环境: Python3.7
工具: Pycharm
robots协议
反爬机制
在域名后面加上robots.txt
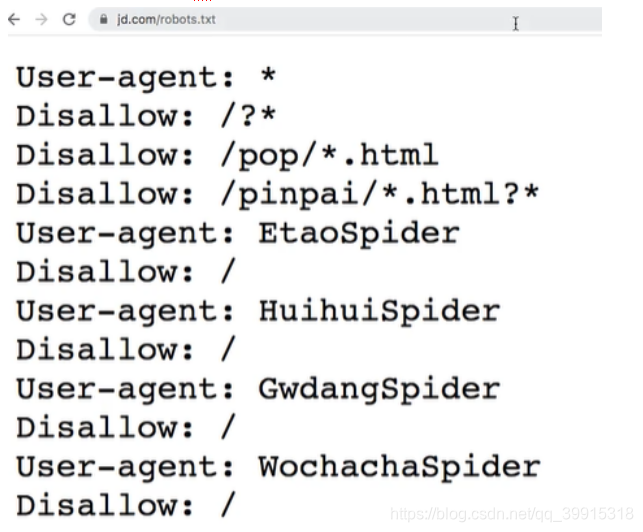
指的是一个纯文本的协议,指的是一个纯文本的协议,协议中规定了该网站中那些数据可以被那些爬虫爬取,哪些不可以被爬取。额 就是一纸书文,防君子不妨小人,而且大都写的是都不可爬(规则之内’越规’)
反反爬策略
这是一个良心活,过不去就×掉换别的网站,无所谓就爬(做爬虫的一般是不管0.0)
UA检测
反爬机制
在发起的请求头headers中,包含了很多键值对,服务器会根据这些键值对进行反爬,

反反爬策略 UA伪装 UA池
缺少什么就添加上什么 模拟浏览器发起请求
当你的python爬虫程序发起请求的时候如果不在headers中添加上User-Agent的话就会默认填上python,这样的话绝大多数网站就会拒绝给你发送响应,这时我们要添加上User-Agent在发起请求就可以请求到数据
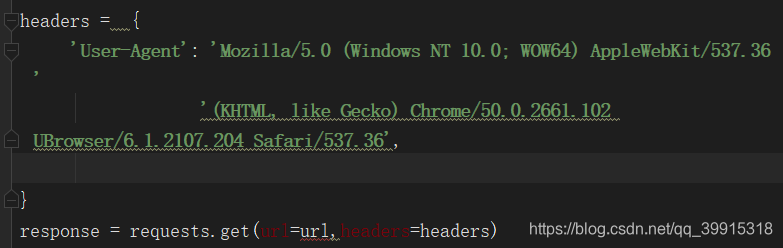
但是,浏览器也有可能检测短时间内同一浏览器请求情况,如果请求过快就直接封禁,或者执行其他反爬策略,
解决方式一: 降低发起请求的频率
解决方式二:
设置UA伪装池,发起请求的时候随机获取UA进行请求
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
headers = {
‘User-Agent’: random.choice(user_agent_list)
}
之后发起一次请求用一次新的headers就可以了
也可以通过fake_useragent模块来实现UA伪装
模块下载: pip install fake-useragent
from fake_useragent import UserAgent
ua = UserAgent() # 实例化,实例化时需要联网但是网站不太稳定
print(ua.random) # 随机打印 User-Agent
封禁IP
反爬机制
通过服务端内部的一些操作来检测同一时间高频率的请求IP,如果确认(不是正常人能做到的),就会直接封禁IP,就会造成长时间同一IP无法请求数据的情况,一般要等一天左右吧,可能更长,这里就不去尝试了
反反爬策略 代理IP 代理IP池
代理服务器分为不同的匿名度:
- 透明代理:如果使用了该形式的代理,服务器端知道你使用了代理机制也知道你的真实IP
- 匿名代理:知道你使用了代理,但是不知道你的真实IP
- 高匿代理:不知道你使用了代理也不知道你的真实IP
代理类型:
- https:代理只能转发https协议请求
- http:只能转发http请求
如果是使用单个代理IP的话,可以去快代理、西祠代理、goubanjia等代理网站去尝试可用的免费代理,因可用的免费代理过少,寻找过程过于艰难性价比低等原因,所以就不详解免费代理如何使用了
代理IP池:
付费代理这里推荐的是智连HTTP(之前好像叫代理精灵?): http://http.zhiliandaili.cn/
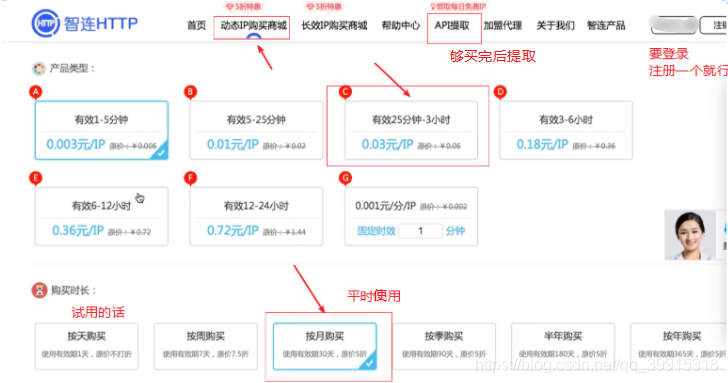
提取ip的时候一定要把本机ip(手机热点的话就是手机ip,去网上一查就可以了)加入ip白名单中
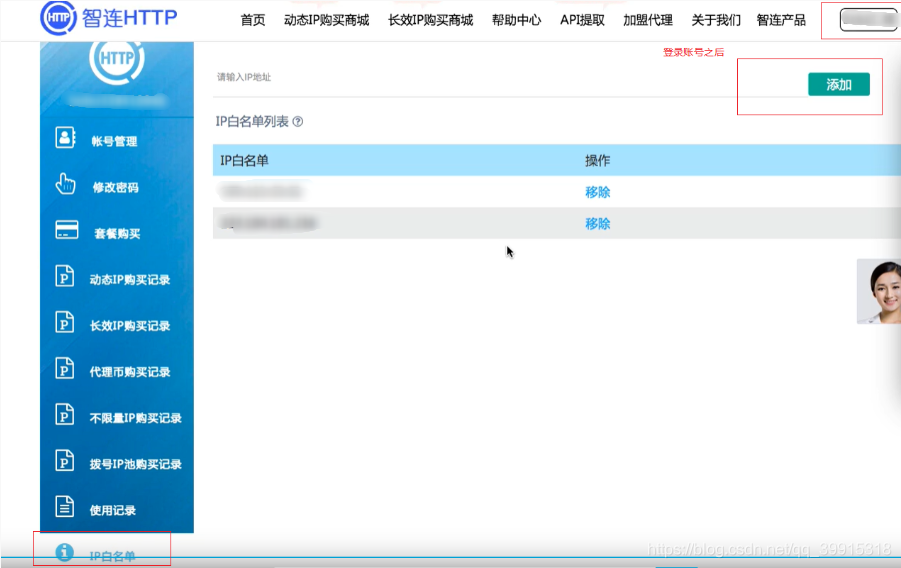
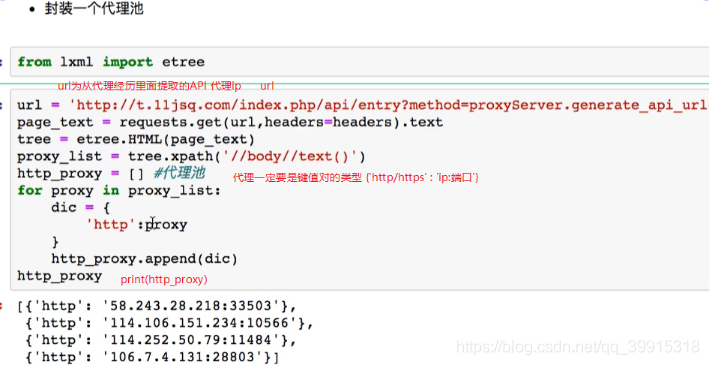
代理ip AIP url源码