前言
线程池是Java中的一个重要概念,从Android上来说,当我们跟服务端进行数据交互的时候我们都知道主线程不能进行联网操作以及耗时操作,主线程进行联网操作在3.0之后会报一个NewWorkOnMainTHreadException的异常,而在主线程进行耗时操作则会引起ANR(Application Not Responding),但是我们经常要跟服务端进行交互,下载和上传数据等,这也就是进行联网操作,在初学时我们都是通过new Thread来开启一个线程进行联网操作,但是跟服务端交互多了,如果还是使用new Thread()来开启子线程,在一个应用中我们频繁的去通过这个方法去开启线程,这对性能来说是很大的浪费,频繁的开启销毁线程对内存的消耗是很大的,而频繁的开启线程也让整个应用的线程管理显得很混乱,这是不可取的,这时候使用线程池就可以解决这些问题了,这篇文章我尝试将线程池概念和应用说清楚,然后封装一个自定义的线程池策略以后根据业务需求稍微更改下相关的参数即可。
线程池好处
线程池可以解决两个不同问题:由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个 ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。 - - - - -Doug Lea(线程池设计者)
从前文也可以得出线程池有下面几个好处
(1)自定义线程池策略可以重用线程池中的线程,避免应用中频繁的创建和销毁线程所造成的内存消耗以及性能上不必要的开销;
(2)通过控制线程池的最大线程数能有效控制线程池的最大并发数,避免大量的线程同一时间并发抢占系统资源而造成的阻塞和界面卡死;
(3)可以自己管理线程,定时执行,间隔循环执行,线程关闭等,通过对线程的管理可以避免滥用多线程造成的问题,比如内存泄露、界面卡死、CPU阻塞等
ThreadPoolExecutor构造方法解释
线程池有着很深的体系,如果每个类每个接口都细说显得不现实,所以这里重讲它的实现类,Executor是线程池的顶级接口,而ThreadPoolExecutor是它的实现类,这个类提供了一系列方法来配置我们自己的线程池,它也封装了一些典型的线程池策略供我们使用.
ThreadPoolExecutor继承自AbstractExecutorService,而AbstractExecutorService实现了ExecutorService接口,ExecutorService接口继承了Executor,通过改变ThreadPoolExecutor构造方法里的参数我们可以自己定义线程池的属性,它一共有四个构造方法,比较常用的是下面这个方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory)
但是为了对这个类进行说明我选择的是参数最多的方法,因为不同构造方法最终回调的都是这个方法,只是设计者帮我做了一些默认的操作所以不用自己设置。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)corePoolSize
线程池的保存的线程数,它包括空闲线程,上面是api中的解释,其实详细了说这是线程池中的核心线程数,在默认情况下,即使线程是空闲状态,这个核心线程也会在线程池中存在。但是设计进行了一些逻辑处理
/**
* Returns true if this pool allows core threads to time out and
* terminate if no tasks arrive within the keepAlive time, being
* replaced if needed when new tasks arrive. When true, the same
* keep-alive policy applying to non-core threads applies also to
* core threads. When false (the default), core threads are never
* terminated due to lack of incoming tasks.
*
* @return {@code true} if core threads are allowed to time out,
* else {@code false}
*
* @since 1.6
*/
public boolean allowsCoreThreadTimeOut() {
return allowCoreThreadTimeOut;
}/**
* If false (default), core threads stay alive even when idle.
* If true, core threads use keepAliveTime to time out waiting
* for work.
*/
private volatile boolean allowCoreThreadTimeOut;从注释我们可以看出如果把allowCoreThreadTimeOut的属性值设置为true(默认是false)那么现在空闲的核心线程在等待新任务时会使用一个超时策略,这个时间间隔由keepAliveTime设置,当空闲线程等待的时间超过设置时间时核心线程将被终止。
maximumPoolSize
线程池允许容纳的最大线程数,当活动的线程达到这个最大数时如果后续还有任务,那新任务将会被阻塞(通过参数可以设置阻塞时的不同处理策略)。
keepAliveTime
非核心线程闲置时的超时时长,非核心线程可以这么理解,比如核心线程数是2,最大线程数3,那么这三个里面有一个就是非核心线程了,用个比喻就是临时工,当核心成员干不完任务就会叫上临时工一起,但是任务完成了临时工什么时候辞退就是自己指定了(比喻可能不恰当,不带任何其他的隐喻),回到文章,当超过这个时长时,非核心线程就会被回收,但是刚才介绍corePoolSize的时候也说了,如果把allowCoreThreadTimeOut的属性设置为true,keepAliveTime也可以同样对核心线程进行终止操作。
unit
就是keepAliveTime的时间单位,直接用TimeUnit这个枚举就可以点出来,常用的有TimeUnit.MINUTS(分),TimeUnit.SECONDS(秒),TimeUnit.MILLISECONDS(毫秒).不常用的有TimeUnit.HOURS(小时),TimeUnit.DAYS(天)。
workQueue
线程池中的任务队列(阻塞队列),线程池的execute方法提交的Runnable对象存储在这个队列里面,BlockingQueue是线程安全的,常用的阻塞队列有如下五个
(1).LinkedBlockingQueue
链表阻塞队列,这个队列由一个链表构成,它内部维护了一个数据缓存队列,这个队列按 FIFO(先进先出)排序元素。队列的头部 是在队列中时间最长的元素。队列的尾部 是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。 当构造这个队列对象时,如果不指定队列容量大小,它的默认容量大小是Integer.MAX_VALUE(无限大),这样就是一个无界队列,除非插入节点会使队列超出容量,否则每次插入后会动态地创建链接节点。
(2).ArrayBlockingQueue
数组阻塞队列,这是一个有界阻塞队列内部,维护了一个定长数组用来缓存队列中的数据对象,通过两个整型变量来标识队列的头跟尾在数组中的位置,这个队列按 FIFO(先进先出)原则对元素进行排序。队列的头部是在队列中存在时间最长的元素。队列的尾部 是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。一旦创建了这样的缓存区,就不能再增加其容量。试图向已满队列中放入元素会导致操作受阻塞;试图从空队列中提取元素将导致类似阻塞。
此类支持对等待的生产者线程和使用者线程进行排序的可选公平策略。默认情况下,不保证是这种排序。然而,通过将公平性 (fairness) 设置为 true 而构造的队列允许按照 FIFO 顺序访问线程。公平性通常会降低吞吐量,但也减少了可变性和避免了“不平衡性”。
(3).DelayQueue
延迟队列,它也是一个无界阻塞队列,只有在延迟期满时才能从中提取元素。这个队列的头部是延迟期满后保存时间最长的 Delayed 元素。如果延迟都还没有期满,则队列没有头部,并且 poll 将返回 null。当一个元素的 getDelay(TimeUnit.NANOSECONDS) 方法返回一个小于等于 0 的值时,将发生到期。即使无法使用 take 或 poll 移除未到期的元素,也不会将这些元素作为正常元素对待。例如,size 方法同时返回到期和未到期元素的计数。此队列不允许使用 null 元素。 通常用这个队列来管理一个超时未响应队列。
(4).PriorityBlockingQueue
优先阻塞队列,它也是一个无界阻塞队列,它使用与类 PriorityQueue 相同的顺序规则,并且提供了阻塞获取操作。虽然这个队列逻辑上是无界的,但是资源被耗尽时试图执行 add 操作也将失败(导致 OutOfMemoryError)。此类不允许使用null(空)元素。依赖自然顺序的优先级队列也不允许插入不可比较的对象(这样做会导致抛出 ClassCastException)。 在创建队列对象时通过构造函数中的Comparator属性对象来决定优先级。
(5).SynchronousQueue
同步阻塞队列,一种无缓冲阻塞队列,其中每个插入操作必须等待另一个线程的对应移除操作 ,反之亦然。同步队列没有任何内部容量,甚至连一个队列的容量都没有。不能在同步队列上进行 peek,因为仅在试图要移除元素时,该元素才存在;除非另一个线程试图移除某个元素,否则也不能(使用任何方法)插入元素;也不能迭代队列,因为其中没有元素可用于迭代。队列的头 是尝试添加到队列中的首个已排队插入线程的元素;如果没有这样的已排队线程,则没有可用于移除的元素并且 poll() 将会返回 null。对于其他 Collection (集合)方法(例如 contains),同步队列作为一个空集合这个不允许null(空)元素。
同步队列类似于 CSP 和 Ada 中使用的 rendezvous 信道。它非常适合于传递性设计,在这种设计中,在一个线程中运行的对象要将某些信息、事件或任务传递给在另一个线程中运行的对象,它就必须与该对象同步。
对于正在等待的生产者和使用者线程而言,此类支持可选的公平排序策略。默认情况下不保证这种排序。但是,使用公平设置为 true 所构造的队列可保证线程以 FIFO 的顺序进行访问。
threadFactory
线程工厂,用于在线程池中创建新线程,线程池设计者提供了两个(其实是一个)线程池工厂给我们使用,一个是defaultThreadFactory(),另一个是privilegedThreadFactory,但是查看源码我发现
/**
* Legacy security code; do not use.
*/
public static ThreadFactory privilegedThreadFactory() {
return new PrivilegedThreadFactory();
}设计者说这是遗留的安全代码,叫我们不要使用privilegedThreadFactory..,所以一般线程池工厂我们用的是defaultThreadFactory,用法很简单,直接用Executors.defaultThreadFactory();就可以创建一个默认线程池工厂。
handler
这个参数是一个RejectedExecutionHandler对象,它是一个接口,只有rejectedExecution这个方法,这个参数的作用是当线程池由于任务队列已满或别的原因无法执行新任务时,ThreadPoolExecutor就会回调实现了这个接口的类来处理被拒绝任务,它的使用是直接用THreadPoolExecutor.XXX,线程池设计者提供了四个处理方法:
(1).ThreadPoolExecutor.AbortPolicy
直接抛出RejectedExecutionException异常,如果不设置处理策略默认是这个方法进行处理
(2).ThreadPoolExecutor.CallerRunsPolicy
直接在 execute 方法的调用线程中运行被拒绝的任务;如果执行程序已关闭,则会丢弃该任务.
(3).ThreadPoolExecutor.DiscardOldestPolicy
放弃最旧的未处理请求,然后重试 execute;如果执行程序已关闭,则会丢弃该任务。
(4).ThreadPoolExecutor.DiscardPolicy
默认情况下直接丢弃被拒绝的任务。
在平常使用时可以根据实际需要制定相关的操作。
小结
THreadPoolExecutor在执行任务时大体是这样的,如果线程池中线程的数量没有达到核心线程的数量,它就会启动一个核心线程来执行任务,如果达到或超过核心线程数量,那么任务会插入到任务队列中等待执行,如果任务队列满了。但是线程数量没有达到线程池的最大数,那就回启动一个非核心线程(临时工)来执行任务,如果线程数量达到线程池最大数,那么就会拒绝处理新任务并调用handler的rejectedExecution来处理拒绝任务(处理策略就是上面四种)。
线程池设计者提供的四种线程池策略
线程池设计者为我们提供了四种不同的线程池策略,分别是FixedThreadPool,SingleThreadExecutor,CachedThreadPool,ScheduledThreadPool,他们放在了Executors这个类中,下面逐一分析
(1).FixedThreadPool
这个策略源码为:
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}通过Executors.newFixedThreadPool()这个方法我们可以创建这个线程池,这是一个线程数量固定且可重用的线程池它的核心线程数和最大线程数是一样的,当线程处于空闲状态时,除非线程池关闭,否则线程不会被回收,,当所有线程都处于活动状态时,新任务都会处于等待状态,这个线程池策略没有超时策略(0L),任务队列也是无界队列(LinkedBlockingQueue),线程工厂由调用者自己指定,拒绝任务处理策略是默认处理策略(直接抛出RejectedExecutionException异常)。
(2).SingleThreadExecutor
这个策略源码为:
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}从返回的参数可以看出这个策略只有一个核心线程,它确保了所有任务都是在同一个线程中按顺序来执行,这就不需要处理线程同步的问题了,由于最大线程数跟核心线程数都是1,所以也就不存在非核心线程超时策略了,任务队列为无界队列,线程池工厂是默认的线程池工厂。
(3).CachedThreadPool
这个策略源码为:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}从返回的参数可以看出,它并没有核心线程数(0),最大线程数为Integer.MAX_VALUE(可以看做任意大),当线程池的线程都处于活动状态时,如果有新任务,线程池会创建新的线程来处理新任务,否则就会用闲置线程来处理任务,它的非核心线程超时策略是60秒(60L),超过60秒闲置线程就会被回收,前面说过SynchronousQueue是一个空集合,是无法存储元素的,这就造成了只要有任务就会被立即执行,这种线程池策略审核执行大量单耗时较少的任务,如果线程池处于闲置状态,由于有超时策略,线程池中的所有线程都会被停止,这时线程池中没有任何线程,所以不占用任何系统资源。
(4).ScheduledThreadPool
这个策略源码为:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}从参数可以看出,它核心线程是调用者自己设定的,也就是一个固定的值,但是最大线程数是无限大,而且超时策略是10毫秒(基本就是立即了..)回收,而阻塞队列是延时队列,这也说明了这种线程池策略是执行定时或周期重复的任务。
小结
其实当我们前面把ThreadPoolExecutor构造方法进行分析以后理解Doug Lea(线程池设计者)给我们提供的几种线程池策略就不难了,我个人觉得Doug Lea之所以给我们提供了几种策略是为了方便我们使用线程池,但是如果我们了解了参数的含义我们完全可以自己定义一个属于自己的线程池策略。下面我封装一个自定义的线程池策略。
封装自己的线程池策略
前面说了Doug Lea(线程池设计者)提供了四种具有不同特性的线程池策略给我们使用,日常开发使用其中一种也是可以的,但是我们既然懂得了原理当然可以自己自定义一个来使用,下面我一步步封装一个线程池策略然后进行测试(这个策略某些参数参考了AsyncTask)。
首先是线程池代理类,源码为:
public class ThreadPoolProxy {
private ThreadPoolExecutor executor;
private int corePollSize;//核心线程数
private int maximumPoolSize;//最大线程数
private long keepAliveTime;//非核心线程持续时间
public ThreadPoolProxy(int corePollSize, int maximumPoolSize, long keepAliveTime) {
this.corePollSize = corePollSize;
this.maximumPoolSize = maximumPoolSize;
this.keepAliveTime = keepAliveTime;
}
/**
* 单例,产生线程
*/
@TargetApi(Build.VERSION_CODES.GINGERBREAD)
public void getThreadPoolProxyInstant() {
if (executor == null)
synchronized (ThreadPoolProxy.class) {
if (executor == null) {
BlockingDeque<Runnable> workQueue = new LinkedBlockingDeque<Runnable>(128);//任务队列容量128
ThreadFactory threadFactory = Executors.defaultThreadFactory();//默认的线程工厂
RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();//拒绝任务时的处理策略,直接抛异常
executor = new ThreadPoolExecutor(corePollSize,
maximumPoolSize,
keepAliveTime,
TimeUnit.SECONDS,
workQueue,
threadFactory,
handler);
}
}
}
/**
* 执行任务
*
* @param task
*/
public void excute(Runnable task) {
getThreadPoolProxyInstant();
executor.execute(task);
}
/**
* 删除任务
*
* @param task
*/
public boolean remove(Runnable task) {
getThreadPoolProxyInstant();
boolean remove = executor.remove(task);
return remove;
}
}这里我把非核心线程超时策略单位设置为了秒,任务队列容量设置为128,线程池工厂设置成了默认工厂,拒绝任务的策略设置成了直接抛出异常。然后剩下的三个参数在工厂类生产线程时进行设置,工厂类代码为:
public class ThreadPoolFactory {
private static ThreadPoolProxy commonThreadPool;//获取一个普通的线程池实例
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();//获得CPU数量
private static final int COMMOM_CORE_POOL_SIZE = CPU_COUNT + 1;//根据CPU核数来设定核心线程数
private static final int COMMON_MAXPOOL_SIZE = CPU_COUNT * 2 + 1;//最大线程池数
private static final long COMMON_KEEP_LIVE_TIME = 1L;//持续时间
public static ThreadPoolProxy getCommonThreadPool() {
if (commonThreadPool == null)
synchronized (ThreadPoolFactory.class) {
if (commonThreadPool == null)
commonThreadPool = new ThreadPoolProxy(COMMOM_CORE_POOL_SIZE,
COMMON_MAXPOOL_SIZE, COMMON_KEEP_LIVE_TIME);
}
return commonThreadPool;
}
}这里的核心线程跟跟最大线程数是根据手机的cpu核心数进行动态设置,然后把使用方法封装成一个Util类:
public class ThreadPoolUtil {
/**
* 在非UI线程中执行
*
* @param task
*/
public static void runTaskInThread(Runnable task) {
ThreadPoolFactory.getCommonThreadPool().excute(task);
}
public static Handler handler = new Handler();
/**
* 在UI线程中执行
*
* @param task
*/
public static void runTaskInUIThread(Runnable task) {
handler.post(task);
}
/**
* 移除线程池中线程
*
* @param task
*/
public static boolean removeTask(Runnable task) {
boolean remove = ThreadPoolFactory.getCommonThreadPool().remove(task);
return remove;
}
}通过上面的封装就可以自定义一个自己的线程池策略了,当然这个策略的参数可以根据实际需要进行配置,我这里是直接参考AsyncTask来配置的。
然后做个栗子来验证:
我这里是模拟下载,界面截图如下:
主界面业务逻辑为:
public class MainActivity extends AppCompatActivity implements View.OnClickListener {
private ProgressBar pb1;
private ProgressBar pb2;
private ProgressBar pb3;
private ProgressBar pb4;
private Button btn1;
private Button btn2;
private Button btn3;
private Button btn4;
private static final int FLAGS1 = 1;
private static final int FLAGS2 = 2;
private static final int FLAGS3 = 3;
private static final int FLAGS4 = 4;
private Handler mHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case FLAGS1:
pb1.setProgress(msg.arg1);
break;
case FLAGS2:
pb2.setProgress(msg.arg1);
break;
case FLAGS3:
pb3.setProgress(msg.arg1);
break;
case FLAGS4:
pb4.setProgress(msg.arg1);
break;
default:
break;
}
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
init();
}
private void init() {
pb1 = (ProgressBar) findViewById(R.id.pb1);
pb2 = (ProgressBar) findViewById(R.id.pb2);
pb3 = (ProgressBar) findViewById(R.id.pb3);
pb4 = (ProgressBar) findViewById(R.id.pb4);
btn1 = (Button) findViewById(R.id.btn1);
btn2 = (Button) findViewById(R.id.btn2);
btn3 = (Button) findViewById(R.id.btn3);
btn4 = (Button) findViewById(R.id.btn4);
btn1.setOnClickListener(this);
btn2.setOnClickListener(this);
btn3.setOnClickListener(this);
btn4.setOnClickListener(this);
}
private Runnable runnable1 = new MRunnable(FLAGS1);
private Runnable runnable2 = new MRunnable(FLAGS2);
private Runnable runnable3 = new MRunnable(FLAGS3);
private Runnable runnable4 = new MRunnable(FLAGS4);
@Override
public void onClick(View v) {
switch (v.getId()) {
case R.id.btn1:
updateProcessBar(runnable1);
break;
case R.id.btn2:
updateProcessBar(runnable2);
break;
case R.id.btn3:
updateProcessBar(runnable3);
break;
case R.id.btn4:
updateProcessBar(runnable4);
break;
default:
break;
}
}
private void updateProcessBar(Runnable runnable) {
ThreadPoolUtil.runTaskInThread(runnable);
}
private class MRunnable implements Runnable {
private int mFlags;
public MRunnable(int flags) {
this.mFlags = flags;
}
@Override
public void run() {
for (int i = 0; i <= 100; i++) {
Message msg = mHandler.obtainMessage();
//随机数,让下载更真实...
Random rand = new Random();
int randNum = rand.nextInt(100);
SystemClock.sleep(randNum);
msg.what = mFlags;
msg.arg1 = i;
mHandler.sendMessage(msg);
}
}
}
/**
* 退出时清除线程
*/
@Override
protected void onDestroy() {
super.onDestroy();
ThreadPoolUtil.removeTask(runnable1);
ThreadPoolUtil.removeTask(runnable2);
ThreadPoolUtil.removeTask(runnable3);
ThreadPoolUtil.removeTask(runnable4);
}
}然后为了方便测试,我把核心线程数固定,而不是根据CPU核心数来改变,当我把核心线程数定为1,这时效果为:
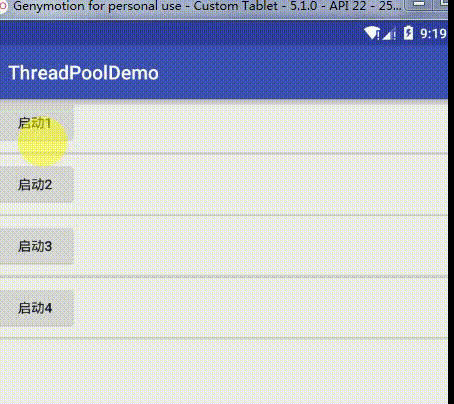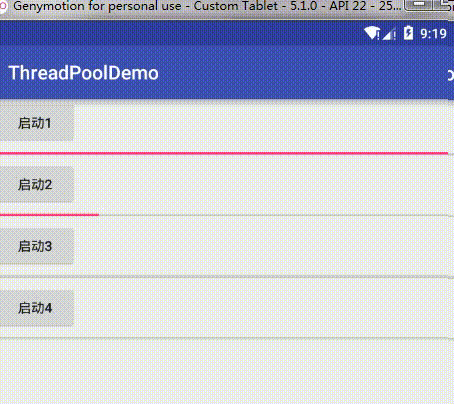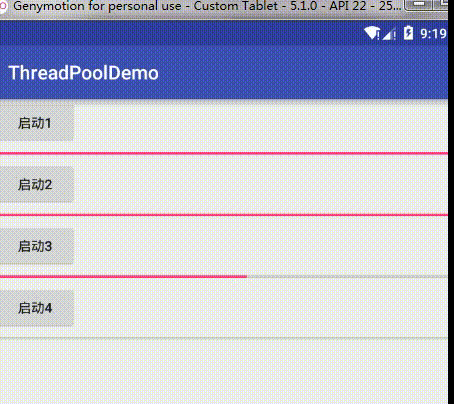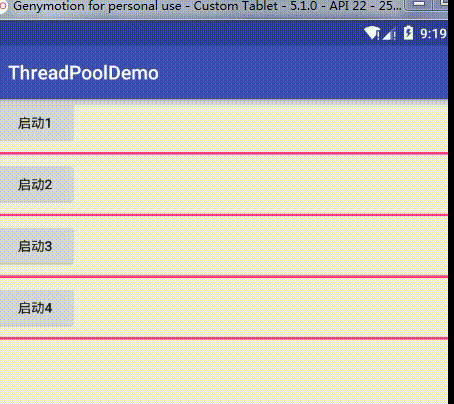
可以看到,当我依次启动1、2、3、4时,由于队列我们设置成了LinkedBlockingDeque,这个队列是按 FIFO(先进先出)排序元素的,所以就会按顺序来执行,也就是当1执行时其他任务的都在队列中阻塞,只有1完成了才会往下执行,这也印证了我们关于线程池的的参数属性讲解,这里可能你们会有疑问,前面不是说当任务数超过corePoolSize就会创建新的非核心线程(临时工)去处理任务吗,这里怎么没有这样?其实创建新的线程是有条件的,这个条件是你的任务队列已经满了,这时如果还加新的任务才会去创建非核心线程去处理这个任务,要验证其实也很简单,只要把
BlockingDeque<Runnable> workQueue = new LinkedBlockingDeque<Runnable>(128);这个队列大小从128改为2,再重新启动,效果为:
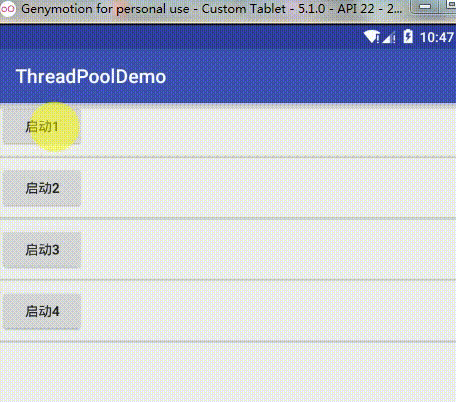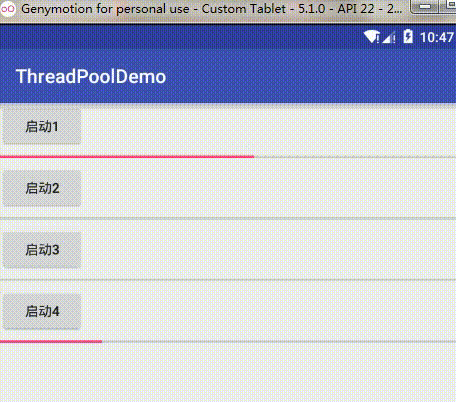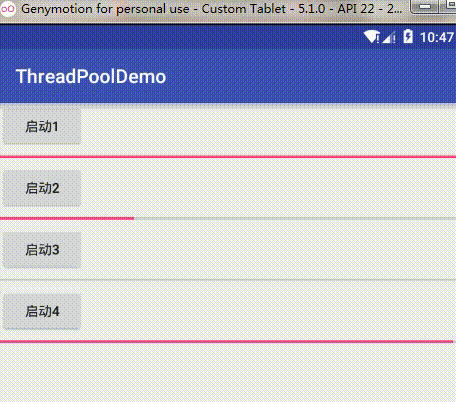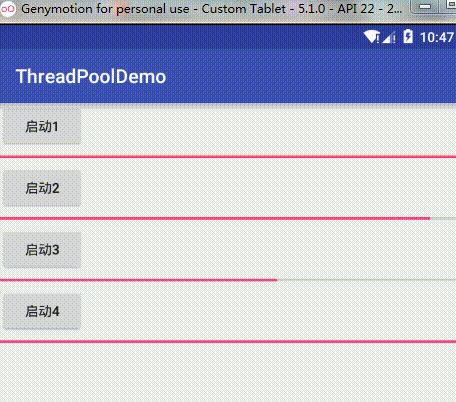
从图片可以看到,当我依次启动任务1、2、3、4时,顺序是先1启动,然后2、3阻塞,然后再启动4,4也跟着一起执行,然后这两个任务执行完之后才依次执行2、3,这也验证了我们上面的分析,我启动任务1,1立即执行,这时任务队列是没有任务在等待的,然后我启动任务2、3,这时任务队列并没有满,所以这两个任务就在任务队列中阻塞等待,当我再启动任务4时,这时任务队列已经满了,而线程数量没达到最大线程数,所以这个策略就新开了一个非核心线程去执行4这个新的任务,然后由于这时没有新任务,所以总共就有两个线程去执行任务了,当1,4有一个执行完了,就会去队列中依次执行2,3。
把任务队列大小调回128继续我们的论证,把核心线程数改成2,这时效果为:
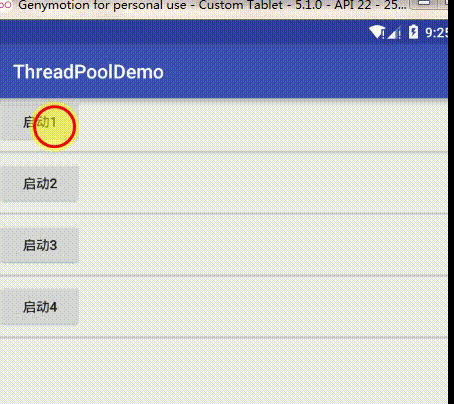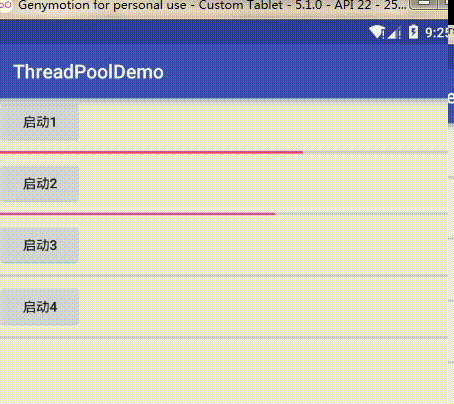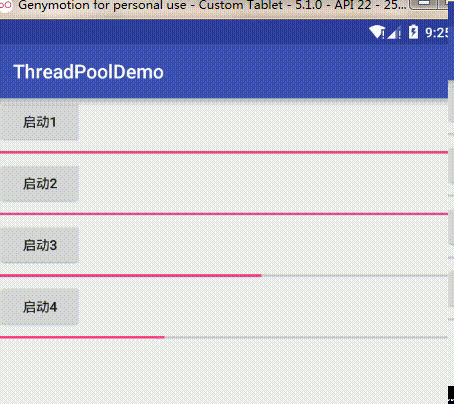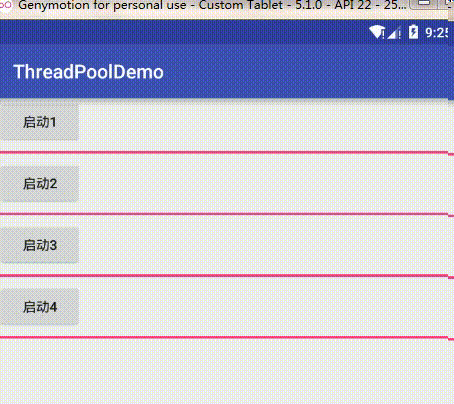
可以看到它每次起两个线程去完成下载任务,然后如果两个核心线程任务没结束后续任务会阻塞等待,只有其中一个完成了才会接着执行。
从上面的栗子也可以看出,当我们把核心线程修改是就可以自己定义下载的规则了,平常我们看一些Android市场下载软件原理用的就是自己的线程池策略。
总结
Android的线程池策略对我们管理应用中的线程是一个很方便高效的事,在日常开发中我们可以根据实际需要去配置符合业务需求的线程池策略,这样可以让应用处理涉及耗时的任务时更高效和节省资源开销,这篇文章我是很用心的写了,在写的过程中我自己对某些知识点也是有一种恍然大悟的感觉,所以我很希望这篇文章对想了解这方面知识点的人有所帮助,如果某些地方不了解或觉得哪个点错了,可以评论(虽然不一定及时看到..)但是有疑问我一定尽力去解答(微笑脸)。
最后虽然所有类都在文章中但是还是附个文章涉及的源码,可能有些筒子是直接看源码的(比如我)…
平常一直用svn管理代码,前不久刚学会怎么使用git(感觉自己有点土逼的感觉),所以这次直接把源码传到github上,有些同学可能习惯在csdn上下载,所以多搞了个csdn链接,我就是这么人性化(骄傲脸)..年纪大了有些碎碎嘴了..
github地址:https://github.com/songjiran/ThreadPoolDemo
csdn地址:http://download.csdn.net/detail/lxzmmd/9535019
