一、element如何生成真实DOM节点
触发组件的更新有两种更新方式:props以及state改变带来的更新。本次主要解析state改变带来的更新。整个过程流程图如下:
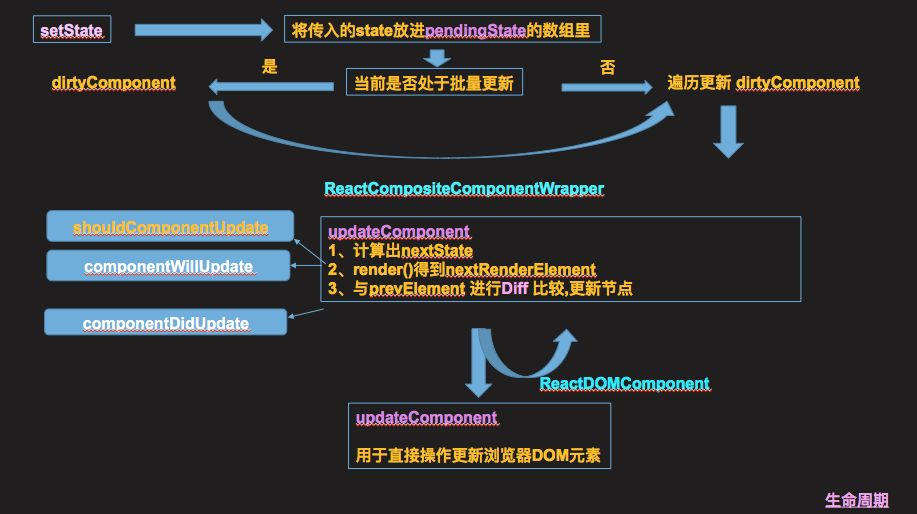
1、一般改变state,都是从setState开始,这个函数被调用之后,会将我们传入的state放进pendingState的数组里存起来,然后判断当前流程是否处于批量更新,如果是,则将当前组件的instance放进dirtyComponent里,当这个更新流程中所有需要更新的组件收集完毕之后(这里面涉及到事务的概念,感兴趣的可以自己去了解一下)就会遍历dirtyComponent这个数组,调用他们的uptateComponent对组件进行更新。当然,如果当前不处于批量更新的状态,会直接去遍历dirtyComponent进行更新。
2、在我们这个例子中,由于Example是自定义组件,所以调用的是ReactCompositeComponentWrapper这个类的updateComponent方法,这个方法做三件事。
计算出nextState
render()得到nextRenderElement
与prevElement 进行Diff 比较(这个过程后面会介绍),更新节点
最后这个需要去更新节点的时候,跟首次渲染一样,也需要调用ReactDOMComponent的updateComponent来更新。其中第二步render得到的也是自定义组件的话, 会形成递归调用。
接下来,还是上次的问题:那么更新过程中的生命周期函数,shouldComponentUpdate,componentWillUpdate跟componentDidUpdate在哪被调用呢?

shouldComponentUpdate
由图可知,shouldComponentUpdate在第一步调用得到nextState之后调用,因为nextState也是它的其中一个参数嘛~这个函数很重要,它是我们性能优化的一个很关键的点:由图可以看到,当shouldComponentUpdate返回false的时候,下面的一大块都不会被去执行,包括已经被优化的diff算法。
当shouldComponentUpdate返回true的时候,会先调用componentWillUpdate,在整个更新过程结束之后调用componentDidUpdate。
以上就是更新渲染的过程。
Diff算法
React基于两个假设:

两个相同的组件产生类似的DOM结构,不同组件产生不同DOM结构
对于同一层次的一组子节点,它们可以通过唯一的id区分
发明了一种叫Diff的算法来比较两棵DOM tree,它极大的优化了这个比较的过程,将算法复杂度从O(n^3)降低到O(n)。
同时,基于第一点假设,我们可以推论出,Diff算法只会对同层的节点进行比较。如图,它只会对颜色相同的节点进行比较。

也就是说如果父节点不同,React将不会在去对比子节点。因为不同的组件DOM结构会不相同,所以就没有必要在去对比子节点了。这也提高了对比的效率。
下面,我们具体看下Diff算法是怎么做的,这里分为三种情况考虑
-
节点类型不同
-
节点类型相同
-
子节点比较
不同节点类型
对于不同的节点类型,react会基于第一条假设,直接删去旧的节点,新建一个新的节点。
比如:
<A>
<C/>
</A>
// 由shape1到shape2<B>
<C/>
</B>
React会直接删掉A节点(包括它所有的子节点),然后新建一个B节点插入
为了验证这一点,我打印出了从shape1到shape2节点的生命周期,链接如下:
https://codesandbox.io/s/lyop4w9x9mlyop4w9x9m - CodeSandboxlyop4w9x9m - CodeSandbox
最后终端输出的结果是:
Shape1 :
A is created
A render
C is created
C render
C componentDidMount
A componentDidMountShape2 :
A componentWillUnmount
C componentWillUnmount
B is created
B render
C is created
C render
C componentDidMount
B componentDidMount
由此可以看出,A与其子节点C会被直接删除,然后重新建一个B,C插入。这样就给我们的性能优化提供了一个思路,就是我们要保持DOM标签的稳定性。
打个比方,如果写了一个<div><List /></div>(List 是一个有几千个节点的组件),切换的时候变成了<section><List /></section>,此时即使List的内容不变,它也会先被卸载在创建,其实是很浪费的。
相同节点类型
当对比相同的节点类型比较简单,这里分为两种情况,一种是DOM元素类型,对应html直接支持的元素类型:div,span和p,还有一种是自定义组件。
- DOM元素类型
react会对比它们的属性,只改变需要改变的属性
比如:
<div className="before" title="stuff" />
<div className="after" title="stuff" />
这两个div中,react会只更新className的值
<div style={{color: 'red', fontWeight: 'bold'}} />
<div style={{color: 'green', fontWeight: 'bold'}} />
这两个div中,react只会去更新color的值
- 自定义组件类型
由于React此时并不知道如何去更新DOM树,因为这些逻辑都在React组件里面,所以它能做的就是根据新节点的props去更新原来根节点的组件实例,触发一个更新的过程,最后在对所有的child节点在进行diff的递归比较更新。
- shouldComponentUpdate
- componentWillReceiveProps
- componentWillUpdate
- render
- componentDidUpdate
子节点比较
<div>
<A />
<B />
</div>
// 列表一到列表二<div>
<A />
<C />
<B />
</div>
因为React在没有key的情况下对比节点的时候,是一个一个按着顺序对比的。从列表一到列表二,只是在中间插入了一个C,但是如果没有key的时候,react会把B删去,新建一个C放在B的位置,然后重新建一个节点B放在尾部。
我们还是跑一边代码,看看生命周期验证一下,连接地址为:lpl52wy9vl - CodeSandbox
列表一:
A is created
A render
B is created
B render
A componentDidMount
B componentDidMount列表二:
A render
B componentWillUnmount
C is created
C render
B is created
B render
A componentDidUpdate
C componentDidMount
B componentDidMount
当节点很多的时候,这样做是非常低效的。有两种方法可以解决这个问题:
1、保持DOM结构的稳定性,我们来看这个变化,由两个子节点变成了三个,其实是一个不稳定的DOM结构,我们可以通过通过加一个null,保持DOM结构的稳定。这样按照顺序对比的时候,B就不会被卸载又重建回来。
<div>
<A />
{null} <B />
</div>
// 列表一到列表二<div>
<A />
<C />
<B />
</div>
2、key
通过给节点配置key,让React可以识别节点是否存在。
配上key之后,在跑一遍代码看看。
A render
C is created
C render
B render
A componentDidUpdate
C componentDidMount
B componentDidUpdate
果然,配上key之后,列表二的生命周期就如我所愿,只在指定的位置创建C节点插入。
这里要注意的一点是,key值必须是稳定(所以我们不能用Math.random()去创建key),可预测,并且唯一的。
这里给我们性能优化也提供了两个非常重要的依据:
-
保持DOM结构的稳定性
-
map的时候,加key