兄的代码
/* 代码说明
* 你不需要在本地运行代码,我是因为考虑周全才这样做。你直接搬到服务器上就行
* 重写部分1: 删除所有中文注释
* 重写部分2: 把在家同学在校同学直接合并。不用改任何data,只把一行的学号和密码换成自己的就行
*/
# coding: utf-8
import requests
from selenium import webdriver
import time
def getCookie(uName, pWord):
print("start")
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('window-size=1600x900')
options.add_argument('--disable-gpu')
options.add_argument('--hide-scrollbars')
options.add_argument('blink-settings=imagesEnabled=false')
options.add_argument('--headless')
browser = webdriver.Chrome(options=options,executable_path='./chromedriver')
browser.implicitly_wait(10)
url = 'https://feishu.nankai.edu.cn/?appid=229'
browser.get(url)
browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div[2]/div/div[1]/div/div').click()
browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div[1]/div/div[2]/div/div[7]/div').click()
browser.find_element_by_xpath(
'//*[@id="root"]/div/div[6]/div[1]/div/div/div[3]/div/div[3]/div/div/input').send_keys('nankai')
browser.find_element_by_xpath('//*[@id="root"]/div/div[6]/div[1]/div/div/div[3]/div/div[5]').click()
browser.find_element_by_id('inputUrpid').send_keys(uName)
browser.find_element_by_id('inputPassword').send_keys(pWord)
browser.find_element_by_xpath('/html/body/div[3]/div[2]/form/div[3]/div[2]/button').click()
time.sleep(10)
try:
alert = browser.switch_to.alert
while (alert):
alert.accept()
time.sleep(1)
alert = browser.switch_to.alert
finally:
c = browser.get_cookies()[0]['value']
print('get cookie: ', c, ' from accout', {'uName':uName,'pWord':pWord})
browser.close()
return c
def post(cookie):
headers = {
'authority': 'jkcj.nankai.edu.cn',
'accept': '*/*',
'x-requested-with': 'XMLHttpRequest',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'origin': 'https://jkcj.nankai.edu.cn',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://jkcj.nankai.edu.cn/mobile/register/',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'PHPSESSID='+cookie ,
}
params = (
('time', str(int(1000*time.time())*1000)),
)
data = {
'data': '{"q1":"36.2","q16":"36.2","q17":"36.2","q2":"\u5929\u6D25","q10_show":"\u6D25\u5E02/\u5929\u6D25\u5E02/\u6D77\u533A","q10":"120000/120000/120116","q9":"\u5BBF\u820D","q4":"N","q5":"N","q20":"N","q11":"N","q12":"N","q13":"green","q18":"2","q19":"2","q8":""}',
'status': '1'
}
requests.post('https://jkcj.nankai.edu.cn/healthgather/index/addGather',headers=headers, params=params, data=data)
print("Home temperature send!")
headers['referer'] = 'https://jkcj.nankai.edu.cn/mobile/register/inschool.html?time=time='+str(int(1000*time.time()))
data = {
'data': '{"q1":"36.2","q16":"36.2","q17":"36.2","q2":"\u5929\u6D25","q10_show":"\u5929\u6D25\u5E02/\u5929\u6D25\u5E02/\u6EE8\u6D77\u65B0\u533A","q10":"120000/120000/120116","q9":"\u5BBF\u820D","q4":"N","q5":"N","q20":"N","q11":"N","q12":"N","q13":"green","q18":"2","q19":"2","q8":""}',
'status': '1'
}
requests.post('https://jkcj.nankai.edu.cn/healthgather/Inschool/addInschoolGather', headers=headers,
params=params, data=data)
print('School temperature send !')
def Send(uName, pWord):
cookie = getCookie(uName, pWord)
post(cookie)
print()
if __name__ == '__main__':
Send('1712***', 'password')
运行一下成功了

然后我们要把代码放在服务器上
vim index.py然后开启输入模式,把代码传进去。注意一次只能穿2000个字符,所以要一部分一部分的传。你也可以直接用文件传输服务穿过去。但是我就是喜欢看代码一行一行从屏幕里冒出来的样子

服务器上也发送成功了。那我们就可以设置定时任务了。
编辑定时任务,还是vim编辑器
crontab -e在里面加一个任务
从左到右依次表示分、时、日、月、周
这段代码的意思是在 5分0时任何日月周,执行python3 /root/index.py这个指令
翻译成人话就是,每天凌晨0点05运行代码。
5 0 * * * python3 /root/index.py当然你也可以写成别的 比如 0 1 * * * 就是每天1:00,0 5 * * 1 就是每周一的00:05执行
至此大功告成。
此事告一段落。
其他:
不会真的有人看到这里吧?
不会吧?
不会吧?
那既然你花时间看到这里了,咱们就是好兄弟。如果你也想和我一样,享受云服务器带来的便捷,那你其实完全没必要按我说的从头开始钻研,搭建环境。请直接联系我。只要信得过我,对我来说就是加一行代码的事儿而已。
最后用两句自嘲里的诗给自己结尾吧:
“醉舞经阁半卷书,坐井说天阔。”
“论到囊中羞涩时,怒指乾坤错。”