3."类"代码语法细节
新式类
问题引入:
>>>class Apple:
... pass
>>>apple=Apple()
>>>isinstance(apple,Apple)
True
class Person(object):
def _init_(self,name,job,pay):
self.name=name
self.job=job
self.pay=pay
定义类时有时用一个空的括号(),有时给括号里写一个 (object),有的时候不用括号。这有什么区别?
自Python 2.2以来引入了一种新的类,称之为"新式类"(new-style),而与之相对应的,旧的称之为"经典类"(classic)
python3
所有的类都继承自object,不管是显示地还是隐式地
>>>class Myclass(object): #new-style class
... pass
...
>>>class Myclass: #new-style class(implicity inherits from object)
... pass
>>>
Python 2
类必须继承自object才是"新式类"
>>>class Myclass(object): #new-style class
... pass
...
>>>class Myclass: #old-style class
... pass
>>>
因此好习惯是每次遇到这种情况都写上继承自object
静态方法
上一节课我们已经熟悉了实例方法(instance method)。实例方法在其第一个参数self中传递一个实例对象,以充当方法调用的一个隐式主体
有的时候程序需要处理与类相关而不是与实例相关的数据,例如要记录一个由类创建的实例的个数。这种类型的信息及其处理与类相关而而不需要依附于某个实例对象。
针对这种需求Python引入了静态方法(static method):嵌套在类中的没有self参数的函数,旨在操作类属性(class attribute)而不是实例属性(instance attribute)。它不传递也不期待一个self实例参数
引例:
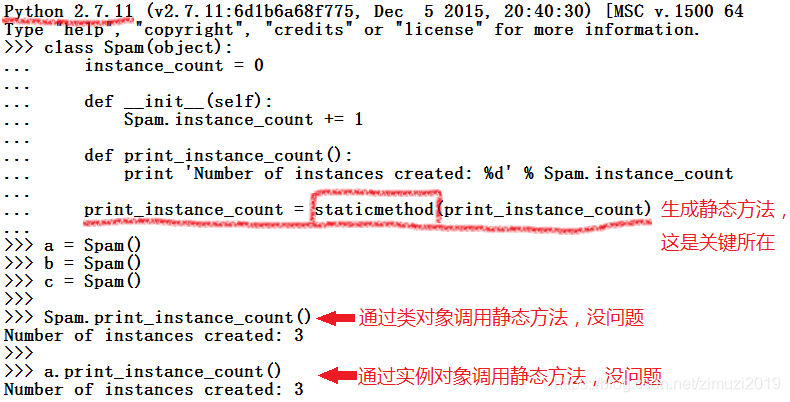
python2
>>>class Spam(object):
... instance_count=0
...
... def _init_(self):
... Spam.instance_count+=1
...
... def print_instance_count(): #尝试定义一个不期待实例对象self参数的方法
... print'Number of instances created:%d' %Spam.instance_count
>>>a=Spam()
>>>b=Spam()
>>>c=Spam()
>>>
>>>Spam.print_instance_count() #尝试通过类对象调用这个方法,会失败
>>>a.print_instance_count() #尝试通过实例对象调用这个方法,同样失败
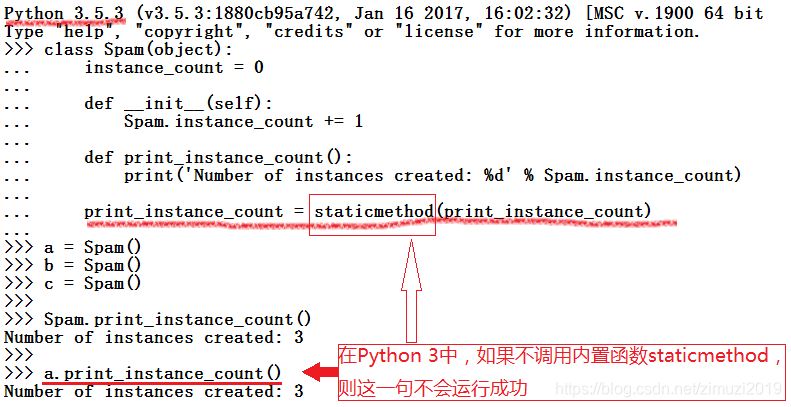
python3
>>>class Spam(object):
... instance_count=0
...
... def _init_(self):
... Spam.instance_count+=1
...
... def print_instance_count(): #尝试定义一个不期待实例对象self参数的方法
... print('Number of instances created:%d' %Spam.instance_count)
>>>a=Spam()
>>>b=Spam()
>>>c=Spam()
>>>
>>>Spam.print_instance_count() #尝试通过类对象调用这个方法,这次能够成功
>>>a.print_instance_count()
#尝试通过实例对象调用这个方法,同样失败。这很正常,因为实例对象被传递给这个方法,这个方法却没有参数来接收这个实例对象
在python中真正定义一个方法需要用到内置函数staticmethod。使用该内置函数就能得到一个静态方法,这样该方法就能通过类对象和实例对象调用
staticmethod
在引例代码中加入如下一行代码来生成静态方法
print_instance_count=staticmethod(print_instance_count)
使用后效果如下
静态方法的特点
1.完全不期待一个self参数
2.内部使用的是类属性而不是实例属性(如使用类名Spam.instance_count而不是self.instance_count)
3.静态方法最规范的调用是用类调用(类名.方法名()),因为它只从属于类,和任何实例对象没有关系。当然通过实例对象调用也不会出错
静态方法可以被继承并在子类中重载
观察以下示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d7qL8Oq9-1591677885204)(C:\Users\24190\AppData\Roaming\Typora\typora-user-images\image-20200525204521036.png)]](https://img-blog.csdnimg.cn/20200609124634180.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3ppbXV6aTIwMTk=,size_16,color_FFFFFF,t_70)
示例说明:
Sub子类重载了父类的静态方法,Sub的print_instance_count()显式地调用了父类的print_instance_count()。二者的区别就是多了个print语句
测试代码块中第一个Spam.print_instance_count()执行时还没有创建任何实例对象,这时候就已经可以利用类对象的静态方法来得知实例的数量,这不用静态方法的通过类调用是很难做到的
从结果看出由Spam的子类创建的实例也一样算在Spam底下,因为它的子类Sub完全直接继承了Spam的构造函数且没有重载过
类方法
传递给类方法的第一个参数是一个类对象,需要使用内置函数 classmethod 来生成
下面使用类方法而不是静态方法实现对实例对象个数的统计。注意通过类调用和实例对象调用都可以调用类方法
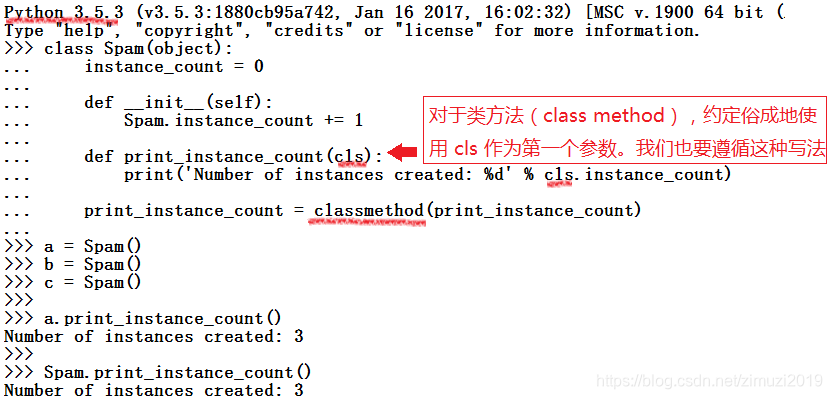
def print_instance_count(cls)
print('Number of instances created:%d'%cls.instance_count)
#括号内是一个名为cls的形参,而且你在写类方法的时候也一定要去使用这个形参,它是class的缩写。该例与静态方法的例子相比不再使用Spam类名,而是使用cls来代指将来会传进来的类对象
三种类中定义的,与类相关的方法总结(必考)
实例方法:期待一个实例对象作为第一个参数。我们把这个参数写作self。通过实例对象调用实例方法时Python会把实例对象自动传递给第一个参数。通过类调用则时需要手动传入实例
静态方法:不期待参数,调用时也不需要实例对象作为参数。通常都是通过类对象来调用
类方法:期待一个类对象作为第一个参数。我们把这个参数写作cls
装饰器
可以把下面这种笨拙的写法改一改
def print_instance_count():
print('Number of instances created:%d'%Spam.instance_count)
print_instance_coun=staticmethod(print_instance_count)
换成这种形式,两种方式是等价的
@staticmethod #直接在要定义的静态方法前加@staticmethod于方法头部
def print_instance_count():
print('Number of instances created:%d'%Spam.instance_count)
super()
super()在类重载的时候指代父类的名字。凡是需要提及父类的对象的时候都不需要把父类名字写出来,而是直接使用super()代替,super()在多重继承的时候会更常用。
注:考试不考多重继承,只会考单重继承
以上一节的代码为例子,改动后不需要去写Person这个父类名,而是用super()内置函数加以替换
class Person(object):
def __init__(self,name,job=None,pay=0):
self.name=name
self.job=job
self.pay=pay
def last_name(self):
return self.name.split()[-1]
def give_raise(self,percent):
self.pay=int(self.pay*(1+percent))
def __str__(self):
return '[Person: %s,%s]' % (self.name,self.pay)
class Manager(Person):
def __init__(self,name,pay):
#person.__init__(self,name,'mgr',pay)
super().__init__(self,name,'mgr',pay)
def give_raise(self,percent,bonus=0.1):
#person.give_raise(self,pecent+bonus)
super().give_raise(self,pecent+bonus)
super()函数在python2和3的区别就不记了,自己见课件
类的伪私有属性
类的伪私有属性用来变相控制变量名的访问范围。python没有C++的public等关键字来严格控制变量的访问范围,因此python只能给你造成一些麻烦,在让你尝试访问本不该访问的变量名或者属性名时遇到错误,通过让你做的不够顺畅来提醒你不该这么做。
python支持所谓的变量名压缩(name mangling),让类内部特定的变量局部化,从而难以由类外部访问。但是变量名压缩并不能阻止通过类外部的代码对其读取。
何为变量名压缩?
class语句内,开头有两个下划线但结尾没有两个下划线的变量名会自动扩展,从而包含它所在类的名称。例如Spam类内 __ x 这样的变量名会自动变成 _ Spam __x。变量名压缩只发生在class语句内,而且只针对开头有两个下划线的变量名
示例:
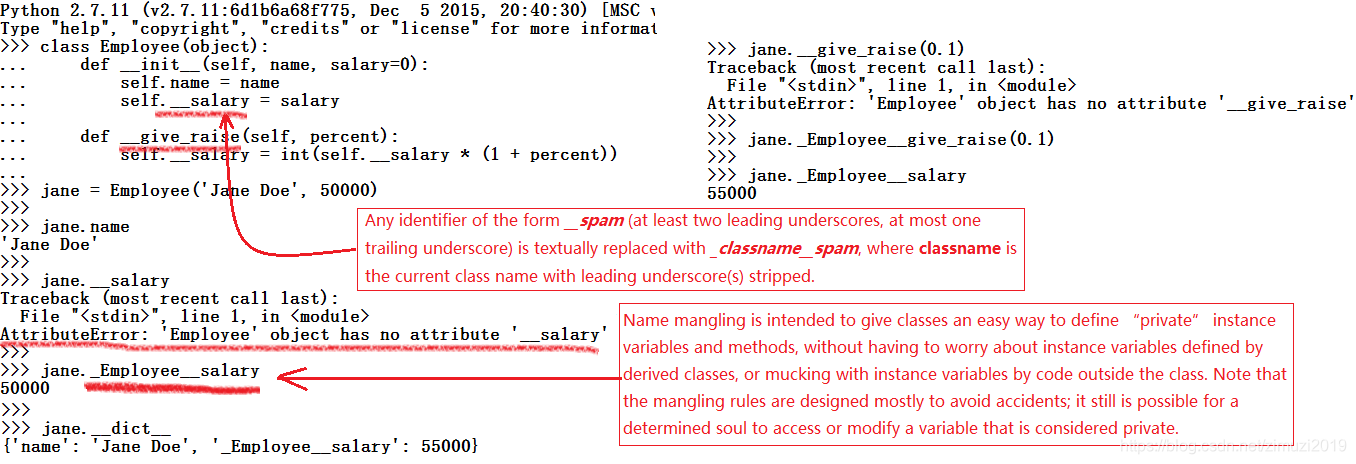
这种情况下如果还是用两个下划线的形式尝试去访问 __ salary 就会报错提示你没有这个东西,这种报错就是一种变相的提示,因为实际的真正名字已经发生了改变,这就是变量名压缩。从外部没有办法直接访问到 __ x,除非你知道变量名压缩的规则手动加上类名用 _Employee __x的形式才能进行访问。这就实现了伪私有属性
这个技巧可以避免实例中潜在的变量名冲突(考试不考,课件上的例子自己看)
python中的下划线和变量名
1.变量名前面加一条下划线
当import的时候,前面加单一下划线的东西不会被导入,这实际上是一种内部使用
2.变量名后面加一条下划线
避免和python保留字的冲突
如Tlinter.Toplevel(master,class_=‘ClassName’)
Tlinter这个package里有一个方法Toplevel,它想用一个名为class的参数就在后面加一条单一的下划线表示这是一个普通的变量名来避免与class保留字发生冲突
3.变量名前面加两个下划线
变量名压缩
4.变量名前后各加两个下划线
python内置的变量名和方法
4.面向对象程序设计思想
除了继承(inheritance),多态(Polymorphism),封装(Encapsulation)这几个OOP的重要概念外,我们还要介绍一些OOP概念
IS-A relationship vs. HAS-A relationship
这个概念关系着你该如何利用组合和继承之间的相互配合来对问题进行建模,它意味着类之间的单向的继承关系(通过IS-A relationship表达,)和类生成的实例之间的组合关系(通过HAS-A relationship表达)。下面这幅图就表现这两种关系的区别和联系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CEFgsKtS-1591677885211)(C:\Users\24190\AppData\Roaming\Typora\typora-user-images\image-20200526091958634.png)]](https://img-blog.csdnimg.cn/2020060912485363.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3ppbXV6aTIwMTk=,size_16,color_FFFFFF,t_70)
下面给一个实际的例子进行展示,假设我们要开个烧饼店。首先定义厨师,服务员,会做烧饼的机器人。要先通过继承实现IS-A relationship。先定义一个基类Employee,生成它的子类Chef,Server,对Chef又生成子类PizzaRobot
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-URXDf0Bf-1591677885212)(C:\Users\24190\AppData\Roaming\Typora\typora-user-images\image-20200526092234389.png)]
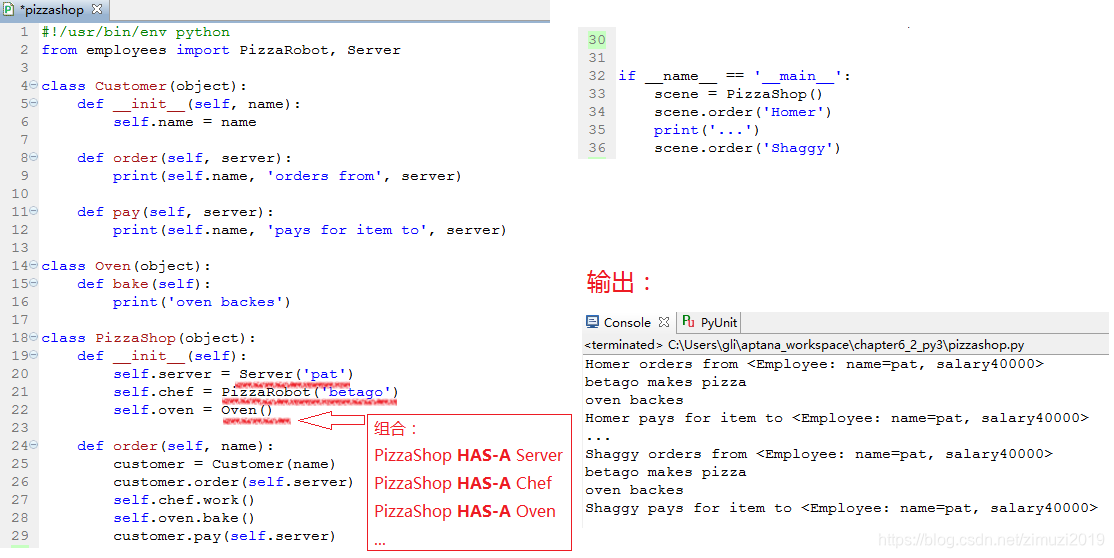
把厨师,服务员和会做烧饼的机器人放到店里去工作。这里用到了"组合",即 HAS-A relationship。第一行从刚刚已经定义好的类里面导入PizzaRobot和Server,再定义两个类Customer和Oven。最关键的PizzaShop类,它的构造函数就用到了组合,由以前已经定义好的类生成多个实例对象,同时这些实例对象最后实际上都成为了PizzaShop的实例属性。
抽象超类
先看下面这个例子,注意Provider类的实例对象x如何运作
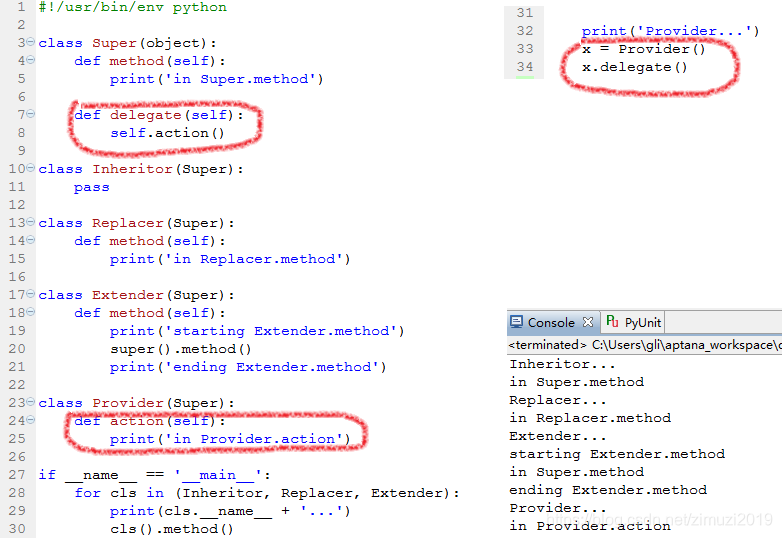
注意Super类在delegate函数体(方法体)调用了名为action的实例方法,但是Super类里面找不到action的定义。Super又派生出子类Replace,extender,Provider,Inheritor。Replace和Provider重载了method方法,后者与前者的区别在于在method方法里还调用了父类的method方法。Proivder同样是继承Super,但是它在内部定义了Super自己没有定义的action方法
对类的定义完了之后再去使用它。对这部分测试代码的讲解如下
if __name__=='_main_':
for cls in (Inheritor,Replacer,Extender):
#cls是类对象。Inheritor后面没有括号,这意味着直接使用类对象而没有调用Inheritor的构造函数
print(cls._name_+'...')
#python提前定义好了一些变量用于获得某些变量的类型信息,其中就有_name_。
cls().method()
#cls()的写法实际上是调用了类对象的构造函数,调用类对象构造函数之后实际上获得了一个实例对象。然后再通过这个实例对象调用method方法
print("Provider...")
x=Provider()
x.delegate()
#最后生成了一个Provider对象,然后调用它的delegate方法,而这个delegate是由超类Super定义的。最终会显示in Provider.action。这意味这虽然在Provider里使用了父类定义的delegate方法,但这个delegate方法实际上使用了在Provider里定义的action。
在超类里包含一些还没有定义的方法,这个超类就是抽象超类。这个例子里Super就是抽象超类。为了使用抽象超类必须在子类中定义这个超类还没有定义的方法,如果不去定义就会报错。
在实践中有些时候为了提醒使用者这是一个抽象超类,让它在被使用之前必须去实现里面没有被实现的方法。有时候会故意在没有实现的方法里面去直接引发NotlmplementedError(python内置的一个异常内容)。
示例如下:
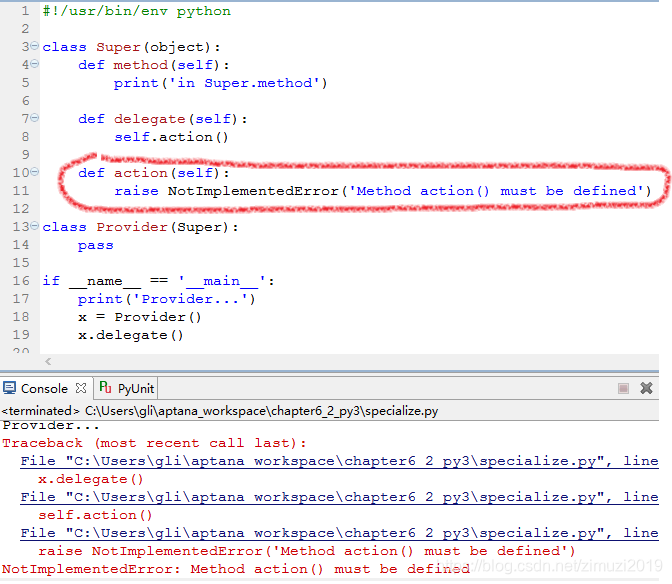
如果没有在Super的子类里重载action方法(这意味着它直接继承了action),这种情况下子类的实例对象直接去调用action的时候就会引发NotlmplementedError,提醒使用者还没有定义自己的action,抽象方法还没有被实现
但是在实践中我们一般不会这么写,实践中如果需要抽象超类一般会直接使用abc模块
示例如下:
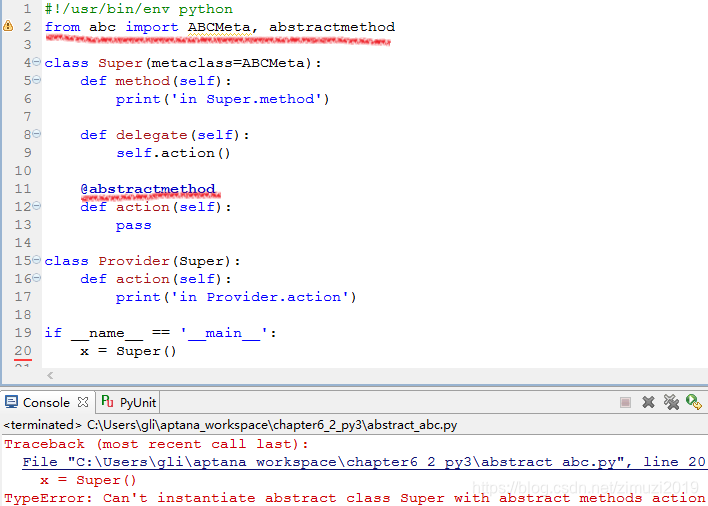
首先要import ABC,然后在抽象超类的继承对象要写Metaclass=ABCMeta。有了这一行之后在抽象超类里写抽象方法可以直接把函数装饰器@abstractmethod放在没有实现真正功能的抽象方法的前面,这样就实现了和之前写法类似的效果。在后面的测试代码中如果直接尝试实例化这个抽象超类就会报错,因为使用Metaclass=ABCMeta的类及其它的子类不能被实例化,除非它的所有抽象方法都被子类重载
python2中使用abc时的语法差异(课上没讲,不是很重要,自己去看课件)
为什么要使用抽象方法?
抽象方法可以为某一个类的众多子类定义一些固定的,共享的接口。开发者可以把这些共享的接口通过抽象超类里面的抽象方法的形式在创建超类的时候做预先的约定。作为超类的创建者的开发者可以预先规定这些接口必须有怎么样的形式,然后去使用这个抽象超类的其他人必须继承开发者的超类,使用者在他的子类里面就必须遵循开发者提前做的约定(这里的约定指的是API接口)
注:考试只会考抽象超类的基本概念,metaclass和ABC模块不会考
多重继承
现在一般不建议去使用多重继承,如果有需要应该去使用mixin
注:多重继承,mixin不考
番外:再谈iterator
之前的章节已经说过迭代对象(iterable)有一个名为 __ iter __ 的方法,它返回一个迭代器对象(iterator),迭代器对象有一个名为 __ next __ 的方法,它被调用一次就返回一个值,直到没有值可以返回时就产生StopIteration 异常
之前提到过 __ iter __ 和 __ next __ 方法可以同时处于一个类中,在这种情况下 __ iter __ 返回self。我们可以说这个可迭代对象是自己的迭代器。
示例:
>>>class Squares(object):
... def __init__(self,start,stop):
... self.value=start-1
... self.stop=stop
...
... def __iter__(self):
... return self
...
... def __next__(self):
... if self.value==self.stop:
... raise StopIteration
... self.value+=1
... return self.value**2
...
>>>s=Squares(1,5)
#由Squares生成它的实例对象s
>>>i=iter(s)
#把实例对象s传给名为iter的内置函数,返回Squares可迭代对象对应的可迭代器i
>>>
>>>i is s
#对比i和s的一致性后返回True,这证明i和s是一个对象。这是因为iter()函数实际上调用的是名为_iter_的方法并返回self。可以说s既是可迭代对象也是迭代器
True
>>>next(s)
1
>>>next(s)
4
>>>next(s)
9
>>>next(s)
16
>>>next(s)
25
>>>next(s)
Traceback (most recent call last)
File "<stdin>",line 1,in <moduel>
File "<stdin>",line 11,in __next__
StopIteration
>>>
之前也提到过迭代器是一次性的。一旦遍历了它的所有值然后产生了StopIteration异常,它就变成了空的。想要再次使用这个迭代器的功能只能再次创建一个新的迭代器对象
示例
>>>class Squares(object):
... def __init__(self,start,stop):
... self.value=start-1
... self.stop=stop
...
... def __iter__(self):
... return self
...
... def __next__(self):
... if self.value==self.stop:
... raise StopIteration
... self.value+=1
... return self.value**2
...
>>>s=Squares(1,5)
>>>i=iter(s)
>>>
>>>i is s
True
>>>[n for n in s]
[1,4,9,16,25]
>>>
>>>[n for n in s]
[]
>>>[n for n in Squares(1,5)]
[1,4,9,16,25]
>>>list(Squares(1,3))
[1,4,9]
同样之前还提到过对于是自身迭代器的可迭代对象(即 __ iter __ 方法会返回self)就无法维持超过一个以上的迭代器状态。这是因为 __ iter __ 方法返回self,对同一个可迭代对象调用 __ iter __ 方法无论调用多少次总返回同一个self
示例:
>>>class Squares(object):
... def _init_(self,start,stop):
... self.value=start-1
... self.stop=stop
...
... def _iter_(self):
... return self
...
... def _next_(self):
... if self.value==self.stop:
... raise StopIteration
... self.value+=1
... return self.value**2
...
>>>s=Squares(1,5)
>>>
>>>i1=iter(s)
>>>
>>>next(i1)
1
>>>next(i1)
4
>>>i2=iter(s)
>>>
>>>next(i2)
9
>>>
>>>i1 is i2,i1==i2
(True,True)
如果想要多个独立的迭代器就要让 __ iter __方法别再返回self而是每次返回一个新的对象
例子如下,这是一个可以有多个迭代器的可迭代对象,注意它把可迭代对象和迭代器分成了两个类
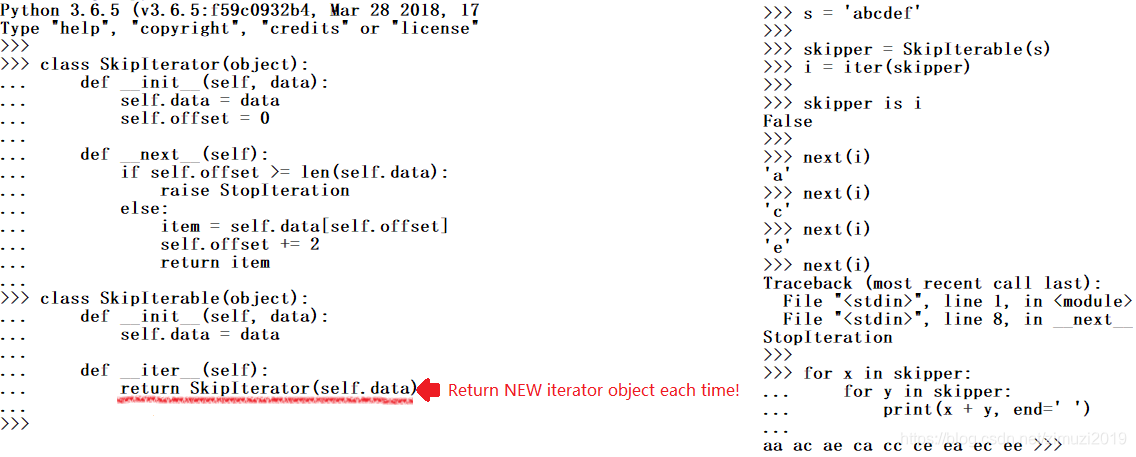
以上代码中SkipIterable是一个可迭代对象, __ iter __ 方法不再返回迭代器而是返回SkipIterator类的一个实例对象。SkipIterator是一个迭代器。在这种情况下你就可以通过SkipIterable生成一个实例对象Skipper,由Skipper可迭代对象能够生成多个迭代器,注意下面那个嵌套的for循环,每一层循环都使用了一个状态独立的迭代器
>>>class Squares(object):
... def _init_(self,start,stop):
... self.value=start-1
... self.stop=stop
...
... def _iter_(self):
... return self
...
... def _next_(self):
... if self.value==self.stop:
... raise StopIteration
... self.value+=1
... return self.value**2
...
>>>s=Squares(1,5)
>>>
>>>i1=iter(s)
>>>
>>>next(i1)
1
>>>next(i1)
4
>>>i2=iter(s)
>>>
>>>next(i2)
9
>>>
>>>i1 is i2,i1==i2
(True,True)
如果想要多个独立的迭代器就要让 __ iter __方法别再返回self而是每次返回一个新的对象
例子如下,这是一个可以有多个迭代器的可迭代对象,注意它把可迭代对象和迭代器分成了两个类
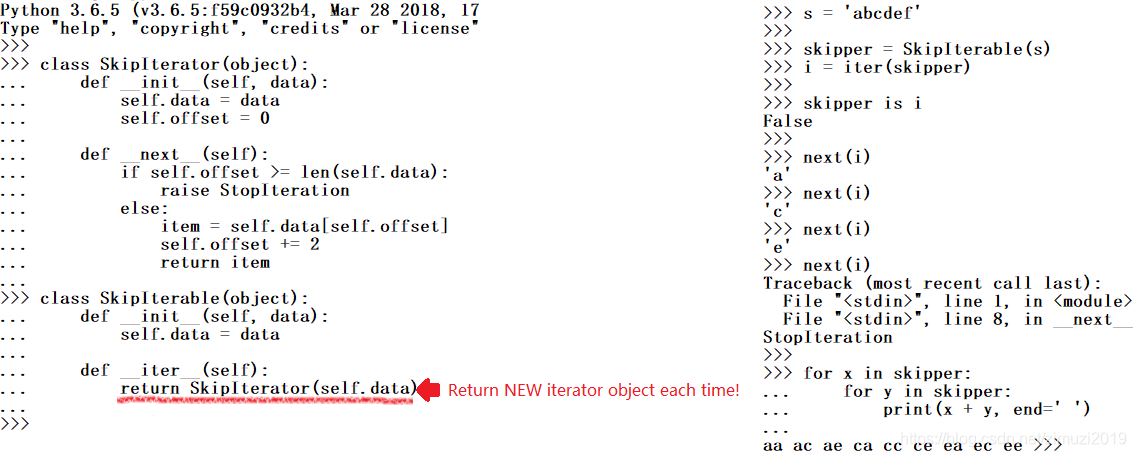
以上代码中SkipIterable是一个可迭代对象, __ iter __ 方法不再返回迭代器而是返回SkipIterator类的一个实例对象。SkipIterator是一个迭代器。在这种情况下你就可以通过SkipIterable生成一个实例对象Skipper,由Skipper可迭代对象能够生成多个迭代器,注意下面那个嵌套的for循环,每一层循环都使用了一个状态独立的迭代器
编辑于2020-5-26 14:42