背景
我们目的是将样本分成k个类,其实说白了就是求每个样例x的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎么评价假定的好不好呢?我们使用样本的极大似然估计来度量,这里是就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
使用
聚类的目标:
- 高内聚(类内距离加和尽可能小!)
- 量化指标:wcss(组内平方和,WCSS within-cluster sum of squares)
- 寻找k个聚类中心,使得数据到聚类中心的距离最小
- 低耦合(类与类之间的距离越大越好)!
- 将每个数据点分配到距离最近的聚类中心
步骤
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下
- 初始化:对每个cluster,任意选择空间中的一个点作为cluster中心
- 迭代直到收敛:
- 分配:将每一个数据点分配到距离最近的中心
- 重调:根据新的分配重新计算聚类中心
复杂度:n*k*t
优点:快
缺点:
- 对初试聚类中心依赖性强,最终效果随机性强
- K值很难明确
- 因此常用于预处理的去重操作
- 同类别的商品基本上相似
- 不能发现非凸形状的簇
- 异或数据无法区分
- 结果很难保证全局最优,只是局部最优
分析
K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数distortion function如下:
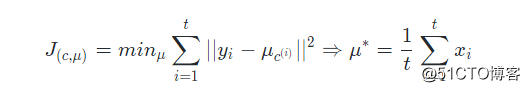
J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心μ,调整每个样例的所属的类别c^(i)^来让J函数减少,同样,固定c^(i)^,调整每个类的质心μ也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,μ和c也同时收敛。(在理论上,可以有多组不同的μ和c值能够使得J取得最小值,但这种现象实际上很少见)。
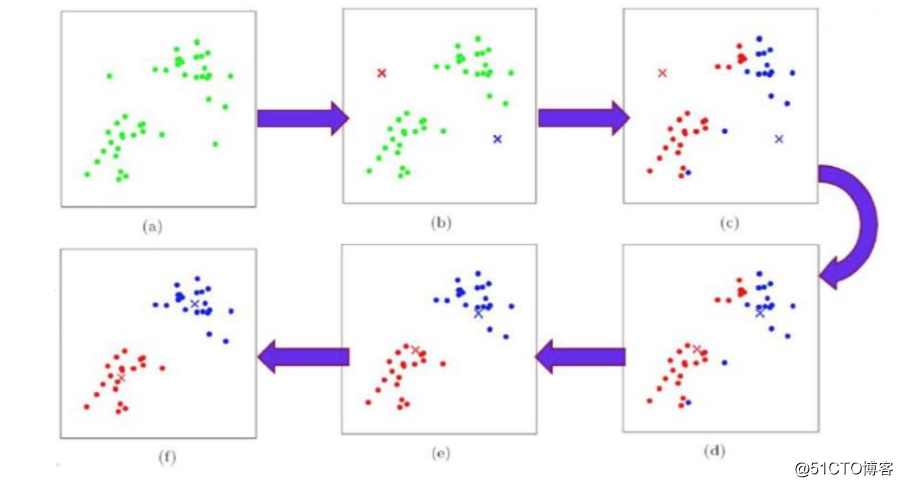
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的μ和c输出。
实现代码
def ReAssignClass():
did = 0
totalDis = 0.0 # 所有的距离
for doc in DocList:
min = ComputeDis(doc, ClassCenterList[0])
minIndex = 0
for i in range(1, K):
dis = ComputeDis(doc, ClassCenterList[i])
if dis < min:
min = dis
minIndex = i
ClassList[did] = minIndex
did += 1
totalDis += min
return totalDis注意到,K是我们事先给定的聚类数,ComputeDis将会计算出样例i与k个类中距离最近的那个类,其的值是1到k中的一个。质心代表我们对属于同一个类的样本中心点的猜测(即μ,其实也就是我们随机初始化一个点),如若拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团记为min,这样经过第一步每一个星星都有了所属的星团。
def ComputeDis(doc1, doc2):
sum = 0.0
for (wid, freq) in doc1.items():
if wid in doc2:
d = freq - doc2[wid]
sum += d * d
else:
sum += freq * freq
for (wid, freq) in doc2.items():
if wid not in doc1:
sum += freq * freq
sum = math.sqrt(sum)
return sum第二步对于每一个星团,重新计算它的质心ReComputeCentroids(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
def ReComputeCentroids():
for i in range(K):
ClassSizeList[i] = 0
ClassCenterList[i] = {}
for i in range(len(DocList)):
classid = ClassList[i]
ClassSizeList[classid] += 1
AddDoc(ClassCenterList[classid], DocList[i])
for i in range(K):
ClassCenterList[i] = Average(i)实践
基于Kmeans的文章聚类(把相同的文章聚合)
准备数据
1000份已经打好标签的文本,并且由标签分类如bussiness,it,yule...
抽取其中一份内容已经经过文本预处理,每个词汇通过 分隔开

数据预处理之后通过idf为这些词打分
def AddIDF(DocList):
wordDic = {}
for doc in DocList:
for word in doc.keys():
if word in wordDic:
wordDic[word] += 1
else:
wordDic[word] = 1
N = len(DocList)
for doc in DocList:
for word in doc.keys():
doc[word] *= math.log(N + 1 / (float)(wordDic[word]))
Normalize(doc)Kmeans分析
初始化K个类中心,也就是Kmeans的核心节点
def Init():
templist = random.sample(DocList, K)
for i in range(K):
ClassSizeList.append(0)
ClassCenterList.append(templist[i])
计算各个点到(类)中心的距离,当然了,这个距离是尽可能的越小越好,输出的结果就是wcss,其计算方式如下:
def ComputeDis(doc1, doc2):
sum = 0.0
for (wid, freq) in doc1.items():
if wid in doc2:
d = freq - doc2[wid]
sum += d * d
else:
sum += freq * freq
for (wid, freq) in doc2.items():
if wid not in doc1:
sum += freq * freq
sum = math.sqrt(sum)
return sum本质上就是计算同一个簇内的距离的平方和后开方,
while math.fabs(oldWCSS - WCSS) > Threshold:
oldWCSS = WCSS
print "Iteration", i, "WCSS:", WCSS
ReComputeCentroids()
WCSS = ReAssignClass()
i += 1
ReComputeCentroids()
print "Final iteration WCSS:", WCSS重复迭代计算,直到wcss是最小,我用oldWCSS - WCSS做差,而threshold我自定义为1,当然了可以更加精确的,比如0.0001??
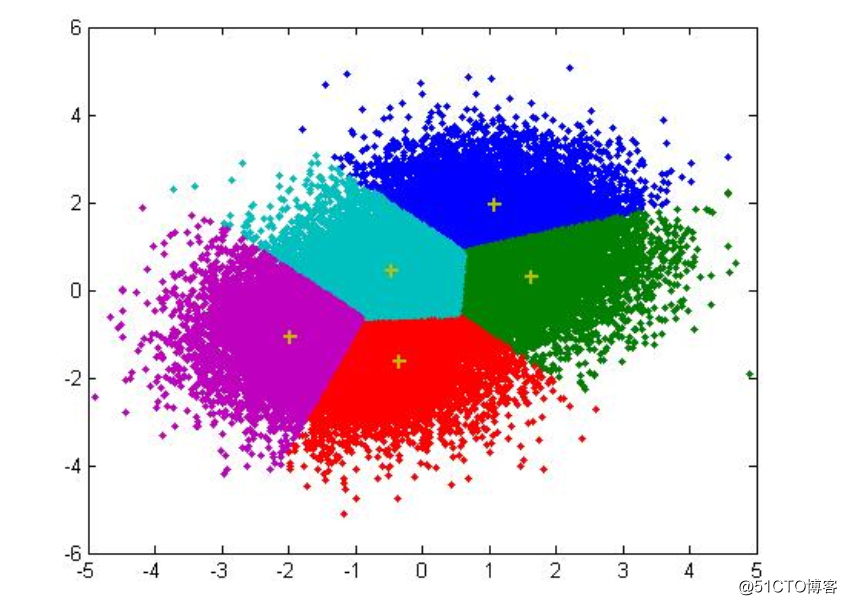
运行结果如图所示
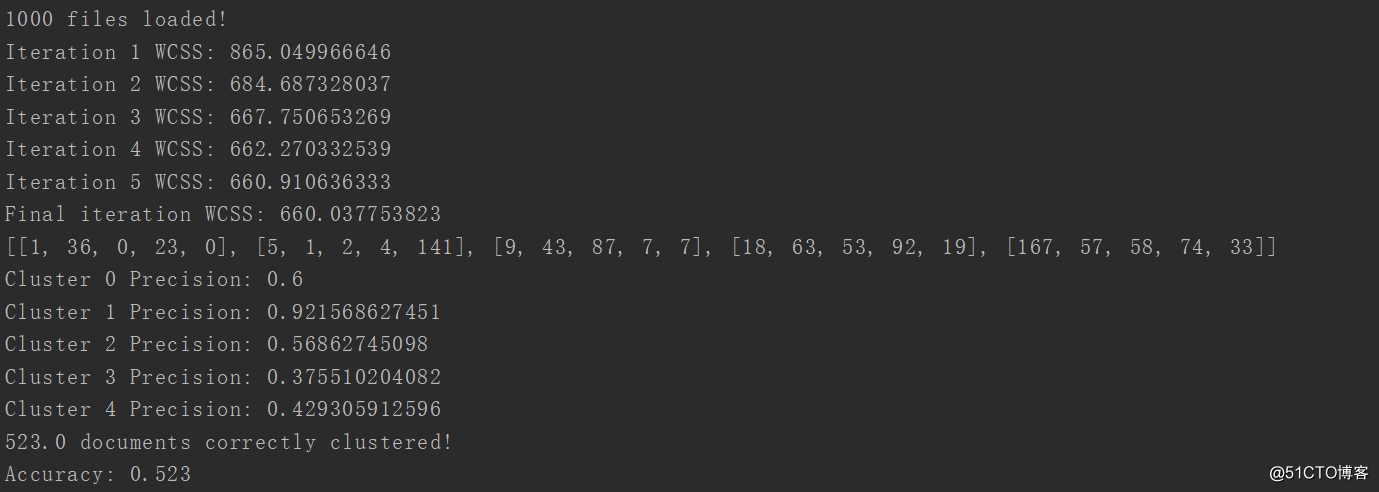
有5种分类方式,其中第一种的分类方式准确率是0.6,第二种是0.9,。。。。。。