1.源码流程





















2.总结
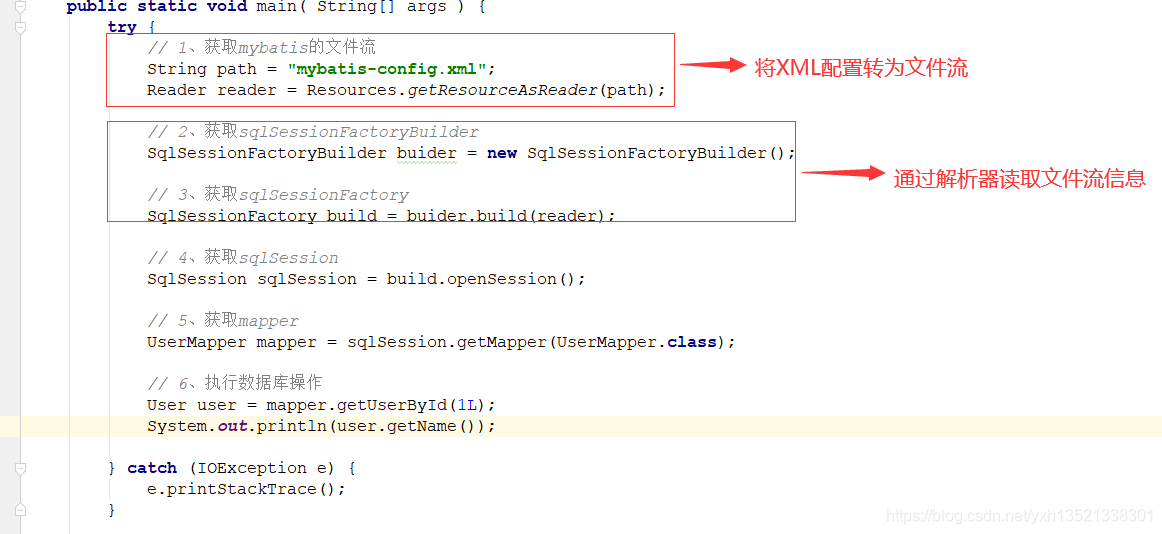
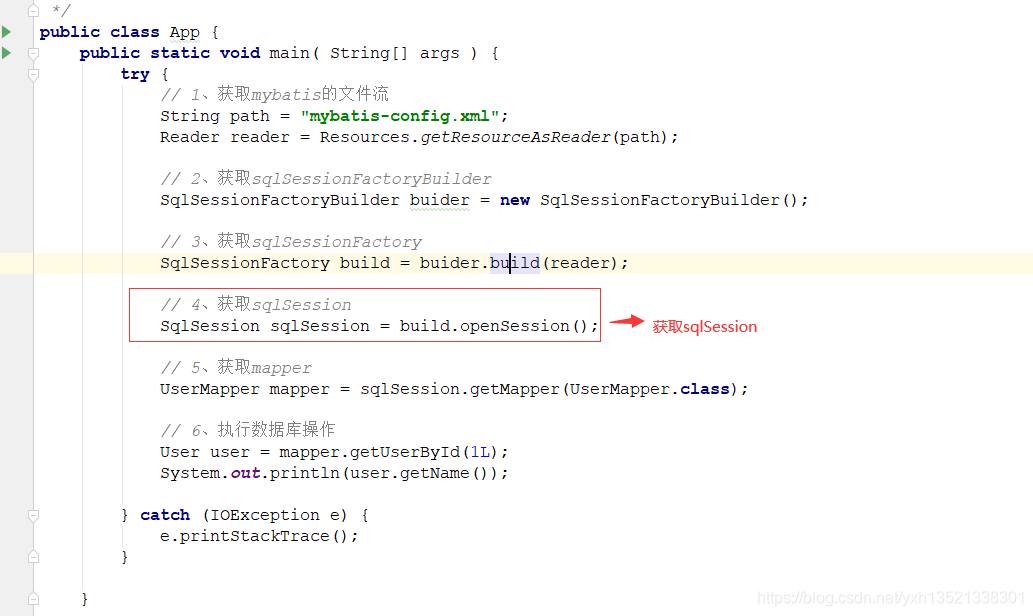
1.mybatis通过Resources.getResourceAsReader将配置文件加载至IO流中
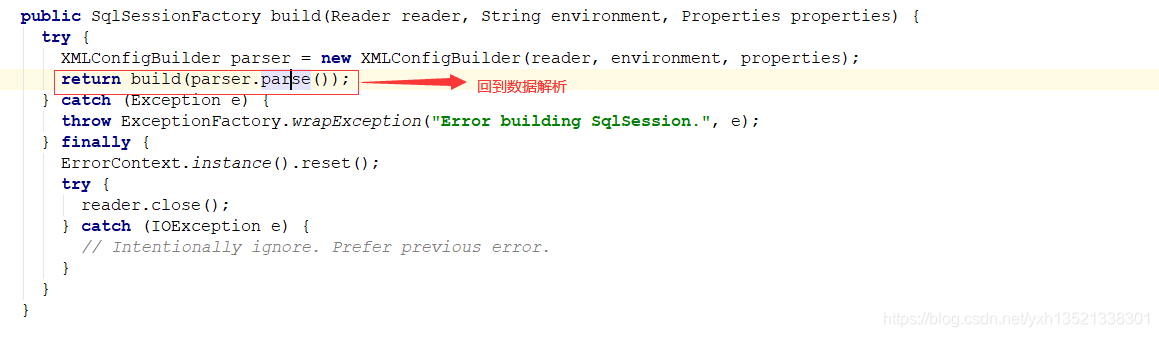
2.通过SqlSessionFactoryBuilder.build(reader)将IO流解析
---config解析的过程start---
3.底层是一个XMLConfigBuilder去解析XML配置
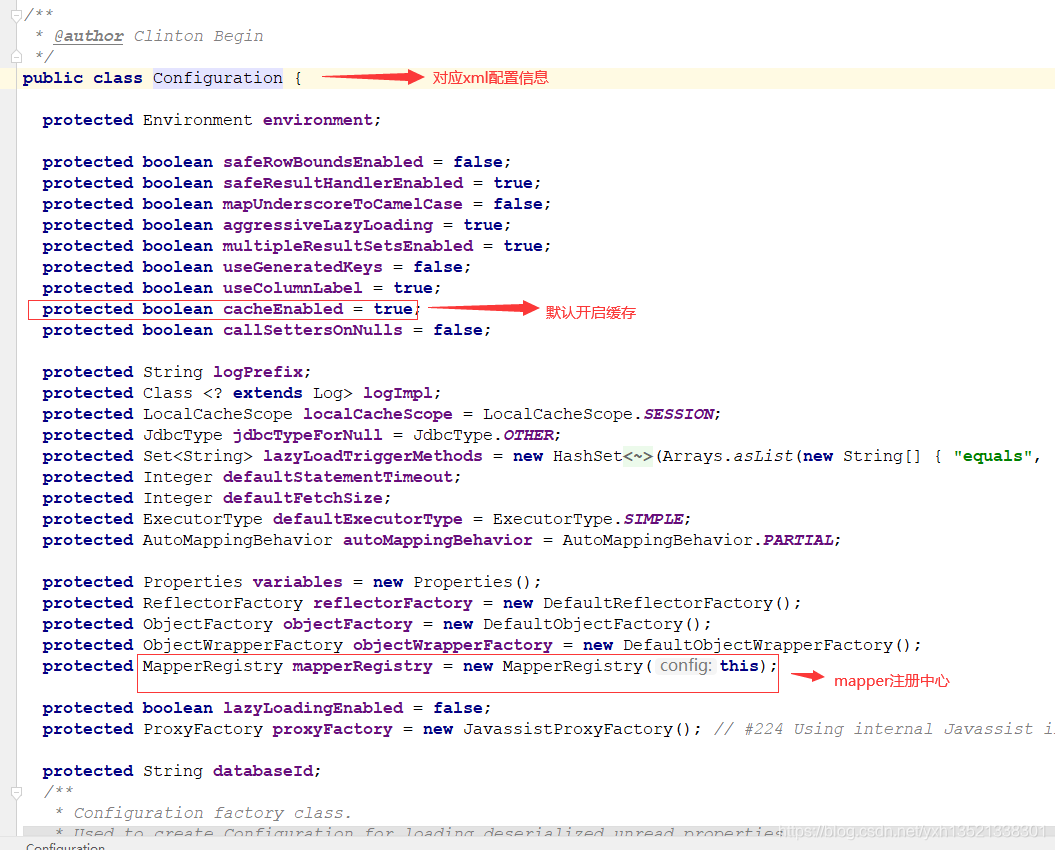
4.XMLConfigBuilder的parseConfiguration会将XML的configuration节点解析为configuration,其中封装了配置文件的各种信息
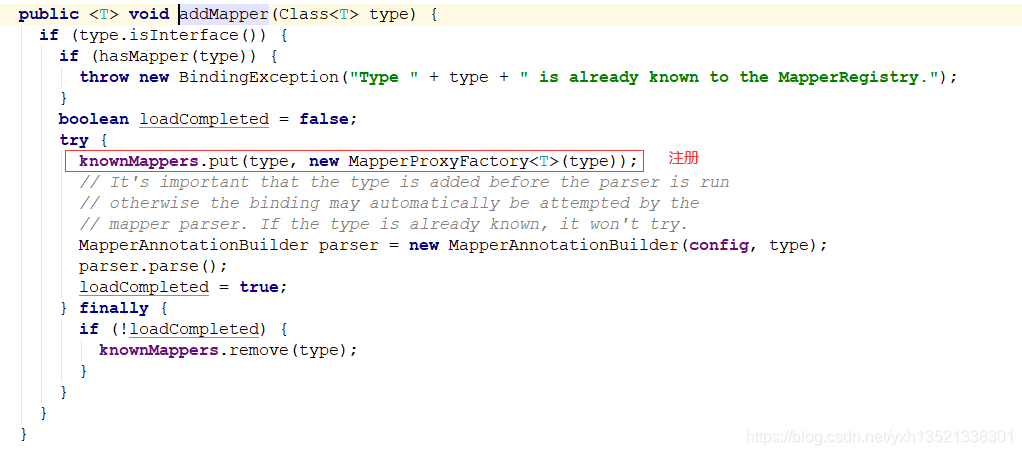
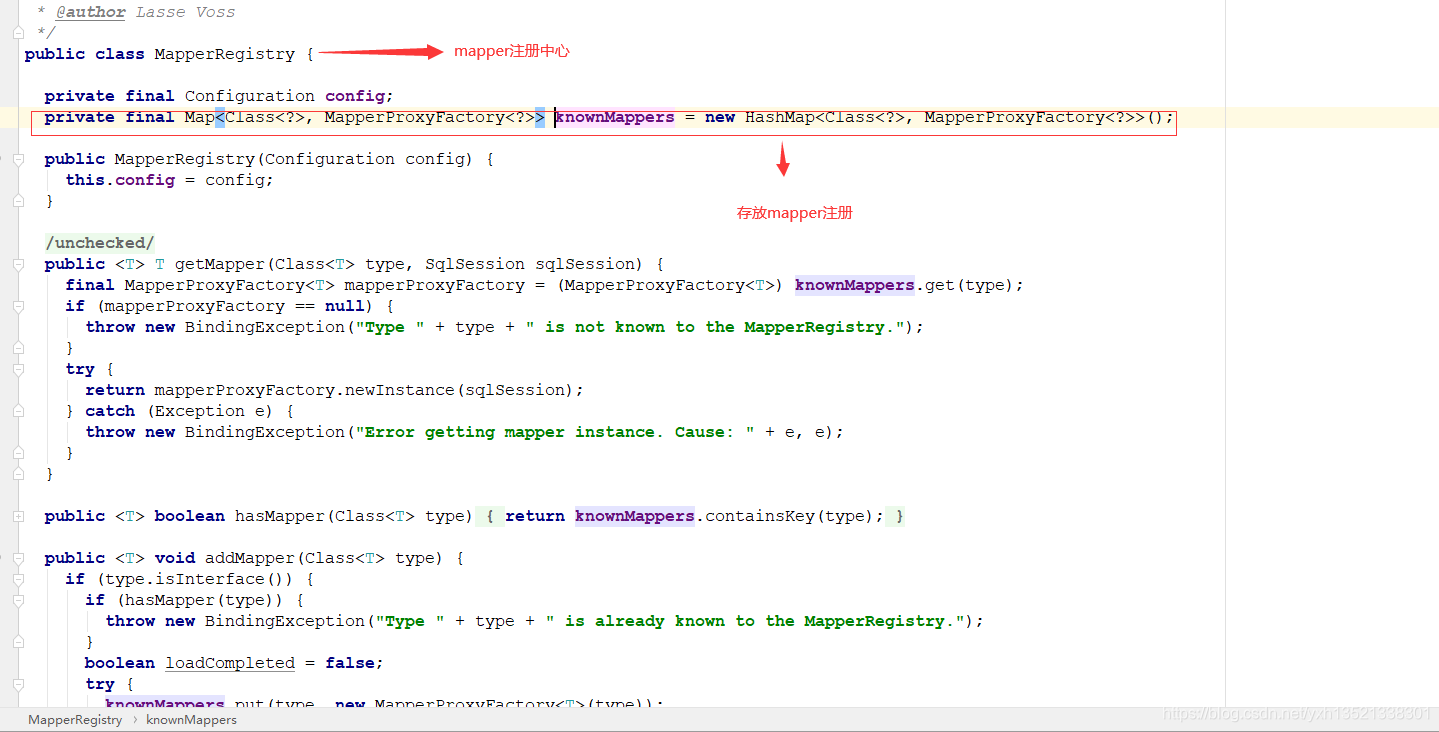
5.其中mapperElement会将所有指定的mapper进行注册,放入mapperRegistry中
6.mapperRegistry中的属性
Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<Class<?>, MapperProxyFactory<?>>()
存放mapper的类型及其对应的代理工厂类
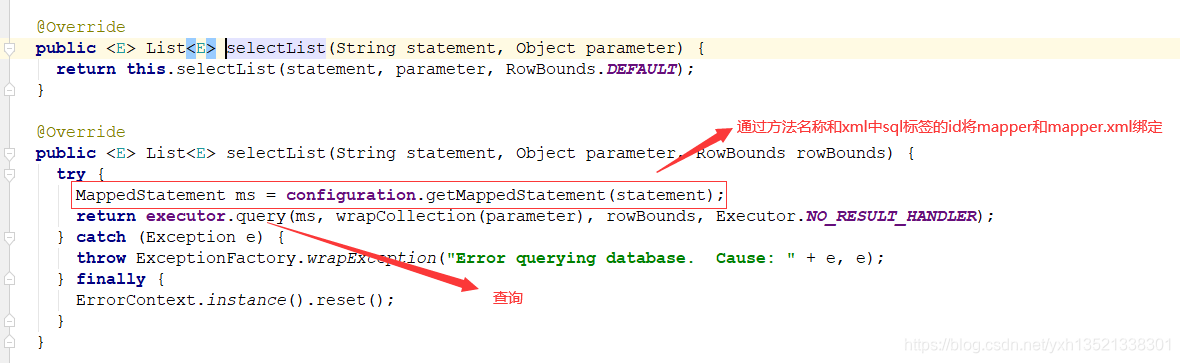
7.根据mapper.java方法的名称和mapper.xml中sql标签中的id映射,将两者做封装和绑定,生成MappedStatment存放在Map<String, MappedStatement> mappedStatements
---config解析的过程end---
8.将解析后的config放入new DefaultSqlSessionFactory(config)
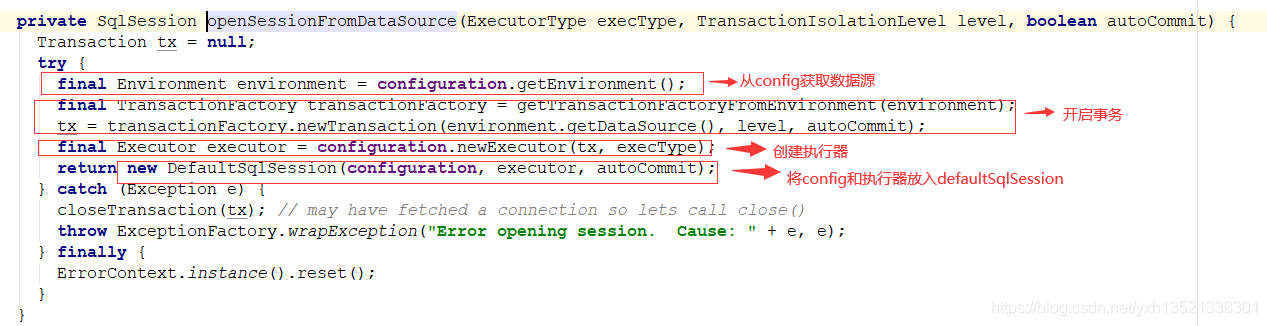
9.sqlSessionFactory.openSession()底层开启事务,创建缓存执行器,生成sqlsession
---mapper的代理类start---
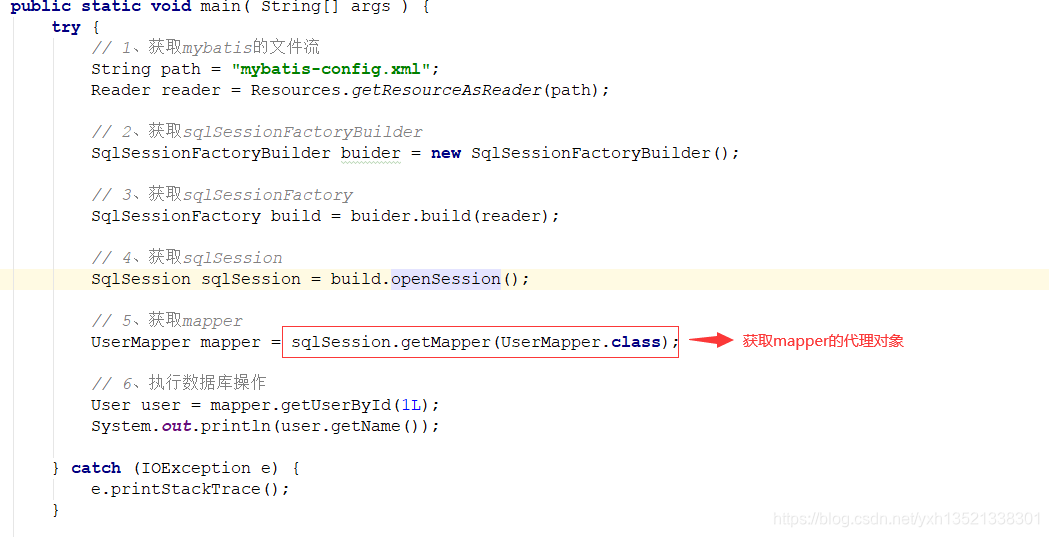
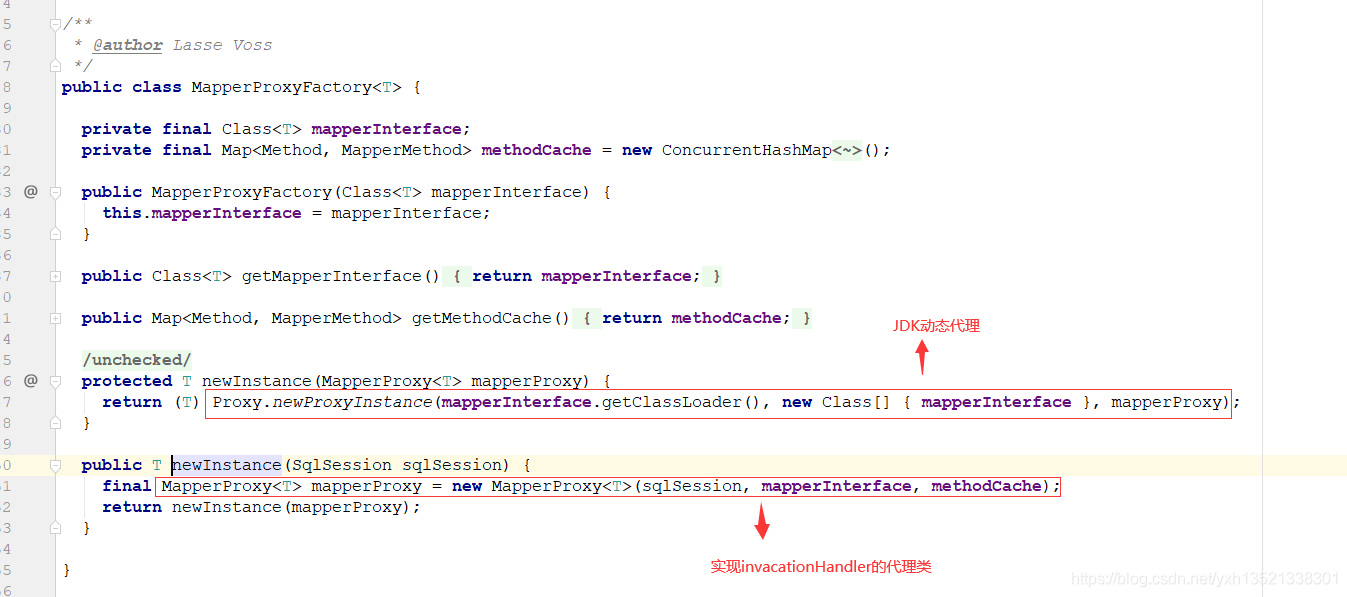
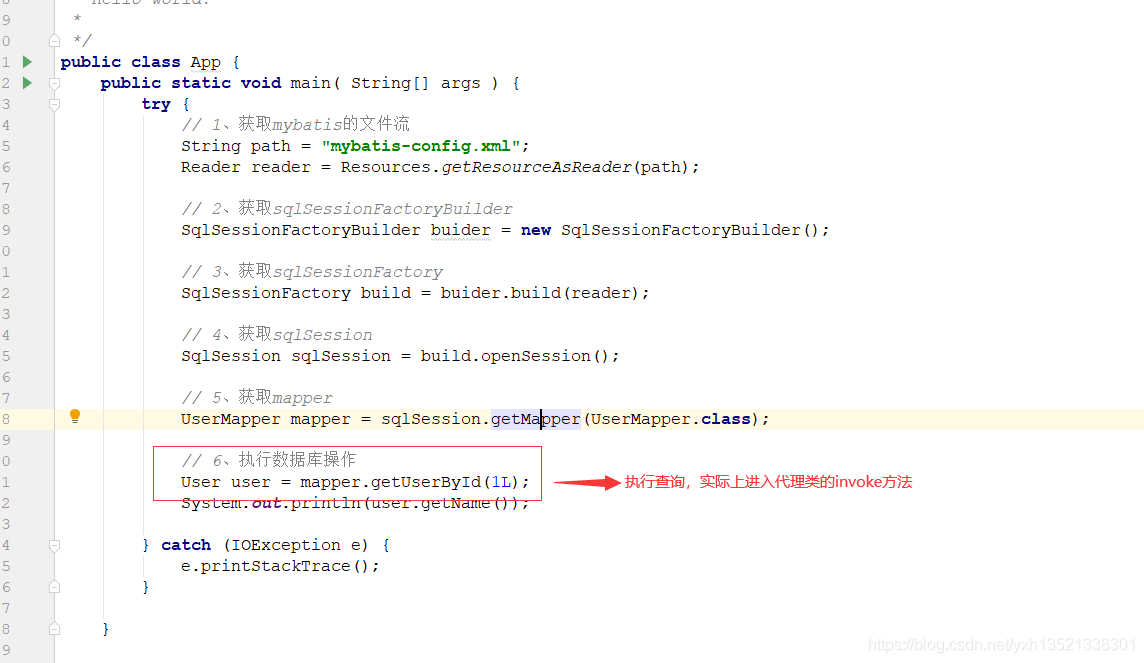
10.sqlSession.getMapper(mapper.class)获取Mapper,底层是去mapperRegistry获取mapper的代理工厂
11.通过JDK动态代理生成mapper的代理类
---mapper的代理类end---
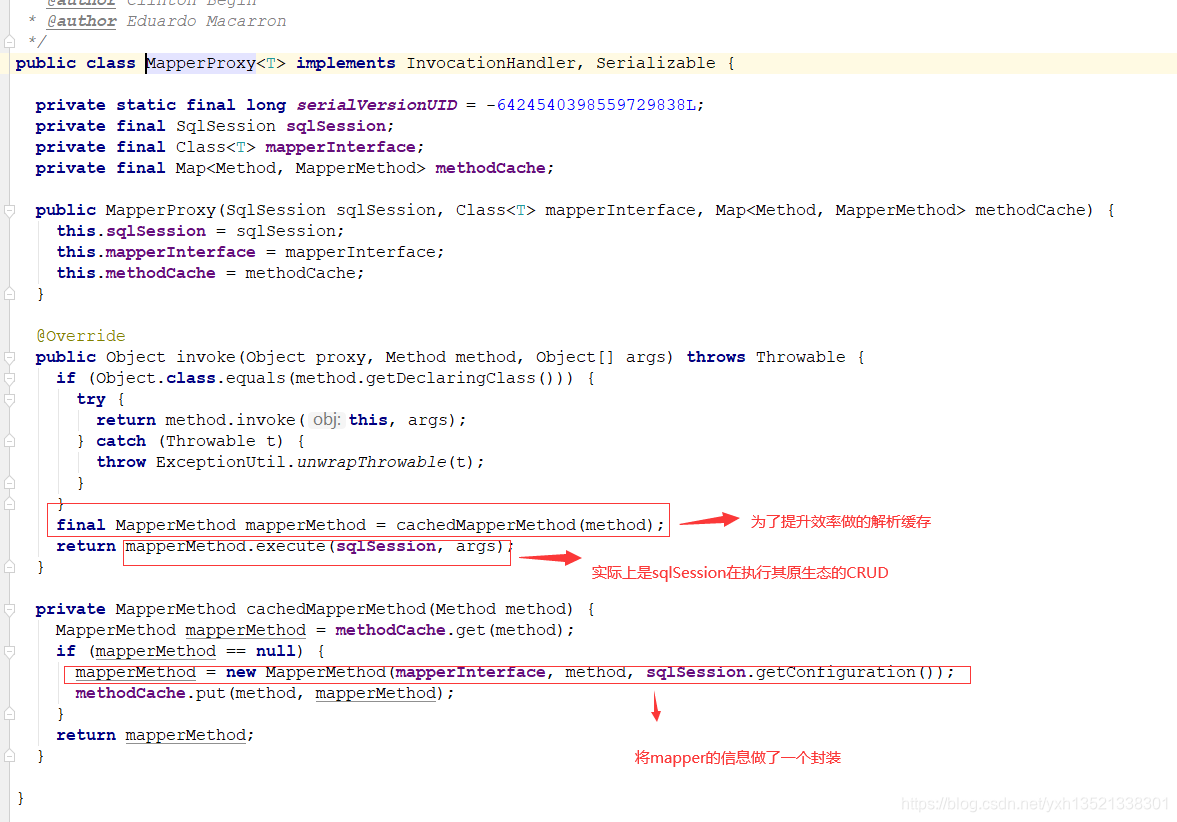
12.执行mapper的查询方法,实则进入代理类的invoke方法,封装查询方法的信息,交由sqlsession去执行查询
13.根据查询的方法在configuration的mappedStatements找到对应的mappedStatement数据
14.根据查询参数、分页信息、环境节点、sql等信息做维度按照指定的约定生成缓存的key
---二级缓存start---
15.根据key去二级缓存中查找,二级缓存会根据MappedStatment中sql标签上cahce的类型找到对应的缓存介质缓存数据map
16.去缓存数据中查询,有的话返回,没有的话,将key放入未中标的set集合中,再从下级数据来源查找(一级缓存、数据库),
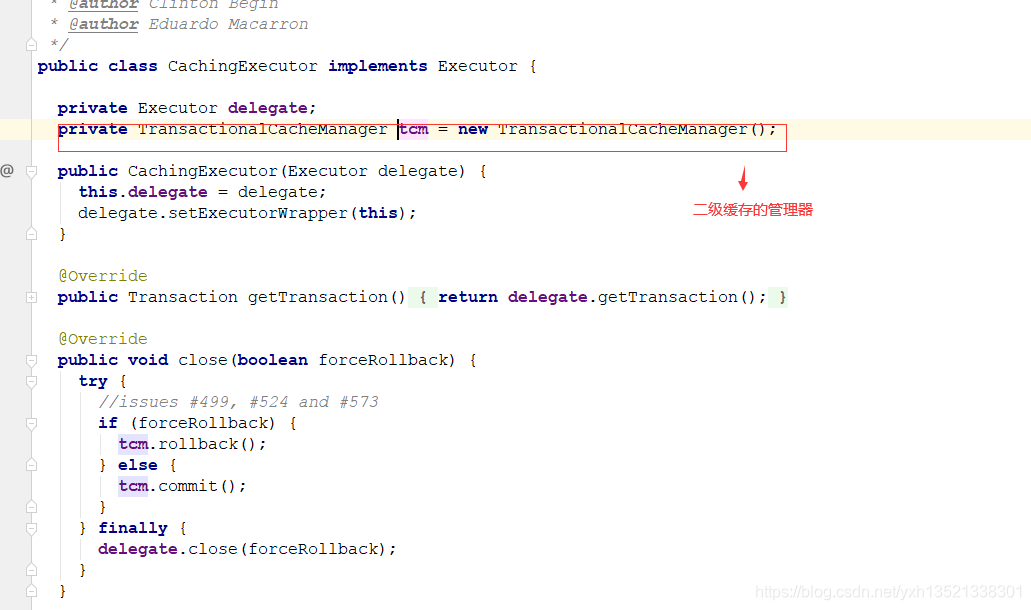
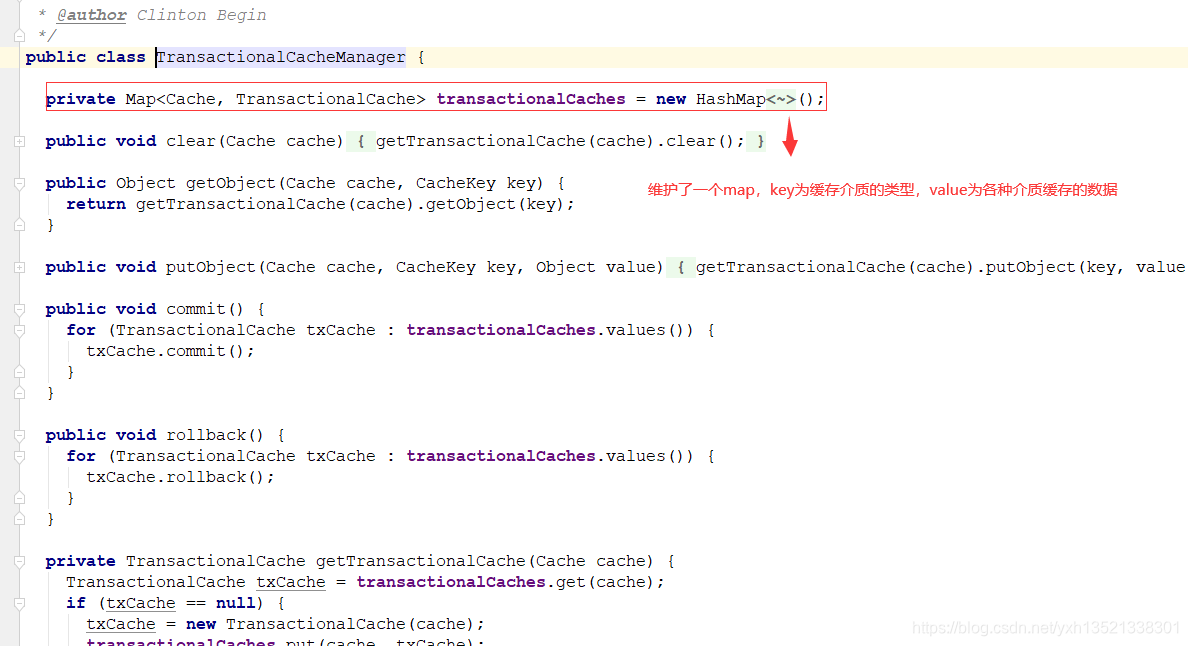
将查到的结果集再放入此缓存介质的map中,当sqlsession关闭时,将未中标的key在map中的数据提交至TransactionalCacheManager,
TransactionalCacheManager将数据提交至二级缓存中进行缓存
---二级缓存end---
---一级缓存start---
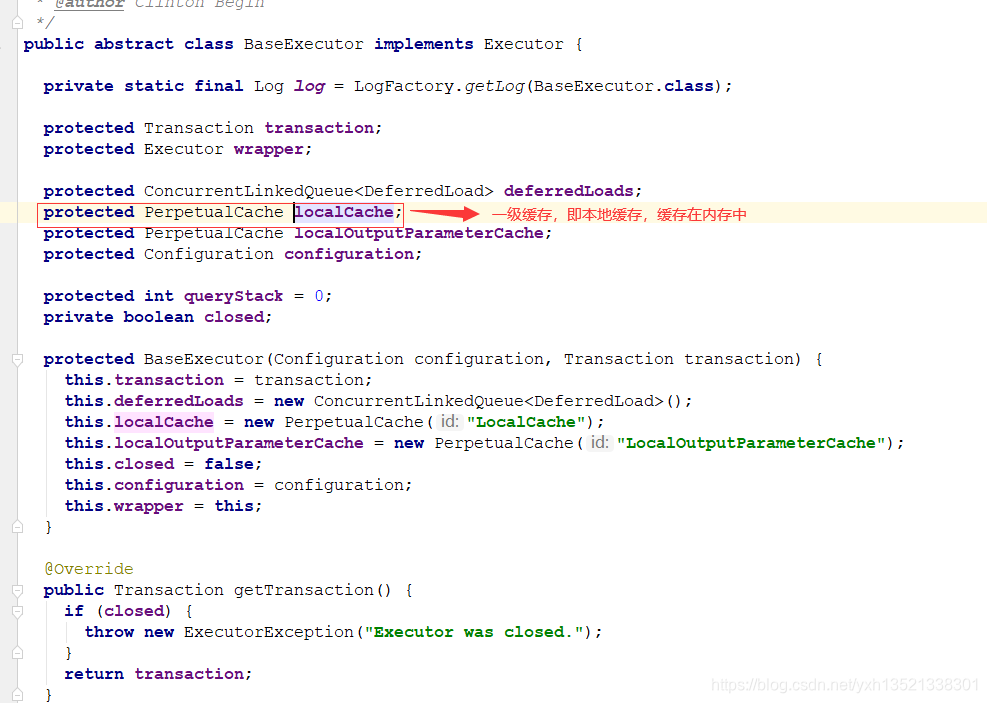
17.二级缓存没有数据或者二级缓存未开启时,查询一级缓存PerpetualCache localCache,底层维护了一个Map<Object, Object> cache = new HashMap<Object, Object>()
18.一级缓存没有则查询数据库,将结果同步至一级缓存
---一级缓存end---
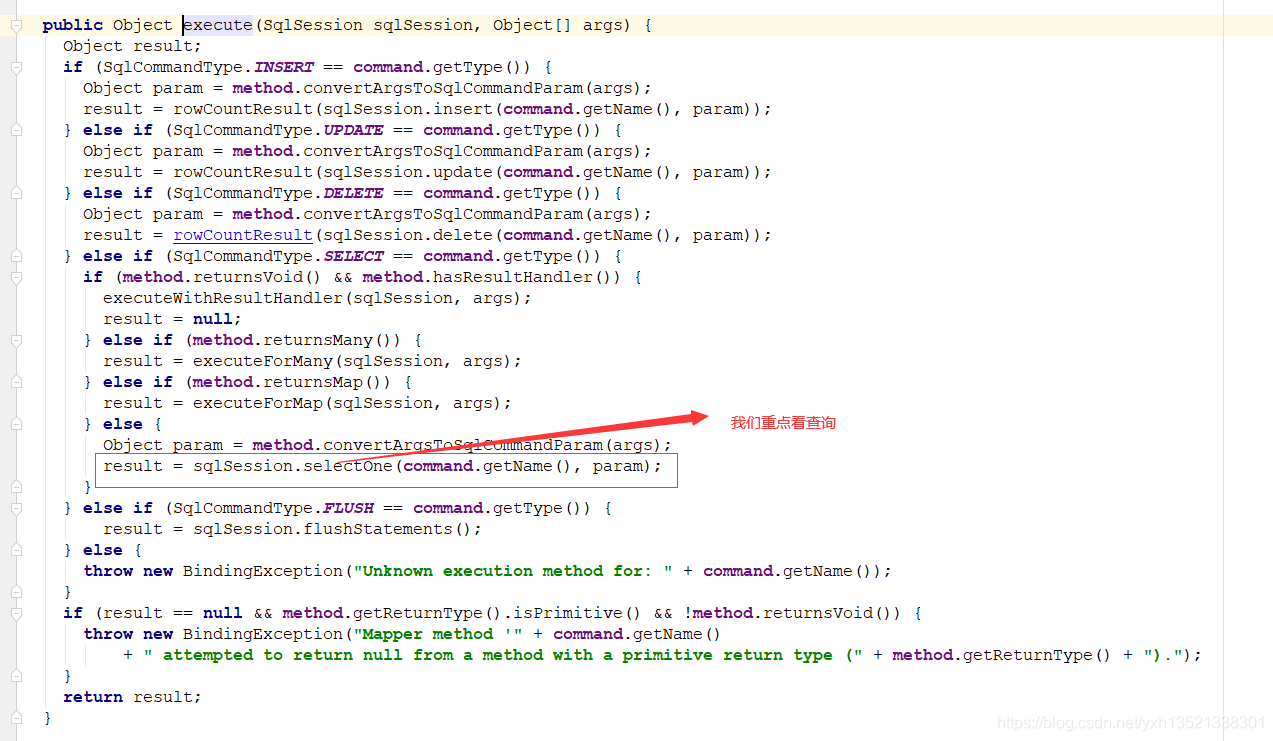
19.查询数据库时会生成路由的StatementHandler,根据策略去找寻对应的StatementHandler
20.之后就是封装了原生态jdbc的查询3.常见问题
1.一级缓存 存在的问题
底层是一个hashMap,所以会有非线程安全和内存溢出的隐患
一级缓存是mapper级别的,故会有分布式集群(多个mybatis多个一级缓存)
2.如何禁止一级缓存
开启二级缓存
手动清除一级缓存(一级缓存在执行增删改操作都会被清空)
sql加随机数
3.二级缓存是缓存在物理介质中的,一级缓存是缓存在内存中
4.二级缓存是session级别的,即同session的mapper之间缓存数据共享
5.TransactionalCacheManager只是集中管理mybatis的各种缓存介质
