使用Stream已经快3年了,但是从未真正深入研究过Stream的底层实现。
今天开始把最近学到的Stream原理记录一下。
本篇文章简单描述一下自己对pipeline的理解。
基于下面一段代码:
public static void main(String[] args) {
List<String> list = Arrays.asList("123", "123123");
list.stream().map(item -> item+"").forEach(System.out::print);
}
1. stream()方法
显然,这里的list对象是一个ArrayList实例,debug代码进入stream方法,可以看见进入到Collection.java类中的stream()中

这里的源码如下:
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
关于分割迭代器的内容会在另外一篇文章详解,这里不再赘述。
进入StreamSupport.stream()方法:
StreamSupport.java
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
咱们可以看到Stream是一个ReferencePipeline.Head类的实例,
通过idea的类图结构功能,我们可以看到下面这个层次结构:
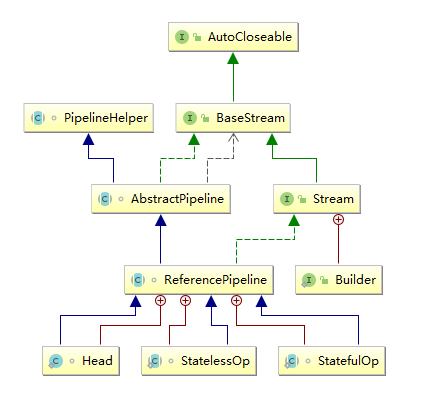
所有的流基本都是来自于BaseStream,AbstractPipeline,ReferencePipeline这三个抽象类或接口。
ReferencePipeline的实现类一共就三种:
- Head
- StatelessOp
- StatefulOp
查看了源码即可知道:AbstractPipeline其实就是一个双向链表中的一个节点。【我是这么理解的】
Head:代表的是流的源头,刚构建的时候流的一些属性被包含在这个对象。比如这个集合的元素,毕竟流的存在还是为了对一组元素的操作。
StatelessOp:代表的是无状态的操作,如map()
StatefulOp:代表的是有状态的操作,如sorted()
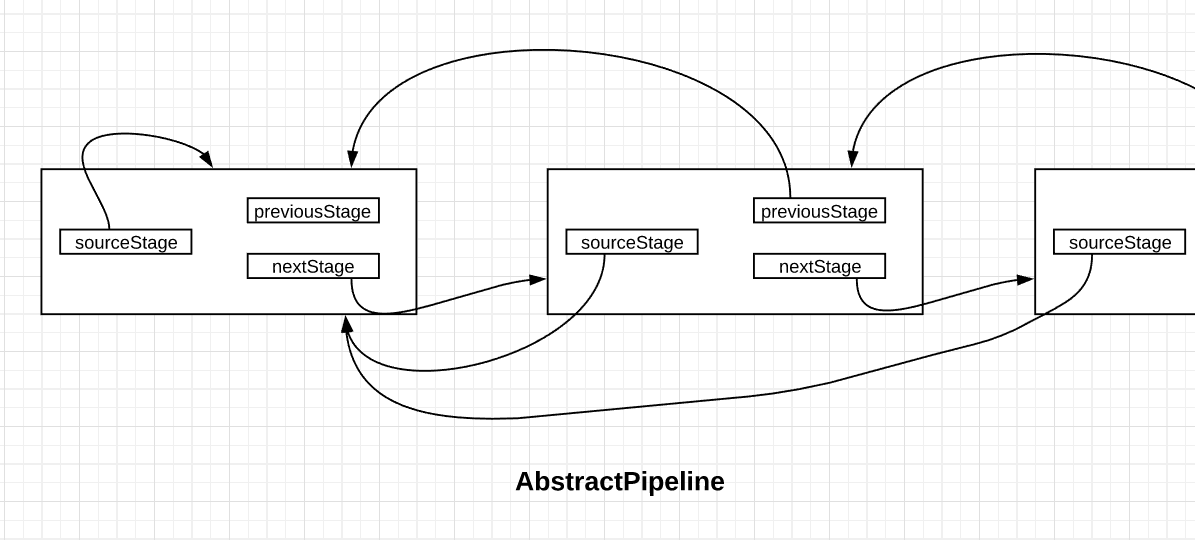
图中的每个节点都是一个AbstractPipeline的实现。
所以stream()方法执行之后,拿到的是一个ReferencePipeline.Head实例,并没有构建StatelessOp,StatefulOp实例。
2. map()方法
因为stream方法返回值是一个Head实例,而Head类并未重写map方法,所以map方法的实际执行还是走的ReferencePipeline类的map方法,如下:
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
这里的返回是一个继承于StatelessOp的匿名类。
关于Sink和TerminalOp的详解后续会单独开文章分析。
这里只需要理解这个map的返回值是一个继承于StatelessOp的匿名类。(StatelessOp是一个ReferencePipeline的实现)
3. forEach()方法
前提:流是含有流源的对象,并且它支持0个或多个中间操作,1个终止操作的特性。
通过idea查看发现foreach的实现有2个:

第一个是Head的实现,因为流源构造出来之后,直接调用forEach,有它自己的实现,对迭代做了优化。这里可后续添加细致分析。
第二个是ReferencePipeline的实现,即调用终止操作的节点不是流源节点。
我们这里只分析ReferencePipeline中的实现:
public void forEach(Consumer<? super P_OUT> action) {
/**
* ForEachOps.makeRef(action, false) 是构建终止操作,参考3.1
* evaluate()是触发终止操作的调用,参考3.2
*/
evaluate(ForEachOps.makeRef(action, false));
}
这里的evaluate方法可以想象成“执行”的意思。
ForEachOps.makeRef(action, false)方法可以想象成“构造一个终止操作”。--终止操作是一个名词,这里只是一个对象而已,如果这个“操作”没有得到触发,那么流什么也不会干。
所以这个evaluate可以理解成fire action performed.
3.1 构建终止操作
首先来看看TerminalOp接口,这是所有终止操作的抽象,每一个终止操作都是它的子类。
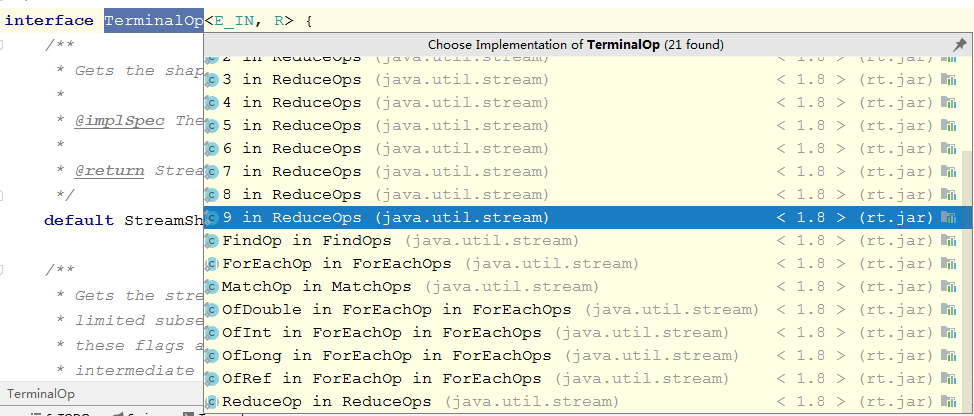
查看它的实现类,可以发现它的实现类的特点:
- FindOp in FindOps
示例:findFirst() - ReduceOp in ReduceOps
示例:reduce(BigDecimal.Zero, BigDecimal::add) - ForEachOp in ForEachOps
示例:forEach() - MatchOp in MatchOps
示例:anyMatch()
其中带s的是一个工厂类,用于生产不同的“终止操作”。
不带s的才是一个“终止操作”TerminalOp的实现类。
3.2 触发终止操作
其实这里也不是仅仅触发终止操作,这个方法里会把前面所有的中间操作apply到每一个元素上,并执行终止操作。
evaluate()的实现如下,暂时这里不做过多讨论,后续在sink的单独一篇文章中,分析具体流的执行过程。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
总结
本文只是为了理解:流pipeline是一个什么概念,以及它有什么样的基本特性?
1、流pipeline是一个双向链表的节点,前后引用。
2、流由流源,中间操作和终止操作组成。
3、终止操作被触发的时候,所有的操作(中间+终止)才会被一一应用到元素上。这称为流的惰性。
4、有一些操作是具有短路的特性的,如:findFirst等。