最近工作中使用了redis的zset数据结构,为了能够熟练清晰的运用这个数据结构,总结如下。
简介
zset是一个有序集合,每一个成员有一个分数与之对应,成员不可以重复,但是分实时可以重复的,zset会自动用分数对成员进行排序。
zset的常用命令
1.zadd添加语句
zadd key score member
//添加一条key为rank,score为1,member为yc的数据
zadd rank 1 yc
2.查看zset集合的成员个数
zcard key
//查看key为rank的集合内成员个数
zcard rank
3.查看zset置顶范围的成员,withscores为输出结果带分数。
zrange key start end
//获取从0到10的rank的member
zrange rank 0 10
//获取rank所有的member
zrange rank 0 -1
//输出带分数的结果
zrange rank 0 -1 withscores
4.获取zset成员的下标位置。
zrank key member
//查看member为yc的成员在key为rank集合的位置
zrank rank yc
5.获取zset集合指定分数之间的成员个数
zcount key start end
//获取rank分数值在[1,3]之内的值
zcount rank 1 3
6.删除集合中一个或者多个成员
zrem key member...
//删除rank中值为yc和qj的两个成员
zrem rank yc qj
7.获取指定的分数
zscore key member
//获取rank中tom的分数
zscore rank tom
8.为指定成员的分数进行增减操作,负值为减,正值为加。zincrby
zincrby key score member
//为tom的分数值加3
zincrby rank 3 tom
9.根据指定分数的范围获取值,zrangebyscore
zrangebyscore key start end
//获取rank中[0,9]范围内的对象
zrangebyscore rank 0 9
10.倒叙,原本默认的zset排序是从小到大按分数排序,有的场景需要用到倒叙 zrerange,zrerangebyscore
zrerange key start end
zrerangebyscore key start end
//获取rank中[0,9]范围内的对象,倒叙
zrerangebyscore rank 0 9
//获取从0到10的rank的member,以score倒叙
zreange rank 0 10
11.根据坐标,分数范围删除数据。zremrangebyscore,zremrangebyrank
zremrangebyscore key start end
zrenrabfebyrank key start end
//删除key为rank,分数范围在[0,8]的成员
zremrangebyscore rank 0 8
//删除key为rank,坐标范围在[0,2]的成员
zremrangebyrank rank 0 2
zset结构分析
zset对象的编码可以似乎ziplist也可以是skiplist,所以先来理解一下这两个结构体
实现场景
当数据较少时,sorted set是由一个ziplist来实现的。
当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
实现原因
ziplist节省内存,但是增删改查等操作较慢,而skiplist正好相反,增删改查非常快,但是相比ziplist会占用更多内存。redis在保存zset时按如下的规则进行选择:
当元素个数超过128或最大元素的长度超过64时用skiplist,其他情况下用ziplist,每次对zset进行插入、删除元素时都会重新判断是否需要转换保存格式。
ziplist
简介
ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作。
ziplist和普通双向链表的区别:
一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)。
dict
Redis的字典是用哈希表实现的,一个哈希表里面有多个哈希表节点,每个节点表示字典的一个键值对。
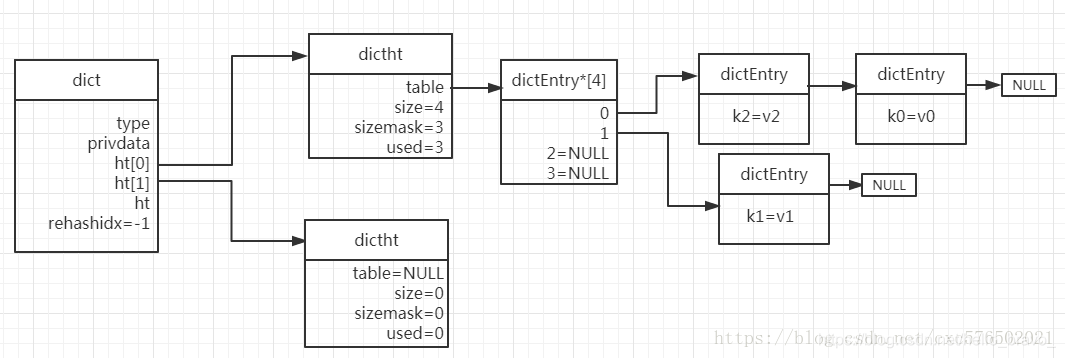
skiplist
简介
本质是一种查找结构,用于解决算法中的查找问题,根据给定的key快速查找到它所在位置,是对有序链表的优化,查找的效率一般为O(logn)。
例子
1.在普通有序链表中查找一个数据,我们要从头查找,时间复杂度是O(n)
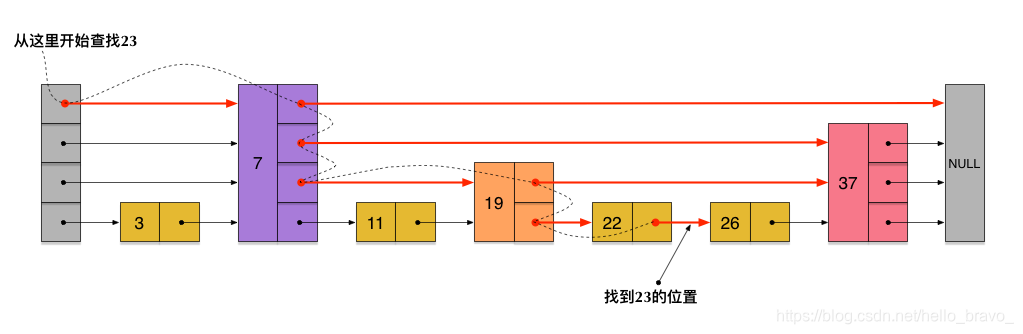
2.在普通链表之上,若我们隔一个,生成一个新的链表,这样如果我要查找23流程如下
2.1 23首先和7比较,再和19比较,比它们都大,继续向后比较。
2.2 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
2.3 比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
 由于新增的指针,我们不需要跟链表中每个节点进行比较,而是先跳跃着比较,缩小比较范围,再进行查找增加了查找的效率,在二层之上,我们还可以添加三层,四层,skiplist正式由此启发而诞生的数据结构。
由于新增的指针,我们不需要跟链表中每个节点进行比较,而是先跳跃着比较,缩小比较范围,再进行查找增加了查找的效率,在二层之上,我们还可以添加三层,四层,skiplist正式由此启发而诞生的数据结构。
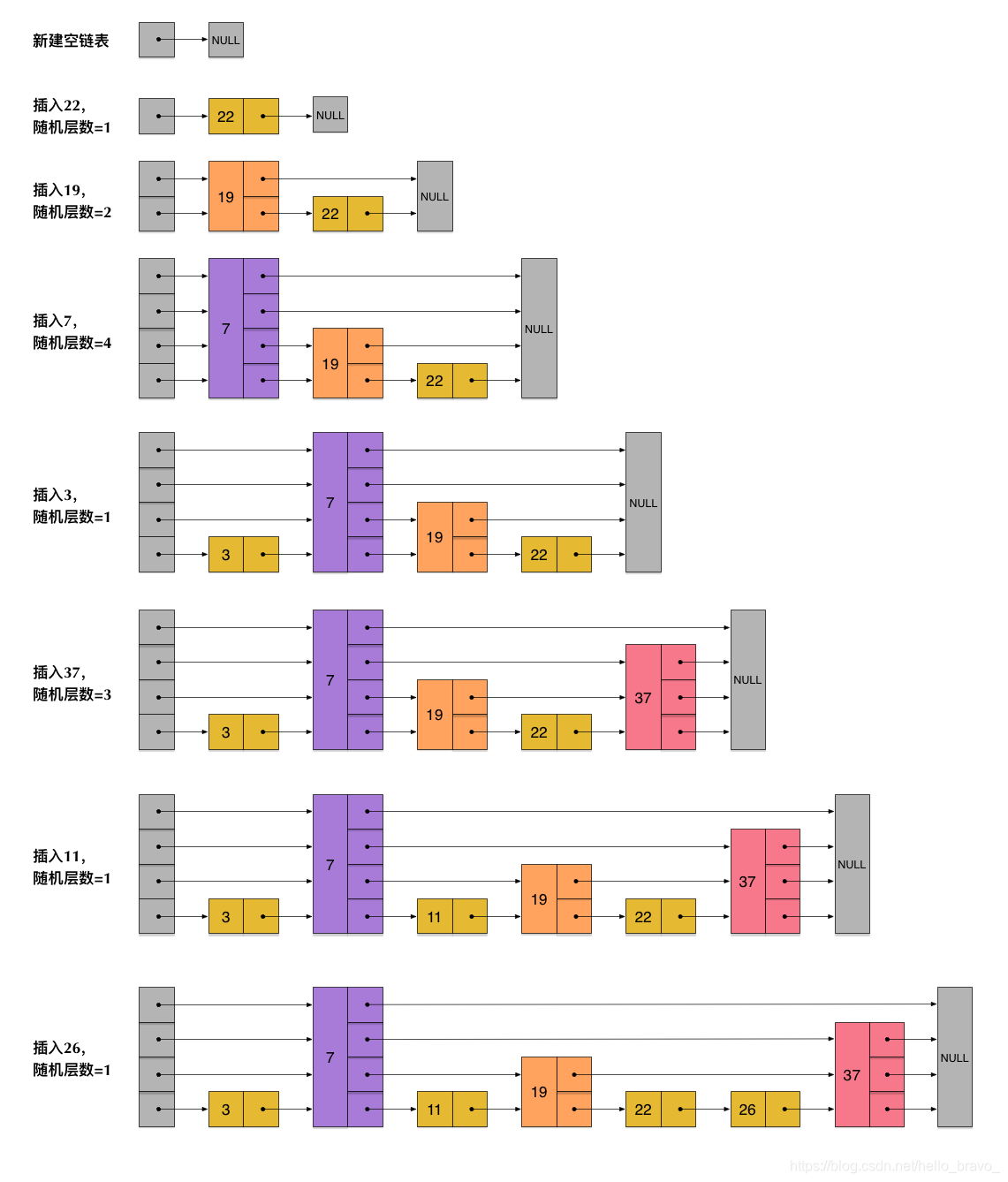
为了插入节点方便,skiplist不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是针对每个节点随机出一个层数,以下是一个skiplist生成的过程。
举例子,若要在这样的跳表查找23,流程如下
参考文章:
http://zhangtielei.com/posts/blog-redis-skiplist.htm
http://zhangtielei.com/posts/blog-redis-ziplist.html
https://blog.csdn.net/QJYWYGQJYWYG/article/details/92847077
https://blog.csdn.net/cxc576502021/article/details/82974940
