高并发系统设计的三大目标:高性能、高可用、可扩展
高性能:反应了系统的使用体验,想象一下,同样承担每秒一万次请求的两个系统,一个响应时间是毫秒级,一个响应时间在秒级别,它们带给用户的体验肯定是不同的。
高可用:则表示系统可以正常服务用户的时间。举例,还是两个承担每秒一万次的系统,一个可以做到全年不停机、无故障,一个隔三差五宕机维护,哪个算是高可用?
可扩展:流量分为平时流量和峰值流量两种,峰值流量可能会是平时流量的几倍甚至几十倍,在应对峰值流量的时候,我们通常需要在架构和方案上做更多的准备。而易于扩展的系统能在短时间内迅速完成扩容,更加平稳地承担峰值流量。
性能优化原则
“天下武功,唯快不破”。性能是系统设计成功与否的关键,实现高性能也是对程序员个人能力的挑战。不过在了解实现高性能的方法之前,我们先明确一下性能优化的原则。
- 首先,性能优化一定不能盲目,一定是问题导向的。脱离了问题,盲目地提早优化会增加系统的复杂度,浪费开发人员的时间,也因为某些优化可能会对业务上有些折中的考虑,所以也会损伤业务。
- 其次,性能优化也遵循“八二原则”,即你可以用20%的精力解决80%的性能问题。所以我们在优化过程中一定要抓住主要矛盾,优先优化主要的性能瓶颈点。
- 再次,性能优化也要有数据支撑。在优化过程中,你要时刻了解你的优化让响应时间减少了多少,提升了多少的吞吐量。
- 最后,性能优化的过程是持续的。高并发的系统通常是业务逻辑相对复杂的系统,那么在这类系统中出现的性能问题通常也会有多方面的原因。因此,我们在做性能优化的时候要明确目标,比方说,支撑每秒1万次请求的吞吐量下响应时间在10ms,那么我们就需要持续不断地寻找性能瓶颈,制定优化方案,直到达到目标为止。
性能的度量指标
性能优化的第三点原则中提到,对于性能我们需要有度量的标准,有了数据才能明确目前存在的性能问题,也能够用数据来评估性能优化的效果。所以明确性能的度量指标十分重要。
一般来说,度量性能的指标是系统接口的响应时间,但是单次的响应时间是没有意义的,你需要知道一段时间的性能情况是什么样的。所以,我们需要收集这段时间的响应时间数据,然后依据一些统计方法计算出特征值,这些特征值就能够代表这段时间的性能情况。我们常见的特征值有以下几类。
- 平均值
顾名思义,平均值是把这段时间所有请求的响应时间数据相加,再除以总请求数。平均值可以在一定程度上反应这段时间的性能,但它敏感度比较差,如果这段时间有少量慢请求时,在平均值上并不能如实的反应。
举个例子,假设我们在30s内有10000次请求,每次请求的响应时间都是1ms,那么这段时间响应时间平均值也是1ms。这时,当其中100次请求的响应时间变成了100ms,那么整体的响应时间是(100 * 100 + 9900 * 1) / 10000 = 1.99ms。你看,虽然从平均值上来看仅仅增加了不到1ms,但是实际情况是有1%的请求(100/10000)的响应时间已经增加了100倍。所以,平均值对于度量性能来说只能作为一个参考。
- 最大值
这个更好理解,就是这段时间内所有请求响应时间最长的值,但它的问题又在于过于敏感了。
还拿上面的例子来说,如果10000次请求中只有一次请求的响应时间达到100ms,那么这段时间请求的响应耗时的最大值就是100ms,性能损耗为原先的百分之一,这种说法明显是不准确的。
- 分位值
分位值有很多种,比如90分位、95分位、75分位。以90分位为例,我们把这段时间请求的响应时间从小到大排序,假如一共有100个请求,那么排在第90位的响应时间就是90分位值。分位值排除了偶发极慢请求对于数据的影响,能够很好地反应这段时间的性能情况,分位值越大,对于慢请求的影响就越敏感。
分位值是最适合作为时间段内,响应时间统计值来使用的,在实际工作中也应用最多。除此之外,平均值也可以作为一个参考值来使用。
我们通常使用吞吐量或者同时在线用户数来度量并发和流量,使用吞吐量的情况会更多一些。但是你要知道,这两个指标是呈倒数关系的。
这很好理解,响应时间1s时,吞吐量是每秒1次,响应时间缩短到10ms,那么吞吐量就上升到每秒100次。所以,一般我们度量性能时都会同时兼顾吞吐量和响应时间,比如我们设立性能优化的目标时通常会这样表述:在每秒1万次的请求量下,响应时间99分位值在10ms以下。
那么,响应时间究竟控制在多长时间比较合适呢?这个不能一概而论。
从用户使用体验的角度来看,200ms是第一个分界点:接口的响应时间在200ms之内,用户是感觉不到延迟的,就像是瞬时发生的一样。而1s是另外一个分界点:接口的响应时间在1s之内时,虽然用户可以感受到一些延迟,但却是可以接受的,超过1s之后用户就会有明显等待的感觉,等待时间越长,用户的使用体验就越差。所以,健康系统的99分位值的响应时间通常需要控制在200ms之内,而不超过1s的请求占比要在99.99%以上。
现在你了解了性能的度量指标,那我们再来看一看,随着并发的增长我们实现高性能的思路是怎样的。
高并发下的性能优化
假如说,你现在有一个系统,这个系统中处理核心只有一个,执行的任务的响应时间都在10ms,它的吞吐量是在每秒100次。那么我们如何来优化性能从而提高系统的并发能力呢?主要有两种思路:一种是提高系统的处理核心数,另一种是减少单次任务的响应时间。
1.提高系统的处理核心数
提高系统的处理核心数就是增加系统的并行处理能力,这个思路是优化性能最简单的途径。拿上一个例子来说,你可以把系统的处理核心数增加为两个,并且增加一个进程,让这两个进程跑在不同的核心上。这样从理论上,你系统的吞吐量可以增加一倍。当然了,在这种情况下,吞吐量和响应时间就不是倒数关系了,而是:吞吐量=并发进程数/响应时间。
是不是无限制地增加处理核心数就能无限制地提升性能,从而提升系统处理高并发的能力呢?但随着并发进程数的增加,并行的任务对于系统资源的争抢也会愈发严重。在某一个临界点上继续增加并发进程数,反而会造成系统性能的下降,这就是性能测试中的拐点模型。
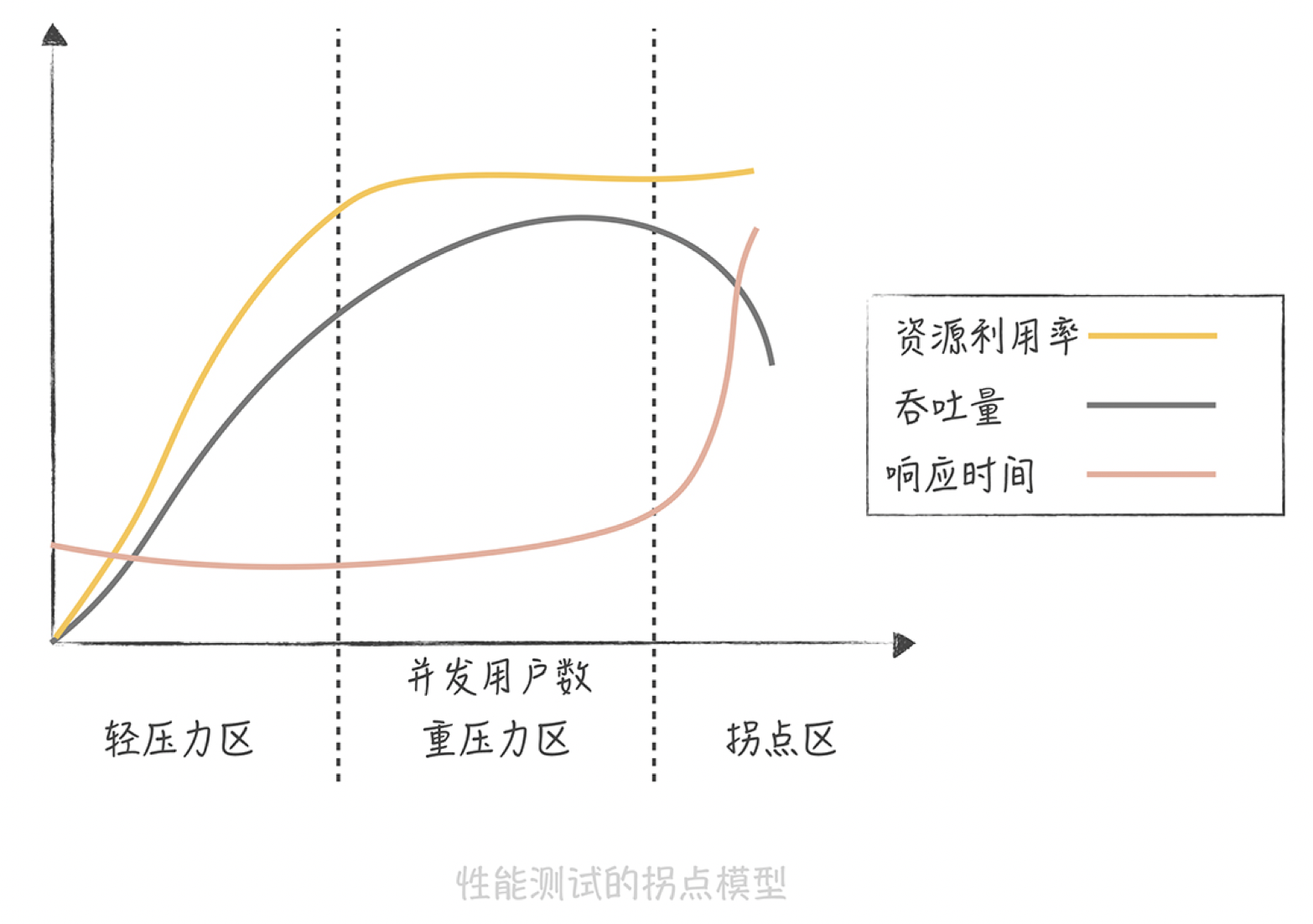
所以我们在评估系统性能时通常需要做压力测试,目的就是找到系统的“拐点”,从而知道系统的承载能力,也便于找到系统的瓶颈,持续优化系统性能。
2.减少单次任务响应时间
想要减少任务的响应时间,首先要看你的系统是CPU密集型还是IO密集型的,因为不同类型的系统性能优化方式不尽相同。
CPU密集型系统中,需要处理大量的CPU运算,那么选用更高效的算法或者减少运算次数就是这类系统重要的优化手段。比方说,如果系统的主要任务是计算Hash值,那么这时选用更高性能的Hash算法就可以大大提升系统的性能。发现这类问题的主要方式,是通过一些Profile工具来找到消耗CPU时间最多的方法或者模块,比如Linux的perf、eBPF等。
IO密集型系统指的是系统的大部分操作是在等待IO完成,这里IO指的是磁盘IO和网络IO。我们熟知的系统大部分都属于IO密集型,比如数据库系统、缓存系统、Web系统。这类系统的性能瓶颈可能出在系统内部,也可能是依赖的其他系统,而发现这类性能瓶颈的手段主要有两类。
第一类是采用工具,Linux的工具集很丰富,完全可以满足你的优化需要,比如网络协议栈、网卡、磁盘、文件系统、内存,等等。这些工具的用法很多,你可以在排查问题的过程中逐渐积累。除此之外呢,一些开发语言还有针对语言特性的分析工具,比如说Java语言就有其专属的内存分析工具。
另外一类手段就是可以通过监控来发现性能问题。在监控中我们可以对任务的每一个步骤做分时的统计,从而找到任务的哪一步消耗了更多的时间。
那么找到了系统的瓶颈点,我们要如何优化呢?优化方案会随着问题的不同而不同。比方说,如果是数据库访问慢,那么就要看是不是有锁表的情况、是不是有全表扫描、索引加得是否合适、是否有JOIN操作、需不需要加缓存,等等;如果是网络的问题,就要看网络的参数是否有优化的空间,抓包来看是否有大量的超时重传,网卡是否有大量丢包等。
有时候你在遇到性能问题的时候会束手无策,注意点:
- 数据优先,你做一个新的系统在上线之前一定要把性能监控系统做好;
- 掌握一些性能优化工具和方法,这就需要在工作中不断的积累;
- 计算机基础知识很重要,比如说网络知识、操作系统知识等等,掌握了基础知识才能让你在优化过程中抓住性能问题的关键。
参考
1.业务价值->承载高并发->性能优化。一切的前提是业务价值需要。如果没有足够的价值,那么可读性才是第一,性能在需要的地方是no.1,但不需要的地方可能就是倒数第一稞。当下技术框架出来的软件差不到哪去,没有这种及时响应诉求的地方,削峰下慢慢跑就是了。(工作需要,常在缺少价值的地方着手性能优化,让我对这种就为个数字的操作很反感。要知道,异步,并发编程,逻辑缓存,算法真的会加剧系统的复杂度,得不偿失。如果没那个价值,简单才是王道)
2.提高并发度。要么加硬件,要么降低服务响应时间。做为开发,我们的目光更聚焦在降低响应时间这块。
1.采用非阻塞的rpc调用(高效的远端请求模式,采用容器的覆盖网络我认为也算)
2.将计算密集和io密集的的逻辑分割开,单独线程池,调整线程比例压榨单机性能(或者说找拐点)。
3.做缓存,io耗时的缓存和计算耗时的缓存(多级缓存,数据压缩降低带宽)。
4.采用享元模式,用好对象池和本地线程空间,尽量减少对象创建与销毁的开销,提高复用。
5.业务拆分,像状态变化后的外部系统通知,业务监控,es或solr等副本数据同步等操作,无需在主流程中做的事都拆掉。走canal监听表数据变化,推mq保最终一致的方式从业务项目完全解偶出来。
6.fork_join,分而治之的处理大任务。并发编程,采用多线程并行的方式处理业务。(规避伪共享,减小锁力度,采用合适的锁)。
7.数据库配置优化,查询优化。(存储优化比较头疼,毕竟不按业务拆单点跑不掉,单点性能就要命。基本只能内存库先行,后台同步数据做持久。然后内存库多副本,自修复,保留一系列自修复失败的修复手段)