目录

本文有视频讲解,视频和实例源码下载方式:点击->我的主页,查看个人简介。
我尽量坚持每日更新一节。
更多python教程,请查看我的专栏《0基础学python视频教程》
1、什么是“函数”
前面我们讲过,所谓“程序”,就是通过逻辑去控制一系列数据按照预期处理,从而达成我们需要的某个特定功能。所以,理论上,我们只需要前面学的数据结构和控制语句,我们就可以写所有的“程序”了。
但是,现实中,我们的程序要复杂得多。拿我平时工作中的产品为例,其完整的代码量可达数百万行。如何组织这些代码?如何更好的维护这些代码?如何让几十几百名工程师同时开发这些代码?如何在这些代码基础上新增功能?等等,这些问题会比代码语法本身更重要。解决这些问题的本质,是要对代码进行合理的“抽象”和“封装”,使其具备一定的组织结构,这就是所谓的“架构”。
作为高级编程语言,python必须提供一些机制,以便于我们实现代码“架构”。函数,就是这些机制中最基础的一个。
接下来我们会花很多章节来学习这些机制,包括函数、模块、包、类等等。
我们以实现list求和这样一个简单的功能为例:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_1.py
# 实现 list 求和
list_1 = [100, 200, 300, 400]
list_sum = 0
for item in list_1:
list_sum += item
print(list_sum)
上面一段代码,实现了对list_1这个列表中所有元素的求和。没有任何问题。代码很清晰简洁。下面我们对这个功能进行一些扩充,我们增加一个列表list_2,也需要求和。实现如下:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_1.py
# 实现 list 求和
list_1 = [100, 200, 300, 400]
list_2 = list(range(10, 100, 5))
list_sum = 0
for item in list_1:
list_sum += item
print(list_sum)
list_sum = 0
for item in list_2:
list_sum += item
print(list_sum)
也能实现我们需要的功能,可是这段代码总让人看着不那么完美,不那么优美。里面两段通过for循环求和的代码块,非常类似。试想,如果我们想得到多个list的和,这段代码是不是会一直重复写下去?
基于这个简单的例子,我们来理解“抽象”和“封装”的概念。
“抽象”,就是提取出代码中的一部分“共性”逻辑或者功能。
“封装”,就是将这些“共性”逻辑或者功能组织在一起,并提供给别人使用。
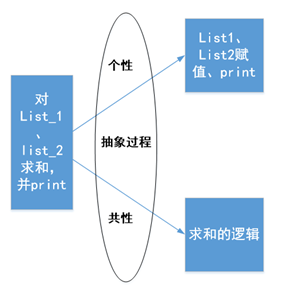

抽象和封装,是作为程序员必须具备的基本能力和基本素质。不论你是初级程序员,还是架构师,这两项能力都始终贯穿我们的工作中。
这个例子,我们可以通过函数,来实现对求和逻辑的封装。
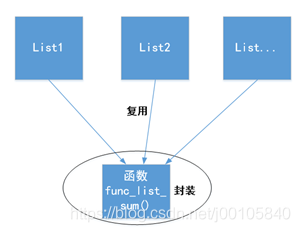
通过封装函数func_list_sum(),我们实现了求和逻辑的复用,它不仅可以给list1、list2使用,甚至可以给所有的列表使用。代码的复用,可以给我们带来很多好处,比如:代码更加简洁、提升开发效率、提升代码可靠性等。
经过函数封装后,这个实例实现如下:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_1.py
def func_list_sum(l):
"""
实现 list 求和
"""
s = 0
for item in l:
s += item
return s
list_1 = [100, 200, 300, 400]
list_2 = list(range(10, 100, 5))
print(func_list_sum(list_1))
print(func_list_sum(list_2))
封装可以让我们的代码很方便的扩展,比如我们在求和时需要检查成员是否是整数,函数封装后,我们只需要修改这个函数里面的代码即可扩展该功能。
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_1.py
def func_list_sum(l):
"""
实现 list 求和
"""
s = 0
for item in l:
if type(item) is not int: # 必须是整数
continue
s += item
return s
list_1 = [100, 200, 300, 400]
list_2 = list(range(10, 100, 5))
print(func_list_sum(list_1))
print(func_list_sum(list_2))
2、函数的语法
2.1、语法定义
函数的语法定义如下:
def func_name(params…):
func_body
‘def’是定义函数的保留字,func_name是函数名,其命名规则和变量名是一致的。后面的小括号里面是该函数对应的入参列表,多个参数用逗号隔开,可以不带参数。关于入参的写法,下面我们会详细介绍。小括号后面是冒号。func_body是函数体,可以为空语句pass,或者多语句组成的代码块,甚至是一个函数(后面章节会讲函数的嵌套)。
2.2、形参与实参
形参和实参的概念,在所有高级编程语言中都类似。
形参:形式上的参数,它是我们在定义函数时用到的参数;
实参:实际的参数,它是我们在真正调用函数时传递的参数。
下面我们通过一个函数来生成著名的Fibonacci (斐波那契)数列:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_2.py
def get_fib(max):
"""
打印斐波那契数列 Fibonacci
:param max:
:return:
"""
a, b = 0, 1
while a < max:
print(a, end=' ')
a, b = b, a + b
print()
input_max = int(input("input max number for Fibonacci:"))
print("\n1Fibonacci is:")
get_fib(input_max)
输出为:
input max number for Fibonacci:1000
Fibonacci is:
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
这个例子中,我们定义了函数get_fib(max)。在定义这个函数的时候,参数max它并没有实际意义上的值,也没有给它分配对象空间,它就是所谓的“形参”。
下面这行代码调用这个函数:
get_fib(input_max)
传入了变量input_max,它是一个真正的变量,是有对象空间的,它被称为“实参”。
2.3、值传递和引用传递
这个概念我们讲可变数据类型和不可变数据类型的时候提到过。
值传递(pass-by-value):传递给函数的,是变量对应的值。函数里面会重新分配一个对象,并将该值拷贝过去。函数里面对新对象进行操作,与原变量无关。不可变数据类型,采用值传递的方式,比如字符串、数字、元组、不可变集合、字节等。值传递方式,需要使用return来返回结果。
引用传递(pass-by-reference):传递给函数的,是变量指向对象的引用(CPython中就是内存地址)。函数里面直接对这个对象进行操作,会直接影响原变量。可变数据类型,采用引用传递的方式,比如列表、字典、可变集合等。
值传递和引用传递,取决于变量指向的对象数据类型。同一个函数的参数列表中,可以同时包含值传递和引用传递。
这里不再举例,大家可以回过头去看看可变数据类型和不可变数据类型章节的例子。
2.4、必选参数和可选参数
有时候,我们希望调用函数时,只传入一些必需的参数,而忽略其它参数。比如我们前面使用到的很多python内建函数(built-in)都是这样的。
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
"""
pass
这是print函数的定义,它有很多参数,但通常我们只传递一个字符串进去,或者再追加一个end参数,其它参数都没有填。
所以,我们定义的函数参数列表,是可以支持可选参数和必选参数。Python并没有提供方法让我们指定某个参数是否可选或者必选,而是通过设置参数的默认值,来达到此效果。
下面这个例子是官方文档里面的:
def ask_ok(prompt, retries=4, reminder='Please try again!'):
while True:
ok = input(prompt)
if ok in ('y', 'ye', 'yes'):
return True
if ok in ('n', 'no', 'nop', 'nope'):
return False
retries = retries - 1
if retries < 0:
raise ValueError('invalid user response')
print(reminder)函数ask_ok有三个参数,第一个参数prompt是必选参数,后面两个指定了缺省值,是可选参数。
这个函数可以通过几种方式调用:
- 只给出必需的参数:ask_ok('Do you really want to quit?')
- 给出一个可选的参数:ask_ok('OK to overwrite the file?', 2)
- 或者给出所有的参数:ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!')
函数参数的默认值可以指定为变量,但是其只会在函数定义时执行一次。如下面的实例:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_3.py
# 参数默认值
x = 100
def func_test(a, b=x): # 参数b的默认值会设置为100,后面x改变不会随着变
return a + b
x = 200
print(func_test(200))输出为:
300
参数b在函数定义时,设置了缺省值为x也就是100,后面x改变为200,b的缺省值还是100。
如果参数的缺省值是一个可变数据类型,它会怎么样呢?再看下面的实例:
# 参数默认值为可变数据类型
def list_test(a, b=[]):
print(id(b))
b.append(a)
return b
print(list_test(300))
print(list_test(400))
print(list_test(500, [800]))
print(list_test(600))输出为:
2658215980992
[300]
2658215980992
[300, 400]
2658217265856
[800, 500]
2658215980992
[300, 400, 600]
Process finished with exit code 0
还记得前面讲的引用传递吗?如果参数b缺省值设置为一个list,那么b缺省指向的是一个对象的引用。即使b=[ ],系统也会给它创建一个空的列表对象,并把其引用赋给它。
上面例子还有一个有意思的地方,当我们给b传递了一个实参[800 ],b指向了一个新的对象。之后,我们再次只传递实参a,b采用缺省值,我们发现系统还能记住之前的缺省值。这说明,python函数处理机制中,一旦给参数设置了缺省值,那么这个值会一直存在。
对于这种可变类型作为缺省值的情况,如果你不想让这个缺省值被共享下去,可以将参数的缺省值设置为None。None是一个空对象。如下实例:
# 参数默认值为None
print('set to None'.center(30, '-'))
def list_test(a, b=None):
if b is None:
b = []
print(id(b))
b.append(a)
return b
print(list_test(300))
print(list_test(400))输出为:
---------set to None----------
2176805826496
[300]
2176805826496
[400]
可以看出,当函数判断b是缺省值None时,会执行b=[ ],这将b重新初始化为一个空列表。这样,重复多次调用函数时,b的值不会相互影响。
上面函数中,我们只有两个参数,第一个没有缺省值,第二个有缺省值。如果我们把两个参数交换一下顺序,会出现什么情况呢?
答案是编译时会报错,如下:
File "D:/跟我一起学python/练习/9/9_3.py", line 29
def list_test(b=None, a):
^
SyntaxError: non-default argument follows default argument
错误是:非缺省值的参数不能放在缺省值参数后面。
Python设计这样的规则是有原因的。因为带缺省值的参数,在我们调用函数传递实参时,是可选的。如果我们把这些可选参数放在了必选参数之前,那么python将不知道实参和形参的对应关系。比如一个函数定义为:
def func_test(arg1=None, arg2, arg3=None):
pass
如果我们这样调用这个函数:
func_test(a, b)
python解释器不知道你传递的实参a对应的是arg1,还是对应的arg2,因为arg1是可选的。
所以,python制定了规则:必选参数列表必须放在可选参数列表前面。
这并没有完全解决所有的问题,如果我们有多个可选参数,也会出现问题。比如一个函数定义为:
def func_test(arg1, arg2=None, arg3=None):
pass
如果我们这样调用这个函数:
func_test(a, b)
python解释器会认为b对应的是arg2,而可能我们想传递的是arg3。
这里就得用到下节讲的关键字参数。
2.5、位置参数和关键字参数
事实上,python有两种方式来映射实参和形参:位置参数(position arguments)和关键字参数(keyword arguments)。
- 位置参数
按照实参和形参的位置顺序依次映射。
- 关键字参数
调用函数时,采用“形参=实参”这种键值对的方式指明映射关系。采用关键字参数时,其顺序不需要按照形参定义的顺序。
位置参数和关键字参数是混用的,一次函数调用可以同时使用这两种方式。
对于上节的例子,我们可以采用关键字参数的方式来明确指定arg3:
func_test(a, arg3=b)
这样就不会出现歧义。
我们看一下参数比较多的例子:
def open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True):
pass
这是python的内建函数,用于打开一个文件,它除了第一个参数file是必选,其它都是可选参数。以下的调用方式都是正确的:
f = open('hello.txt')
f = open('hello.txt', 'w')
f = open('hello.txt', encoding='utf-8', newline='\n')
f = open(file='hello.txt', encoding='utf-8', newline='\n')但是下面的调用方式是错误的:
f = open(file='hello.txt', '\n', encoding='utf-8') # error会报错:
File "D:/跟我一起学python/练习/9/9_4.py", line 16
f = open(file='hello.txt', '\n', encoding='utf-8') # error
^
SyntaxError: positional argument follows keyword argument
在传实参时,位置参数必须在关键字参数之前。
Python还提供了*和/方式来强制某些形参只能采用位置参数或者只能采用关键字参数。
def f(pos1, pos2, /, pos_or_kwd, *, kwd1, kwd2):
----------- ---------- ----------
| | |
| Positional or keyword |
| - Keyword only
-- Positional only
/之前的参数只能采用位置参数;
*之后的参数只能采用关键字参数;
两者之间的参数不限制,可以采用任意方式。
看下面的实例:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_3.py
# 位置参数和关键字参数
def my_echo(name, age, /, sex, *, city):
print(name, age, sex, city)
my_echo('xiaowang', 24, 'male', city='Beijing') # ok
my_echo('xiaowang', 24, 'male', 'Beijing') # error
my_echo('xiaowang', age=24, 'male', city='Beijing') # error后面两种调用方法是错误的,会报语法错误。
参数列表中不能出现多个*或者/,如下的定义是错误的:
def my_echo(name, /, age, /, sex, *, city):
print(name, age, sex, city)
2.6、变长参数
有些函数,我们需要它的参数是变长的,也就是说它的参数个数是不确定的。Python提供了实现变长参数的机制。
在定义形参时,采用*或者**来定义变长参数。
*定义的形参,实参必须采用位置参数的方式传递;
**定义的形参,实参必须采用关键字参数的方式传递。
我们来看一个例子:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_5.py
# 变长参数
def goods_attrs(name, **kwargs):
print(f"name: {name}, attributes: {kwargs}")
goods_attrs("跟哥一起学python", pages=300, price=45, version='2.0')
def courses(student, *args):
print(f"name: {student}, 选修课程: {args}")
courses("小王", '高等数学', '计算机科学', '信号与系统', '英语')输出为:
name: 跟哥一起学python, attributes: {'pages': 300, 'price': 45, 'version': '2.0'}
name: 小王, 选修课程: ('高等数学', '计算机科学', '信号与系统', '英语')
可以看到,**kwargs会自动将传入的实参打包为一个字典类型的对象,函数内部可以直接使用这个对象。同理,*args会自动将传入的实参打包为一个元组类型对象,函数内部也可以直接使用。
在函数定义时,**kwargs后面不能再有其它形参,而*args后面可以其它形参,但是必须采用关键字参数的方式来传递实参。这一点也比较好理解,因为*args和**kwargs都是可变长参数,其参数个数是不确定的,如果后面有其它形参,那么必须要能区分开。因为*args要求必须是位置参数,所以在它后面的形参可以用关键字参数予以区分。但是**kwargs本身就是关键字参数,那么它后面无论怎么传递参数都无法区分。
大家想过一个问题吗?**kwargs采用的是关键字参数,那么如果关键字和前面定义的其它参数名重复了,怎么办呢?比如前面的例子,我们这样调用就会出错:
goods_attrs("跟哥一起学python", name="hello", pages=300, price=45, version='2.0')输出为:
Traceback (most recent call last):
File "D:/跟我一起学python/练习/9/9_5.py", line 15, in <module>
goods_attrs("跟哥一起学python", name="hello", pages=300, price=45, version='2.0')
TypeError: goods_attrs() got multiple values for argument 'name'
因为无论如何,python都会认为name是我们定义的第一个形参,这样调用它会认为是参数重复了。
为了解决这个问题,上一节我们讲到的/语法就可以派上用场了,我们可以限定那么参数必须采用位置参数的方式传递实参,这样系统就能区分开。
def goods_attrs(name, /, **kwargs):
print(f"name: {name}, attributes: {kwargs}")
goods_attrs("跟哥一起学python", name="hello", pages=300, price=45, version='2.0')输出为:
name: 跟哥一起学python, attributes: {'name': 'hello', 'pages': 300, 'price': 45, 'version': '2.0'}
变长参数的极端用法,是全部参数都是变长,比如我们定义一个函数,用于计算所有入参的平均数:
def calc_avrg(*args):
total = 0
for item in args:
total += item
else:
if len(args) == 0:
return 0
else:
return total / len(args)
print("average is: %.2f" % (calc_avrg()))
print("average is: %.2f" % (calc_avrg(1, 2, 100, 29, 39, 19, 30, 29)))输出为:
average is: 0.00
average is: 31.12
2.7、解包参数列表
*和**同样可以用于在传递实参时解包参数列表。
比如上一节的例子,我们也可以这样调用:
# 解包参数列表
courses("小王", *('高等数学', '计算机科学', '信号与系统', '英语'))
goods_attrs("跟哥一起学python", **{'name':"hello", 'pages':300, 'price':45, 'version':'2.0'})
*是用于将元组解包为一个一个成员;
**是用于将字典解包为一个一个键值对。
它和我们上一节讲的变长参数的过程刚好相反。
但是,需要注意的是,它们用于解包,不一定非得是变长参数。
def func_add(x, y):
return x + y
print(func_add(1, 5)) # 直接赋值
tmp = (1, 5)
print(func_add(*tmp)) # 使用*解包
tmp_dict = {'y': 5, 'x': 1}
print(func_add(**tmp_dict)) # 使用**解包
3、lambda
有时候,某些函数会非常简单,简单得我们都懒得给它起名字,这种没有名字的函数叫“匿名函数”。Python中采用lambda语法来定义匿名函数,其语法如下:
lambda [arg1 [,arg2,.....argn]]:expression
首先是保留字lambda,后面跟0个或者多个参数列表,随后是冒号:,冒号后面跟一个表达式。
注意,expression只能是一个表达式,这个表达式的值会被缺省通过return返回出去。所以,lambda无法写复杂逻辑,它非常简单。
Lambda通常用于作为一些函数的实参,比如下面官方手册的一个例子:
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_6.py
# lambda函数
list_1 = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
list_1.sort(key=lambda item: item[1])
print(list_1)输出为:
[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
参数key是一个函数类型,这个函数需要返回一个用于排序的值。我们定义了一个lambda函数,它返回了成员元组的第二个值。
我们让这种函数匿名,就是因为它们太简单了,并且没有太大的复用价值。毕竟起名有时候也挺头痛的。但是,这并不意味着匿名函数就不能复用,看看下面的例子:
# lambda函数
list_1 = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
list_2 = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
key_func = lambda item: item[1]
list_1.sort(key=key_func)
list_2.sort(key=key_func)
print(list_1)
print(list_2)这个例子中,我们定义了一个变量key_func,这个变量指向了lambda函数(万物皆对象,函数也是对象)。这个变量可以重复使用的,lambda函数被变相复用了。
这种使用方法,是被python官方所鄙视的。因为你既然都定义变量了,为啥不直接定义一个def的函数呢?这种情况下就不要用lambda了。
在很多公司的编程规范中,是不建议程序员使用或者大量使用lambda的,因为它会影响程序的可读性。下面的代码你是否能一下子看明白是什么意思:
lower =(lambdax, y: x ifx < y elsey)
lambda的功能可以完全使用def函数替代。我们使用lambda时,一定要保证其表达式是非常简单明确且易读的,否则就老老实实采用def函数的方式吧。
4、嵌套和闭包
函数是可以嵌套的,包括lambda也是可以嵌套的。
# author: Tiger, 关注公众号“跟哥一起学python”,ID:tiger-python
# file: ./9/9_7.py
# 函数嵌套
def calc_avrg(*args):
def calc_sum(*args1):
total = 0
for item in args1:
total += item
else:
return total
tmp_total = calc_sum(*args)
return tmp_total / len(args) if len(args) > 0 else 0
list_1 = [100, 200, 3, 4, 55]
print(calc_avrg(*list_1))
# lambda嵌套
y = lambda N: (lambda x: N * x)
func = y(2)
print(func(2)) # 输出 4上面第一个函数calc_avrg的内部又定义了一个函数calc_sum,形成了嵌套关系。在calc_avrg之外是不能调用calc_sum的,也就是说calc_sum的作用域仅限于calc_avrg内部。
第二个函数是一个lambda函数,它的表达式也是一个lambda函数,这就形成了函数嵌套关系。有趣的是,它返回的是一个lambda函数对象。这样,我们在外部是可以调用内部嵌套的lambda函数。这种机制我们称之为“闭包(closure)”。
闭包的概念理解起来会稍显困难。我们对前面的def函数稍作改造:
# 函数嵌套
def calc_avrg_1(*args_outer):
tmp_total = 0
def calc_avrg_1_inner(*args):
nonlocal tmp_total # 这里的tmp_total采用外层变量
for item in args:
tmp_total += item
else:
return tmp_total / len(args) if len(args) > 0 else 0
return calc_avrg_1_inner(*args_outer)
list_1 = [100, 200, 3, 4, 55]
print(calc_avrg_1(*list_1))
print(calc_avrg_1(*list_1))
print(calc_avrg_1(*list_1))输出为:
72.4
72.4
72.4
我们在外层函数定义了变量tmp_total,内层函数也使用该变量。我们调用了3次calc_avrg,最后的结果都是一样的72.4。你肯定会说,这不废话吗?同一个函数,相同的实参,输出的结果肯定一样啊!
但是大家想过没有,这三次调用同一个函数,为什么相互之间互不影响呢?原因在于,我们每次调用函数时,系统会给这个函数分配独立的上下文运行环境,这里面保存了本次调用的各种参数、临时变量等等。所以,我们每次调用除了代码段是一样的,运行环境都是独立的。
“闭包”机制改变了这一切!
我们再对这个函数进行改造,如下:
def calc_avrg():
tmp_total = 0
def calc_avrg_inner(*args):
nonlocal tmp_total # 这里的tmp_total采用外层变量
for item in args:
tmp_total += item
else:
return tmp_total / len(args) if len(args) > 0 else 0
return calc_avrg_inner
list_1 = [100, 200, 3, 4, 55]
func_calc = calc_avrg()
print(func_calc(*list_1))
print(func_calc(*list_1))
print(func_calc(*list_1))输出为:
72.4
144.8
217.2
我们把这个函数改成了闭包的形式,calc_avrg()返回的是其内部函数calc_avrg_inner的对象引用。这样,外部可以直接调用calc_avrg_inner。我们看到,调用三次,每次的结果都不一样,就像tmp_total被共享了一样。没错,形成闭包之后,其临时变量会被共享,每次函数调用之间会相互影响。
形成闭包需要有两个条件:
- 外部引用了内部嵌套函数对象;
- 内部函数引用了外层变量。
形成闭包之后,一个函数实例func_calc会携带一个属性func_calc.__closure__,这个属性就是闭包属性,它里面存储了外层变量的引用,并且在实例化之后不能被修改。
所以,我们看到tmp_total的值在多次调用过程中被共享了。如果我们多创建几个函数实例,它们相互之间是不会影响的。
list_1 = [100, 200, 3, 4, 55]
func_calc = calc_avrg()
print(func_calc(*list_1))
print(func_calc(*list_1))
func_calc2 = calc_avrg()
print(func_calc2(*list_1))输出为:
72.4
144.8
72.4
func_calc和func_calc2创建了两个函数实例,它们之间的闭包属性是独立的,互不影响。我们可以断点查看闭包属性,如下:
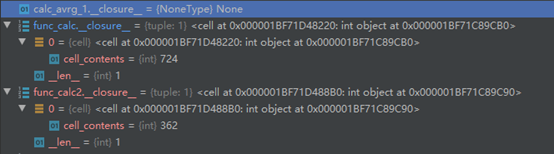
cell_contents里面存的就是闭包函数引用的变量,每个实例会创建一个独立的,并且在每次调用共享。
对于没有闭包的函数calc_avrg_1,它的闭包属性为空None。
这就是闭包的概念,有点不好理解。闭包有啥用呢?其实我们后面要讲到的装饰器Decorator就是用到了闭包原理。
本文有视频讲解,视频和实例源码下载方式:点击->我的主页,查看个人简介。
我尽量坚持每日更新一节。
更多python教程,请查看我的专栏《0基础学python视频教程》