一、算法定义与机器学习的流程
(一)机器学习算法
1. 机器学习的核心
机器学习的核心:将历史数据训练成模型对未来属性进行预测。
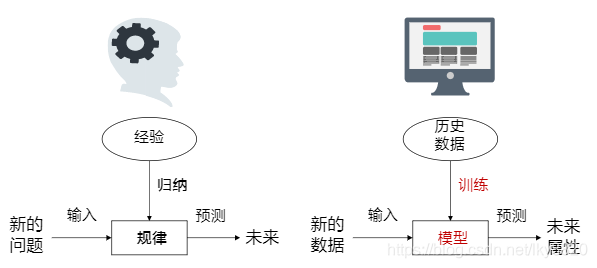
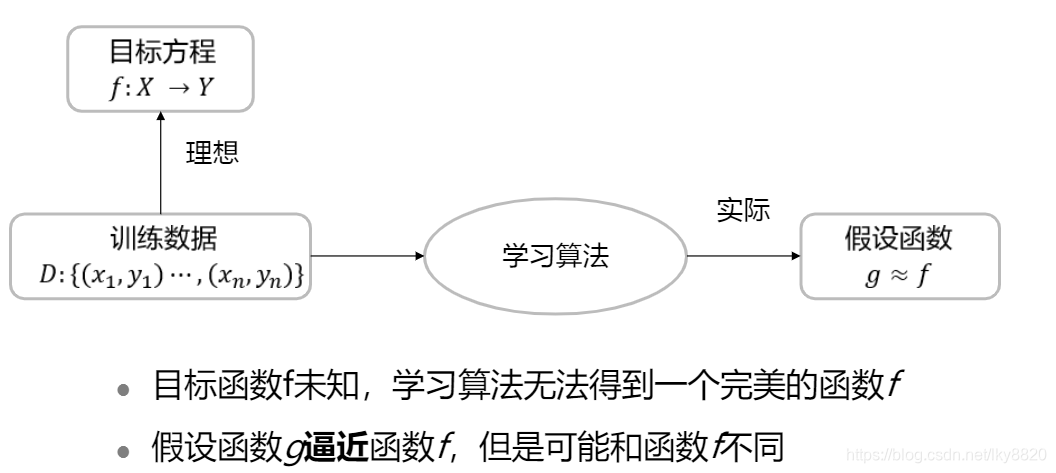
2. 常见学习任务
机器学习常见任务:
1、分类:离散值。会告诉计算机是什么。(有监督学习)
2、回归:连续值。(有监督学习)
3、聚类:不告诉计算机是什么东西,自己去分辨。相似的东西会聚在一起。(无监督学习)

3. 机器学习分类

强化学习:
模型感知环境,做出行动,根据状态与奖惩做出调整和选择。(最佳行为)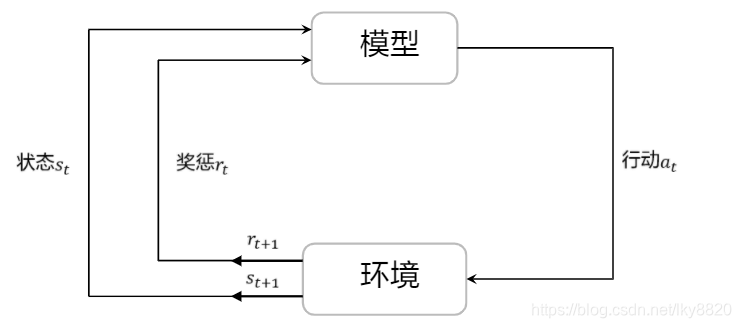
(二)机器学习的流程及训练数据
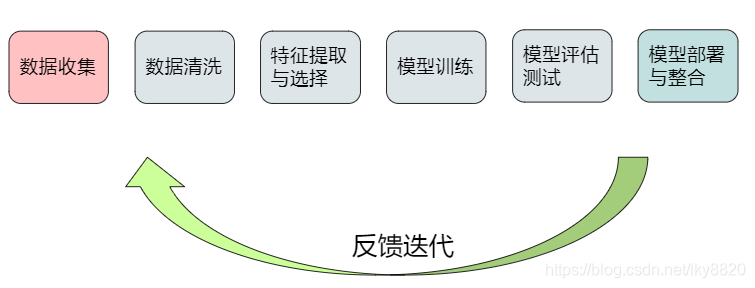
1. 机器学习流程***
①收集有意义的数据
②数据清洗
③数据特征的提取和选择
④模型训练(算法)***
⑤模型评估测试
⑥模型部署与整合
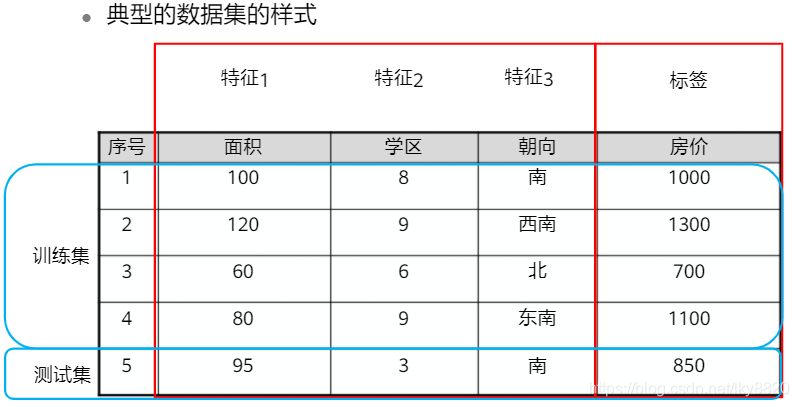
2. 数据概览
注:含有标签的数据,可以用来做有监督学习。除去标签,可以用来做无监督学习。
3. 数据预处理
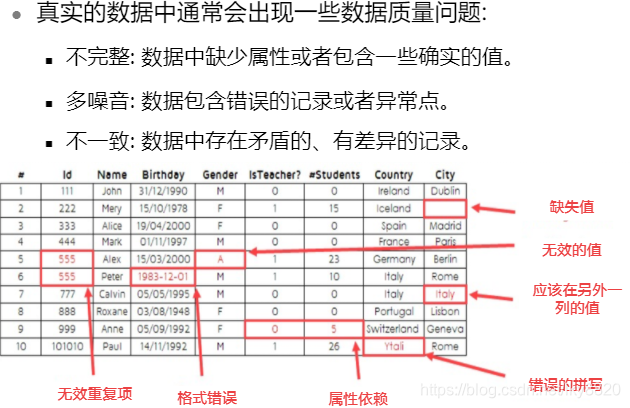
a. 数据清理:填充缺失项,发现并消除造成数据及异常点。清理“脏数据”。
b. 数据标准化:标准化数据来减少噪声,以提高模型准确性。
c. 数据降维:简化数据属性,避免唯独爆炸。
“脏数据”特点如下:
4. 数据转换

5. 特征选择
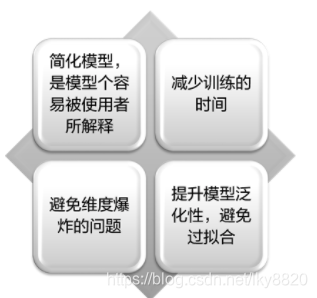
通常情况下,一个数据集当中存在很多种不同的特征,其中一些可能是多余的或者与我们要预测的值无关的。
特征选择技术的必要性体现在:
二、机器学习模型
(一)评估
1. 模型评判标准
a. 泛化能力***:
能否在实际的业务数据也能预测准备。
简单来说:泛化能力强就是学以致用的能力强。
b. 可解释性
c. 预测速率
d. 可塑性
2. 模型的有效性
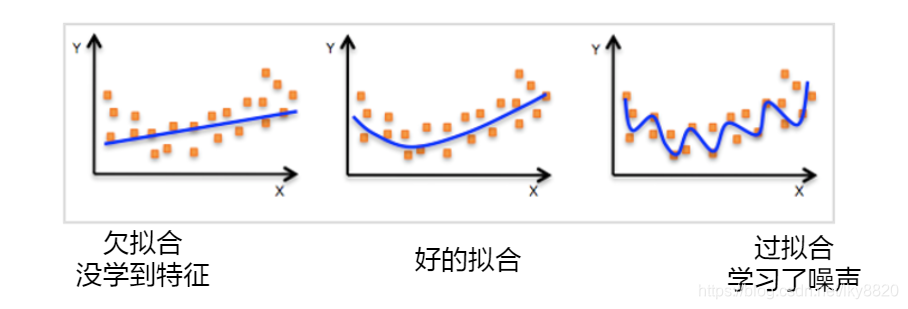
模型的容量:指其拟合各种函数的能力,也称为模型的复杂度。
容量不足:可能出现欠拟合。
容量高:可能出现过拟合。
3. 机器学习性能评估
a. 回归:
yi:预测值
y^i:真实值

b. 分类:
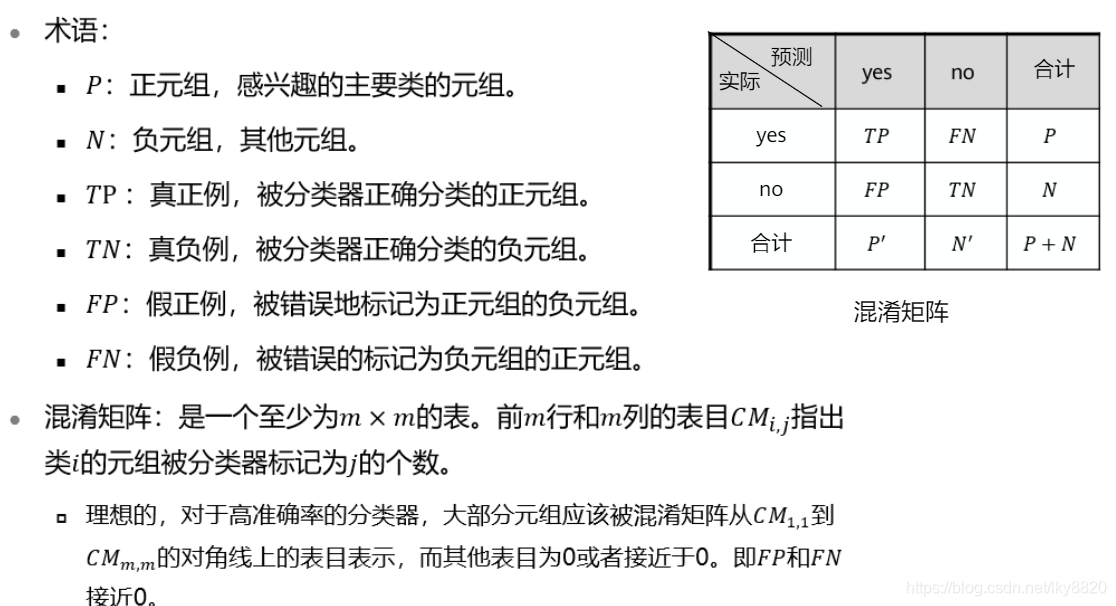
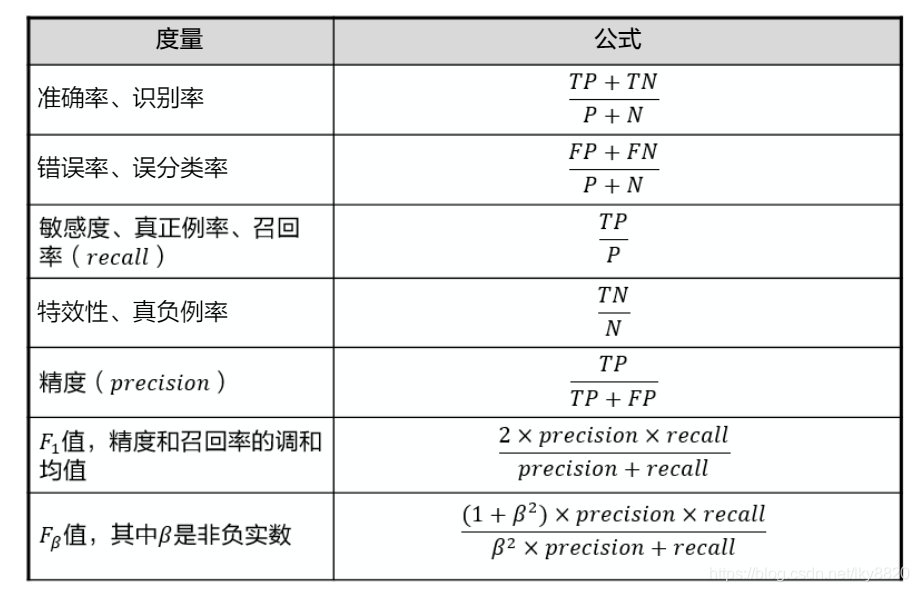
(二)训练方法
1. 梯度下降算法
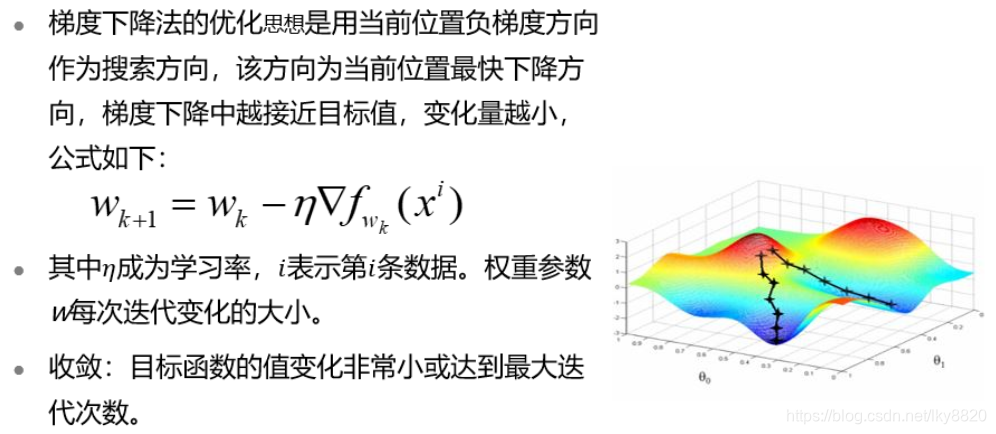
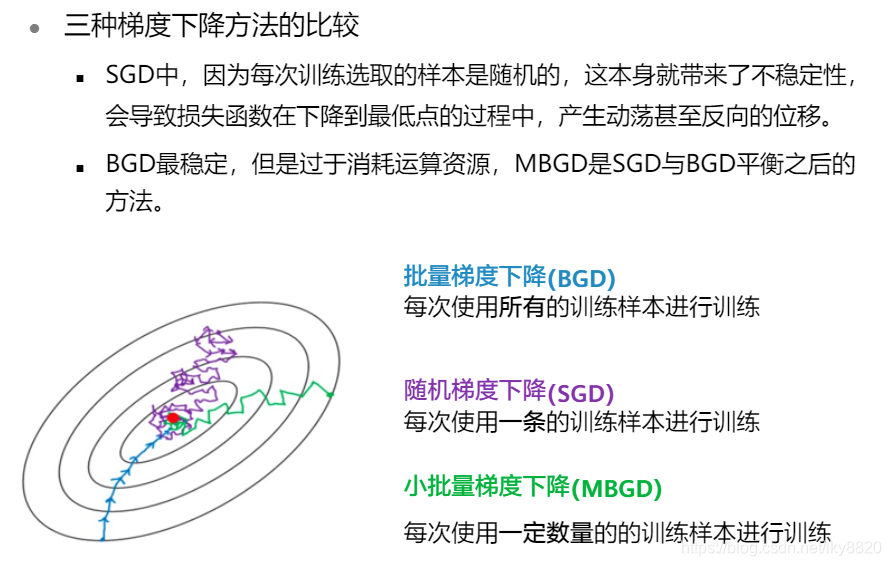
(三)参数与超参数
1. 定义
参数:模型自动学习。
超参数:人工手动设定。(通过调超参数,控制模型训练)
超参数一些例子如下:

2. 超参数搜索

3. 超参数调节方法
a. 网格搜索:

b. 随机搜索
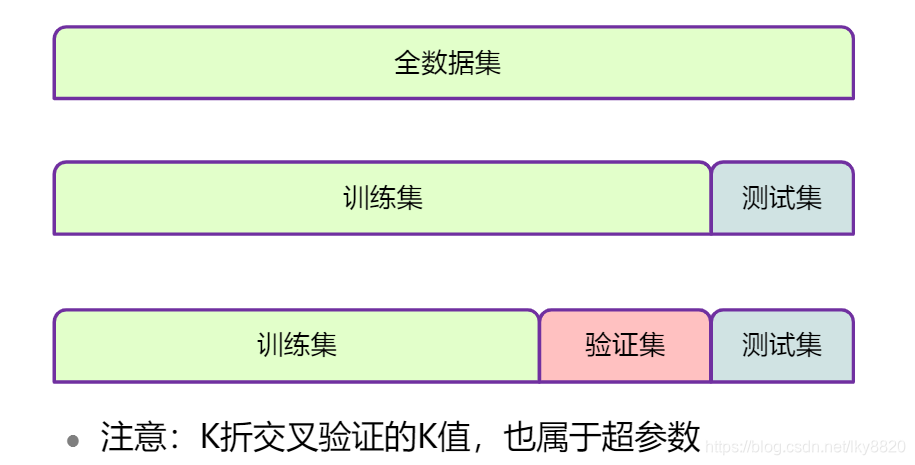
注:交叉验证思想:避免模型偶然出现特别好或特别差的情况。
三、机器学习的常见算法
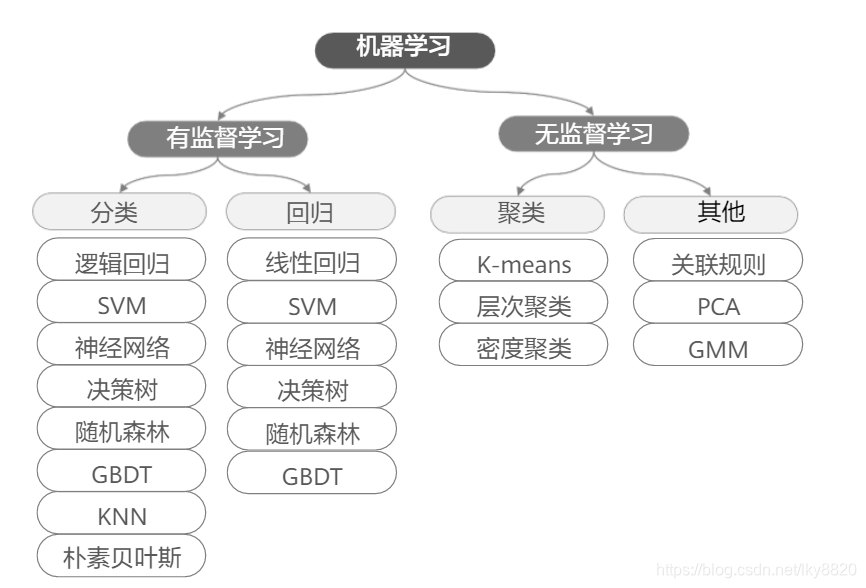
(一)常用算法
1.线性回归(回归问题)
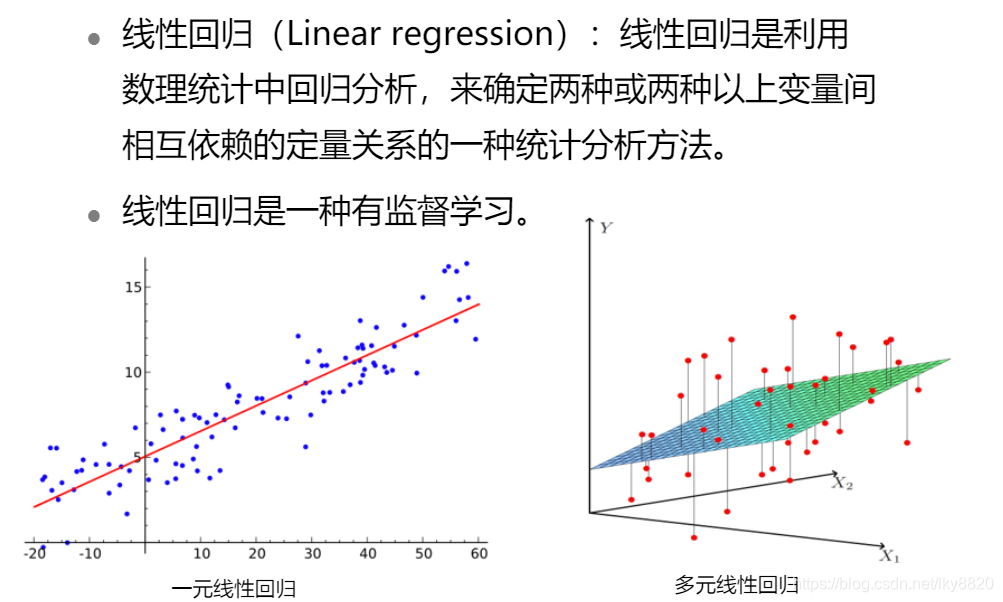

线性回归防止过拟合:

2.逻辑回归(分类问题)


3. softmax回归(回归问题)
用于多分类问题。

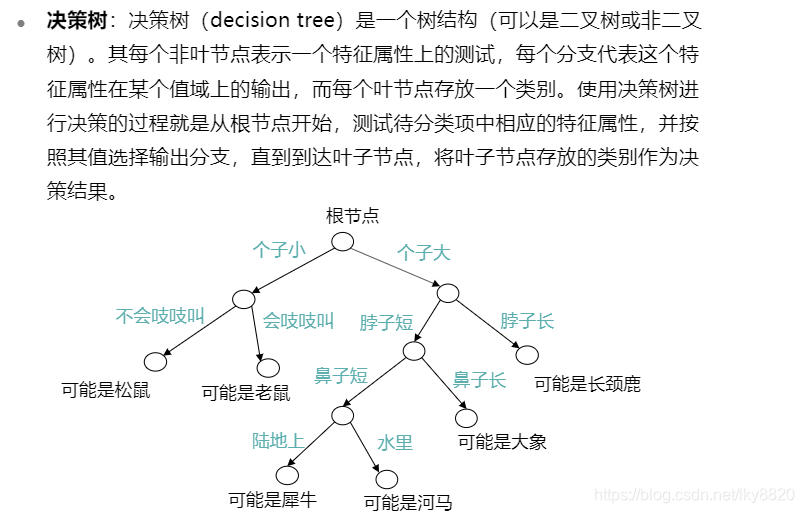
4. 决策树(回归,分类问题)
(二)向量机
1. 支持向量机
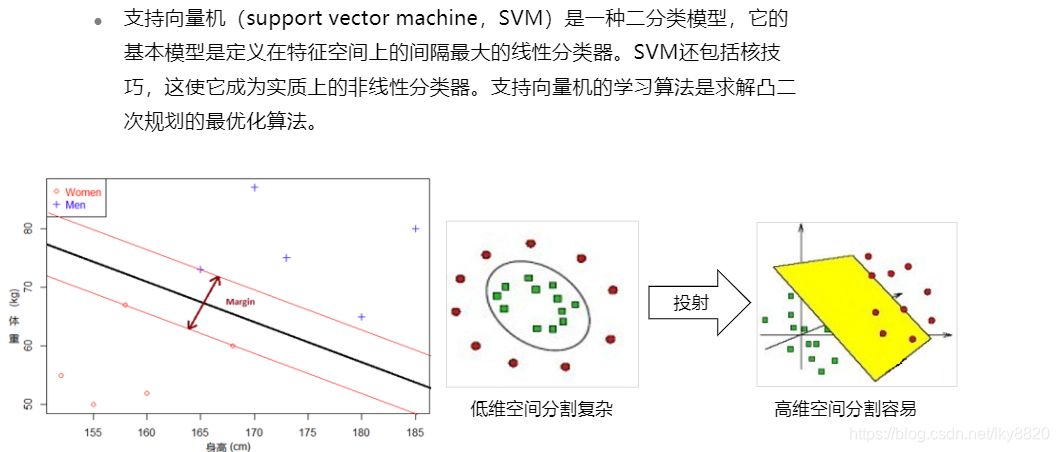
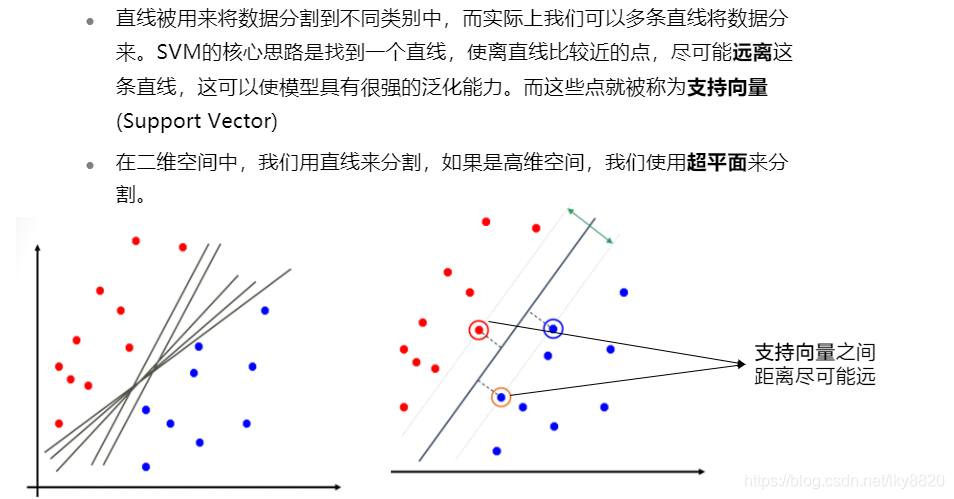
2. 线性支持向量机
离得尽量远,更容易分类。泛化能力更强。
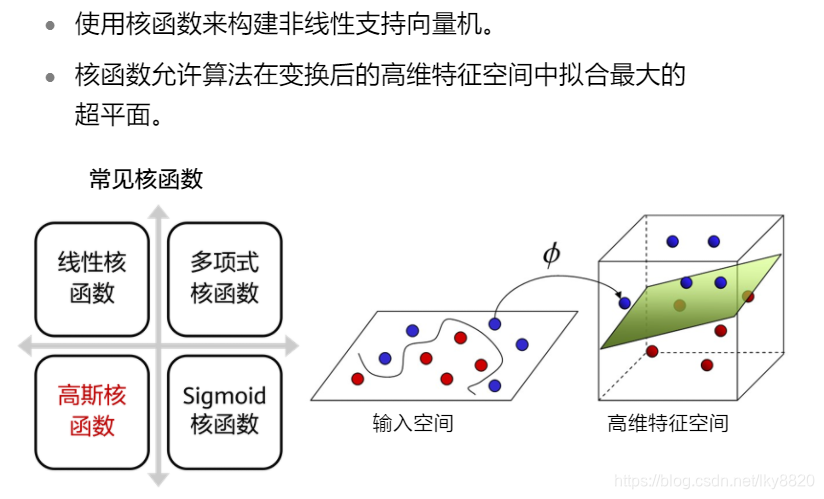
3. 非线性支持向量机
(三)常用分类算法
1. K最邻近算法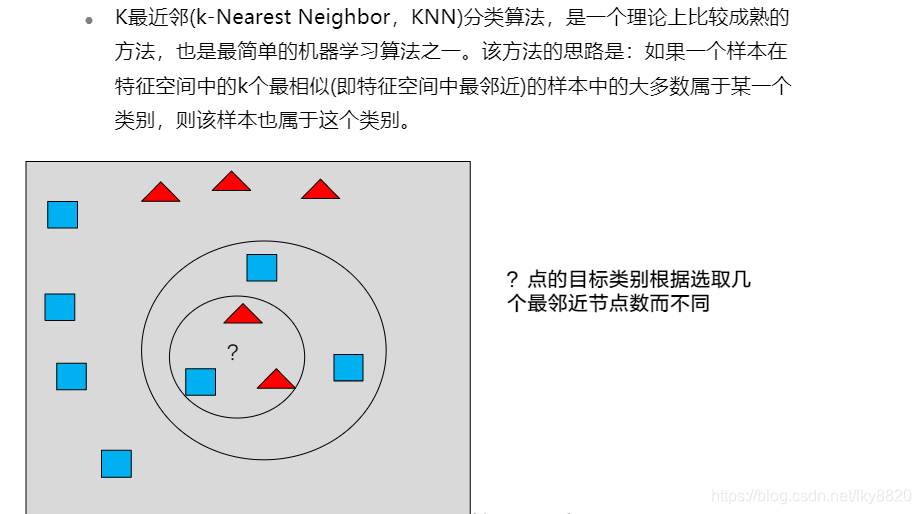
2. 朴素贝叶斯

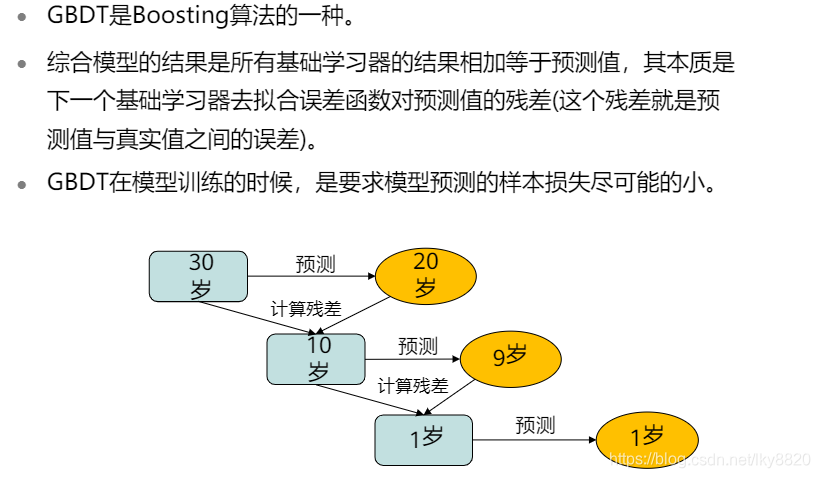
3. 集成学习(回归,分类问题)
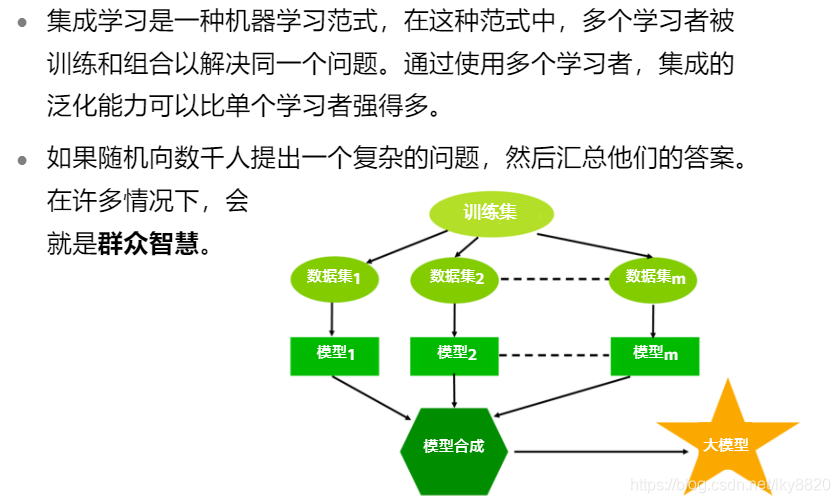
a. 随机森林
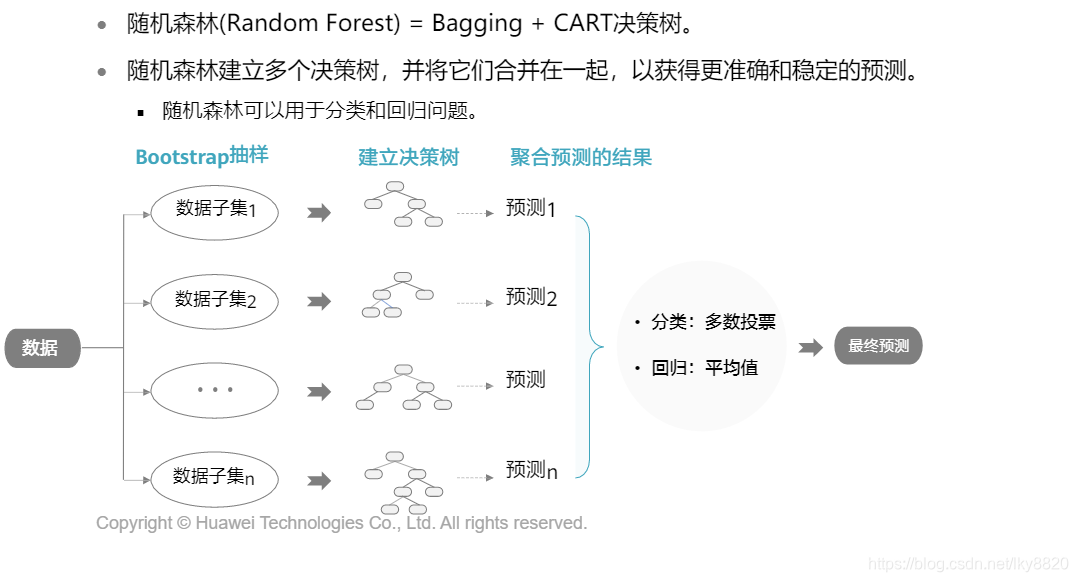
b. GBDT
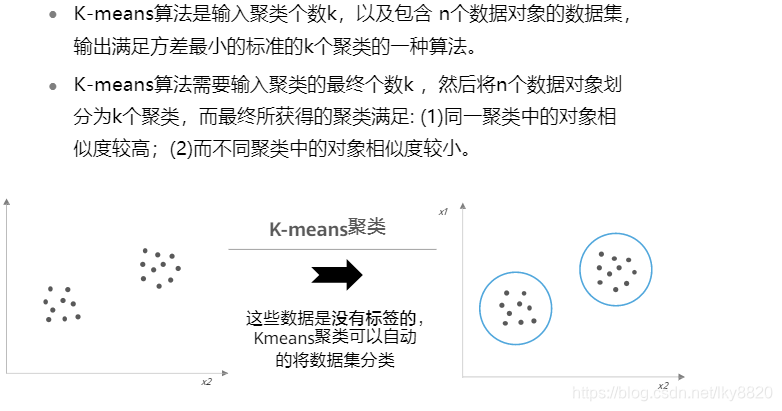
(四)常用聚类算法
1.K-Means聚类(无监督模型)
2. 层次聚类(无监督模型)

四、具体案例——房价预测
(一)问题分析
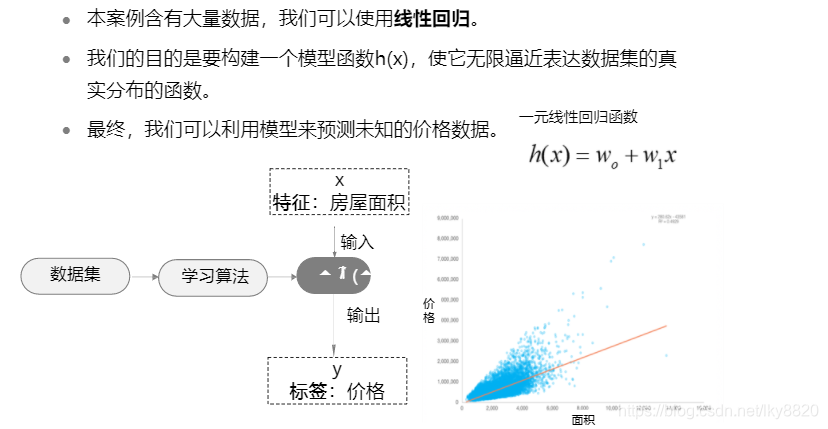
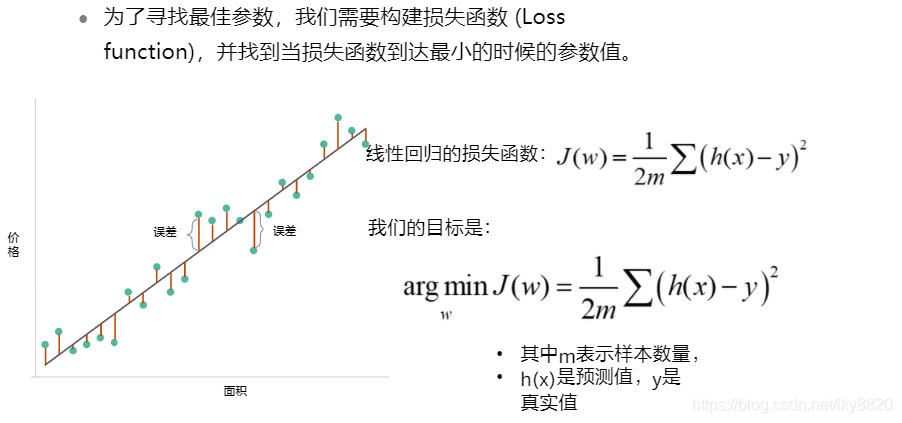
(二)线性回归的损失函数
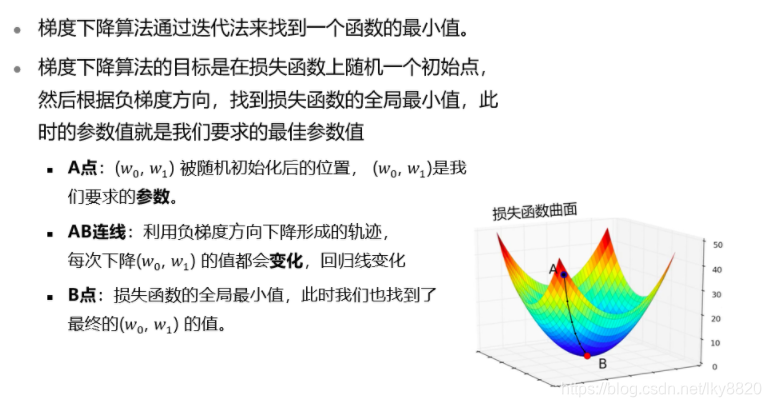
(三)梯度下降算法
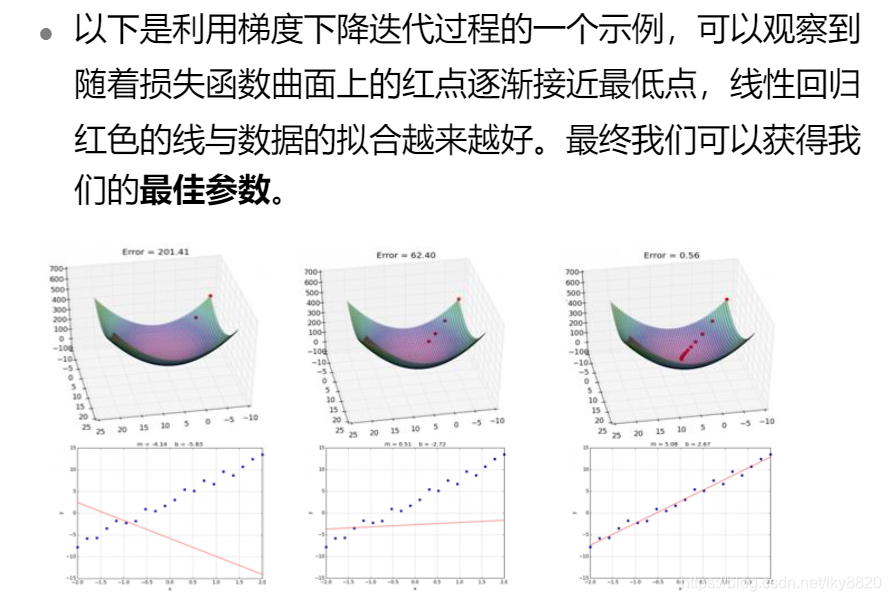
(四)迭代过程示例
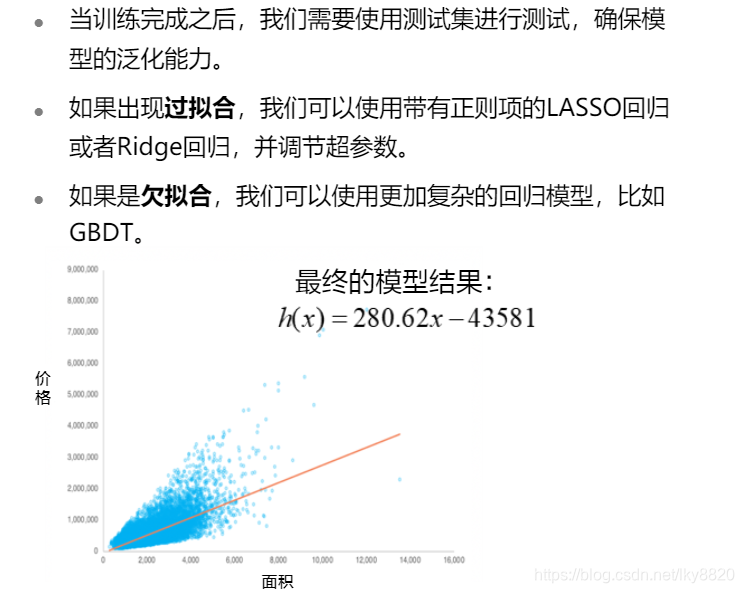
(五)模型调试与应用
作业思考:如何构建一个猫狗图像分类的问题,利用机器学习可以如何构建流程?
收集数据:先收集一定量猫狗图像作为数据集。
数据清洗:将“脏数据”处理掉。
特征提取
模型训练:选择合适的神经网络模型进行分类训练。
模型评估与测试:一部分猫狗图片测试集进行测试及预测。
模型的部署