转载:https://zhuanlan.zhihu.com/p/22166831 作者:Javen Fang
10 个现代的软件过度设计错误(完整版)
评论:的确是些现在软件开发中比较流行的观念,很容易被误用,仔细看下来有所启发。作者在软件开发中有大量的实践经验。有部分的主要意思是,不要太照搬设计模式,不要过于僵化,应该事实求事地看待每个项目。
没有事情肯定会一直增长:星星之间的距离,可见宇宙的熵,他妈的业务需求。有些文章在说「不要过度设计」但不说 Why or How。以下谈 10 个典型的例子。
重要提示:以下问题点中「不要滥用泛型」被误解为「完全不要使用泛型」,「不要创建不必要的封装」被误解为「完全不要创建封装」等。我只是讨论过度设计,不是在主张 cowboy coding.
1. 工程比业务聪明
工程师认为我们是全世界最聪明的人,因为我们在创造东西。这第一个错误通常导致我们「过度设计」。但是如果我们计划 100 件事情,业务总是会提出第 101 件我们从未想过的事情;如果我们解决了 1000 个问题,他们会抛回 10,000 个问题。我们认为我们一切尽在掌握 - 但是,我们对该往去向何方却没有想法。
在我 15 年的编程生涯中,我从未见过一次业务在需求上「收敛」的。他们总是发散。这只是业务的本来面目,这不是业务人员的错。
顺我者昌。(业务总是赢的。)
提示:如果你没有时间看完整篇文章,那么看了这一条就够了。
2. 重用业务功能
当业务抛出越来越多的功能需求时(这是预期内的),我们总是这样反应(如图):
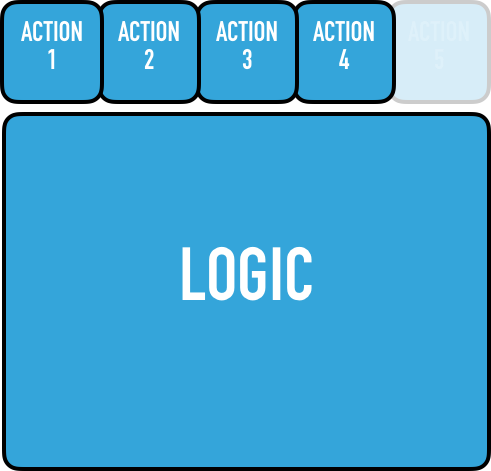
我们尝试尽可能分类、泛化逻辑。这是为什么大部分 MVC 架构到最后要么是「胖模型」(Fat Models),要么是「胖控制器」(Fat Controllers)。但是正如我们已经看到的,业务需求只是发散,从来不会收敛。
反而,我们应该这样来响应(如图):
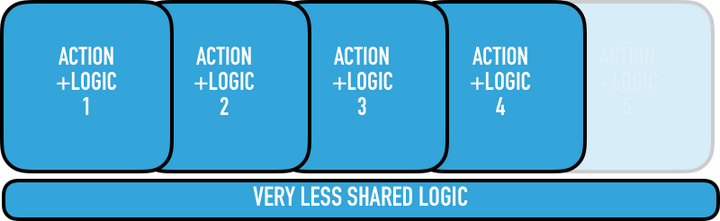
在自然的系统中,共享的逻辑与抽象最后趋向稳定。他们要么保持平稳,要么随着功能范围的扩大而相应下降。当相反的情况发生时,这将创建「尾大不掉」(Too big to fail) 的系统(趋向于让人恐惧的重写)。
例如:我们为上一个客户创建了一个用户属性系统。因为我们假设每个事情都会类似,所以我们从一个有共享功能的 CRUD 控制器开始。但最后结果是 13 个不同的注册流程 - 初始的社区连接,首次进入时的长注册表单,小一些的可编辑的页面块,完全不同的用户属性查看页面,等等 - 最后发现,共享一些元素没有什么意义。类似地,一个「订单页面」与「订单编辑」流程最后内在地就与实际的「订单」流程不同。
应在横向分割业务功能前,尝试纵向分割。这在所有的情况都适用 - 独立的服务,有主分支的服务,语言独立模块,等等。再者要考虑使用得从一种方式切换到另外一种方式容易。否则当要修改系统的部分时系统变得越来越复杂。
分离行为比强行合并好。
提示:从代码里选取一个有外部视角的行为(节点/页面/任务等),看看要理解如何运作的要切换多少上下文。
3. 处处泛型。
(有时候与上面一条一起出来,但在不同的项目中又会单独出来)。
- 想要连接数据库?写个通用的适配器。
- 查询那个数据库?通用的查询。
- 构造查询参数?通用的构造器。
- 匹配返回数据?通用的数据匹配器。
- 处理用户请求?通用的请求。
- 执行整个这些事情?通用的执行器。
- 等等。
有时候工程师得意忘形。我们不是尝试去解决具体的业务问题,而是浪费时间于找到炫酷的抽象。答案是如此的简单。

设计总是努力赶上改变的真实的需求。因为即使我们奇迹般地找到了炫酷的抽象,它也往往伴随着终止日期,因为第 1 条 - 顺我者昌。今天判断一个设计是否有最好的质量,是要看其非故意而为之的程度。(译者注:这里有点坳,意思大概是「好的设计就是没有设计」)。有篇有趣的文章:要写容易被删除不容易被扩展的代码.
「复制」比错误的「抽象」好。
相反地,为了正确地「抽象」,「复制」有时候是有必要的。因为只有当你看到系统里有部分共享类似的代码时,一个更好的共享的抽象才会出现。抽象的质量在于最弱的连接。复制暴露一些使用场景,使得连接更清晰。
提示:跨服务共享的抽象有时候演变为「微服务」,最终作为分布式系统中的一部分。
4. 浅层的封装。
有个实践是每个外部库在使用前都封装一把。不幸的是大部分我们写的封装是浅层次的。我们在发布功能与写一个好的封装之间做选择。所以,我们的封装非常紧密地与底层库绑定(有时候是 1:1 的映射,或者以 10 倍的工作量做了原始库里 1/10 的功能)。如果我们以后改变了底层库,这个封装每个使用的地方也需要改变。有时候我们也把业务逻辑混杂在封装里,使得它既不是一个好的封装,也不是一个好的业务模块,而是类似于之间的粘合层。
现在是 2016 年。外部库与客户端飞速地提升。OSS 库非常棒。他们由牛B 的人投入专门的时间编写,具有高质量与测试完备的代码库。大部分具有清晰的、可测试的、可测量的 API,允许我们遵循标准的范式:初始化,测量,实现。
封装应该是例外,不应是常态。不要为了封装而去封装优质的库。
5. 工具化地提高质量。
不假思索地运用质量概念(例如把所有变量前边加上 private final,为所有的类都加上接口)不会使代码更好。
看下 Enterprise FizzBuzz 这个项目,它有极大的代码量。在最小粒度上每个类遵循 SOLID 原则,使用了所有类型的伟大的设计模式(工厂,构造者,策略,等)与代码技术(泛型,枚举,等)。从 CQM 工具来盾,它的代码质量很高。
但如果我们往回一步看,它只是打印输出「Fizz Buzz」。
总是回看一步,看看微观图像。
相反地,自动 CQM 工具在追踪测试覆盖率方面很好用,但不能告诉你我们的测试对象是否正确。性能测试工具可以跟踪性能,但不能告诉你是并行还是串行。只有人才能看到大的图像(宏观视野)。
这把我们带向「三明治层次」。
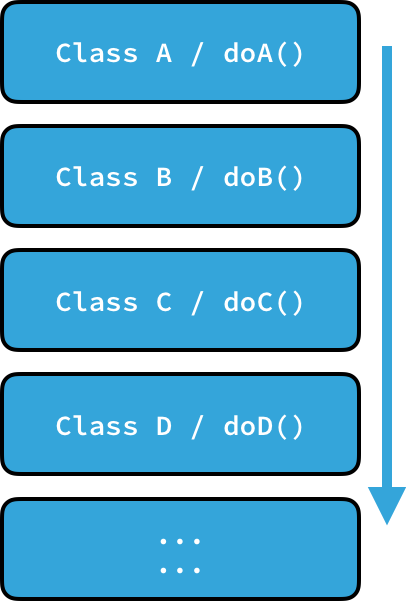
让我们简化下,紧密地约束行为,把它分解为 10/20 个三明治层,这样没有整体的情况下任何一层都没有意义。因为我们想要应用「可测试的代码」的概念,或者「单一责任原则 」,或者其他。
在过去,这被通过链式继承实现。A 继承 B 继承 C 继承 D,如此继续。
现在,大家做几乎同样的事情,为了遵循 SOLID,每个类都有接口与实现,注入到下一层次。
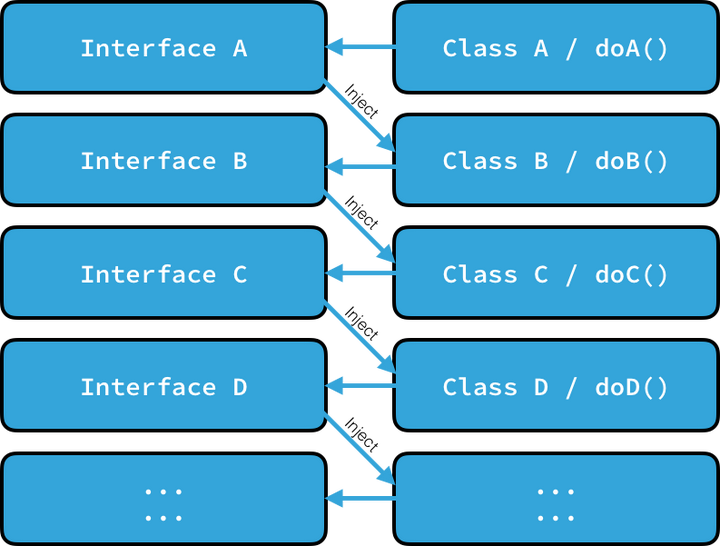
像 SOLID 这个概念是为了反对滥用继承与其他 OOP 概念。大部分工程师没有搞清楚这些概念从哪里来,如何出现,只是照单全收。
概念在思维上应该有消化,不要工具化地盲目应用。
学习一个不同的语言,尝试以这个另外的思维模式去做事情。这样会成为一个更好的开发者。新瓶装旧酒在概念上没有效果。我们从来不必借口应用一个概念而弄乱一个清晰的设计。
6. 过度适配症。
发现了泛型。那现在一个简单的 "HelloWorldPrinter" 变成了 “HelloWorldPrinter<String,Writer>”.
很明显一个问题只会有特定的数据类型时,或者普通的类型签名足够时,不要使用泛型。
发现了策略模式。每个条件语句现在都是一个策略。
为什么?
元编程很酷,那我哪里都用用。
描述为什么?
枚举/扩展方法/Traits/各种炫酷的技术,我们到处使用。
这是错的。
7. N 种特性。
- 可配置性。
- 安全性。
- 可扩展性。
- 可维护性。
- 可继承性。
- …
模糊。没有争议。很难反驳。FUD.
例一:我们来打造一个表单具有扩展性的内容管理系统吧(CMS)。业务人员可以很容易地增加字段。
结果:业务人员从来使用过这个功能。当他们需要时,他们会让一个开发人员坐在旁边来加上。也许我们需要的只是一个简单的程序员指南,在有限的时间里加一个字段,而不是一个可点击的界面。(有专门的界面与增加字段的灵活性,系统复杂度就大太多了)。
例二:为了容易「配置」我们来设计一个数据库层,在一个魔法文件里变更就能切换数据库。
结果:过去 10 年,我只看到一个业务为了完全切换数据库而做出认真的努力。并且,真要切换数据库时,那个「魔法文件」不起作用。需要很多的运维工作。功能上不兼容,有很大的差别。客户要求我们迁移一半的模型到新的 NoSQL 数据库里。我们打脸了 - 我们的魔法切换是一个点的改变,但实际上是大范围横切。
在今天的世界,再无法为文档/KV数据库(比如:Redis/CouchDB/DynamoDB 等)设计一个单独的配置层了,即使像 Postgres/HSQLDB/SQLite 这些 SQL 数据库互相兼容也不行。要不你的数据层完全兼容(与功能交付做斗争),要不承认数据库是你的解决方案的一部分(例如 Postgress 的 geo/json 特性),抛弃可配置特性。
你的工作栈像代码一样,是解决方案的一部分。当你放弃各种特性的要求时,更好的方案开始出现。例如,你能纵向打散数据访问层(每个行为都有小的 DAO),而不是横向(魔法可配置层),或者基于不同的功能做微服务的模式,选择不同的数据库。
例三:我们为企业客户开发了一个 OAuth 系统。对内部管理人员,我们被要求使用 Google OAuth 二次验证。考虑安全性。如果有人破解了我们的 OAuth,商务不希望他们能够访问到管理密钥。Google OAuth 更安全,谁能否认「更安全」在哪呢?
结果:如果有人真想破解我们的系统,他不必通过 OAuth 层。我们有很多易受攻击的系统部署,例如,他们只需要提升特权。所以,相对于正确提升基础安全,所有支持 2 套不同的 OAuth 用户属性与系统的努力,几乎没有用。

不要在没有被要求时加上各种特性。明确地定义与评估场景、用户故事、需求、用途。
小提示:问一个简单的问题 - 「举例说明/使用场景是什么?」- 然后深挖那个场景。这可以揭露出大部分「特性」的不必要。
8. 内部发明的轮子。
开始时感觉很酷。但过不了几年,这些都是普通的遗留代码。
一些例子:
- 内部库(HTTP, 小型 ORM/ODM, 缓存,配置,等)。
- 内部框架(CMS,事件流,并发,后台任务,等)。
- 内部工具(构建链,部署工具,等)。
被忽略了的是:
- 花费了大量的精力在问题领域的深入理解上。一个「运行服务」的库需要是 Daemon 工作机制方面的专家,进程管理,I/O 重定向,PID 文件等等不一而足。一个 CMS 不只是关于字段解析与数据类型 - 它还包括内部字段依赖、校验、向导、泛型化解析等等。即使一个简单的「重试」库也不是那么简单的。
- 为了保持可用,需要有持续的投入。即使一个微小的开源库,也要花很多时间去维护。
- 如果你开源,没有人关注。除非原始发起人付钱请人来维护。
- 原始发起人最终会离开这个项目,简历写上「X 的发明者」字样。
- 为现存的框架做贡献要付出的是现在的时间。但是创建一个「发明」要持续地花费更多的时间。
重用。分支。贡献。重新考虑。
最后,如果真地往前推进,也只以一个内部的 OSS 的心态去做。与现有的竞争。说服内部人去用。既然你是内部人不要理所当然。(原文:Finally, if really pushed to go ahead, do it only with an Internal OSS mindset. Fight with existing competition. Work to convince even internal people to use this. Don’t take it for granted since you are an insider. )
9. 维持现状。
一旦某个东西以某种特定的方式实现,每个人默认基于它来开发。没有人对这个「现状」提出疑问。工作起来的代码就被认为「是正确的」。即使在从未被使用过的状态,人们仍然有意无意地参考过去的。
一个健康的系统是优化出来的。一个不健康的系统是只不断添加的。长时间没有看到新提交的代码部分是有臭味的。我们期待保证系统每部分频繁提交。这是详细的解析这个问题的一篇文章。
每天里,团队实际做的 vs. 应该做的:
重构无处不在。没有代码是不可以碰的。
10. 错误的估计。
我经常看到真的好的团队/开发者做出的确是一坨屎。看他们的代码库会怀疑「WTF, 这真是我以为很牛B 的团队/人开发出来的么?」
质量不只是个能力问题,是需要时间的。聪明的开发者经常过度估计自己的能力。最终的结果是,为了在自己提交的截止时间里完成任务采取丑陋的措施(代码走捷径不规范)。
错误的估计损坏质量,即使还没有写一行代码。
如果你看到了这里,谢谢!记住我这里只是讨论过度设计,不主张「牛仔编码」。