目录
胡说
前段时间搞的纪念日后面说了想搞个历史上的今天,由于许久没用python爬取过东西了,就简单的试了下,用几行代码把数据添加进去了,当然今天的重点不是这个,不过还是将它发出来吧。
思路
- 将数据爬取下来
- 将数据保存到本地数据库
- 从数据库获取信息,并随机打开一条到页面
- 连接点击可调起浏览器查看
增加的源码
"""
Label(self.page,font=("微软雅黑", 25),text=title).pack()
Label(self.page,font=("微软雅黑", 10),text=start_day+"---"+now_day,fg = "red").pack()
Label(self.page,font=("微软雅黑", 20),text=date,fg = "red").pack()
Label(self.page,font=("微软雅黑", 15),text=infos).pack()
Button(self.page,text='删除该纪念日', bd =5,width=10,command=lambda :del_ann(title)).pack(anchor=N)
#在这段源码下添加,在Infopage类中
"""
#优先查找数据库看看有没有
#没有就去爬取
a=thing_showdb(now_day[5:])
if a==[]:
year_today_main(now_day[5:])
time.sleep(1)
a=thing_showdb(now_day[5:])
year_date=a[randint(0,len(a)-1)][1]
info=a[randint(0,len(a))][2]
url=a[randint(0,len(a))][3]
j=0
urls=''
infos=''
for i in info:
if j<=10:
infos+=i
j+=1
else:
infos+=i+'\n'
j=0
j=0
for i in url:
if j<=50:
urls+=i
j+=1
else:
urls+=i+'\n'
j=0
def open_url(event):
webbrowser.open(url, new=0)
Label(self.page,font=("微软雅黑", 10),text='历史上的今天\n'+year_date).pack()
Label(self.page,font=("微软雅黑", 15),text=infos,fg = "red").pack()
link=Label(self.page,font=("微软雅黑", 10),text=urls,fg = "blue")
link.pack()
link.bind("<Button-1>", open_url)爬取源码
该部分我并没有将数据加进数据库中,只是将爬取的数据变成字典模式{’时间‘:[事件,详情网址] }-->>
{'1979年3月7日': ['旅行者1号发现木星','http://www.todayonhistory.com/3/7/LvHangZhe1gHuanDeHangXing.html']}
#那年今日
import requests
import lxml.html
import datetime
today=str(datetime.datetime.now().date())[5:].split('-')
html_url='http://www.todayonhistory.com/%s/%s/'%(today[0],today[1])
# print(html_url)
def get_url(html_url,encode):
"""
爬取整个网页内容
:param html_url:
:return:
"""
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0"
}
response = requests.get(html_url, headers=headers)
response.encoding = encode
html_content = response.text
return html_content
# print(get_url(html_url,'utf-8'))
def get_data(html_content):
metree = lxml.html.etree
parser = metree.HTML(html_content)
thing_list= parser.xpath("//ul[@class='oh']/li/div[@class='pic']/div[@class='t']")
# print(day_list)
all_thing={}
for i in thing_list:
temp=[]
temp.append(i.xpath("./a/text()")[0])
temp.append(i.xpath("./a/@href")[0])
all_thing[i.xpath("./span/text()")[0]]=temp
print(all_thing)
get_data(get_url(html_url,'utf-8'))
{'1979年3月7日': ['旅行者1号发现木星是带有光环的行星','http://www.todayonhistory.com/3/7/LvHangZhe-1HaoFaXianMuXingShiDaiYouGuangHuanDeHangXing.html']}详细步骤
- 拼接网址,该网站是按日期获取数据的,http://www.todayonhistory.com/是主页,当后面拼接一个日期时就获得该日的数据,比如http://www.todayonhistory.com/03/07/就是3月7日数据
- 由此我们可以获得当日时间并切片成[03,07]的列表模式
-
today=str(datetime.datetime.now().date())[5:].split('-')#获取当前日期并切片成[月份,日期]模式 html_url='http://www.todayonhistory.com/%s/%s/'%(today[0],today[1]) #获得日期拼接网址 # print(html_url) - 请求网址获得网页内容,编码右键鼠标查看看网页源代码,第一句就是<meta charset="utf-8" />,所以我们的请求方式就是get_url(html_url,'utf-8')。
-
def get_url(html_url,encode): """ 爬取整个网页内容 :param html_url: :return: """ headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0" } response = requests.get(html_url, headers=headers) response.encoding = encode html_content = response.text return html_content -
然后从返回的网页内容中查找我们所要的信息,具体方式看图
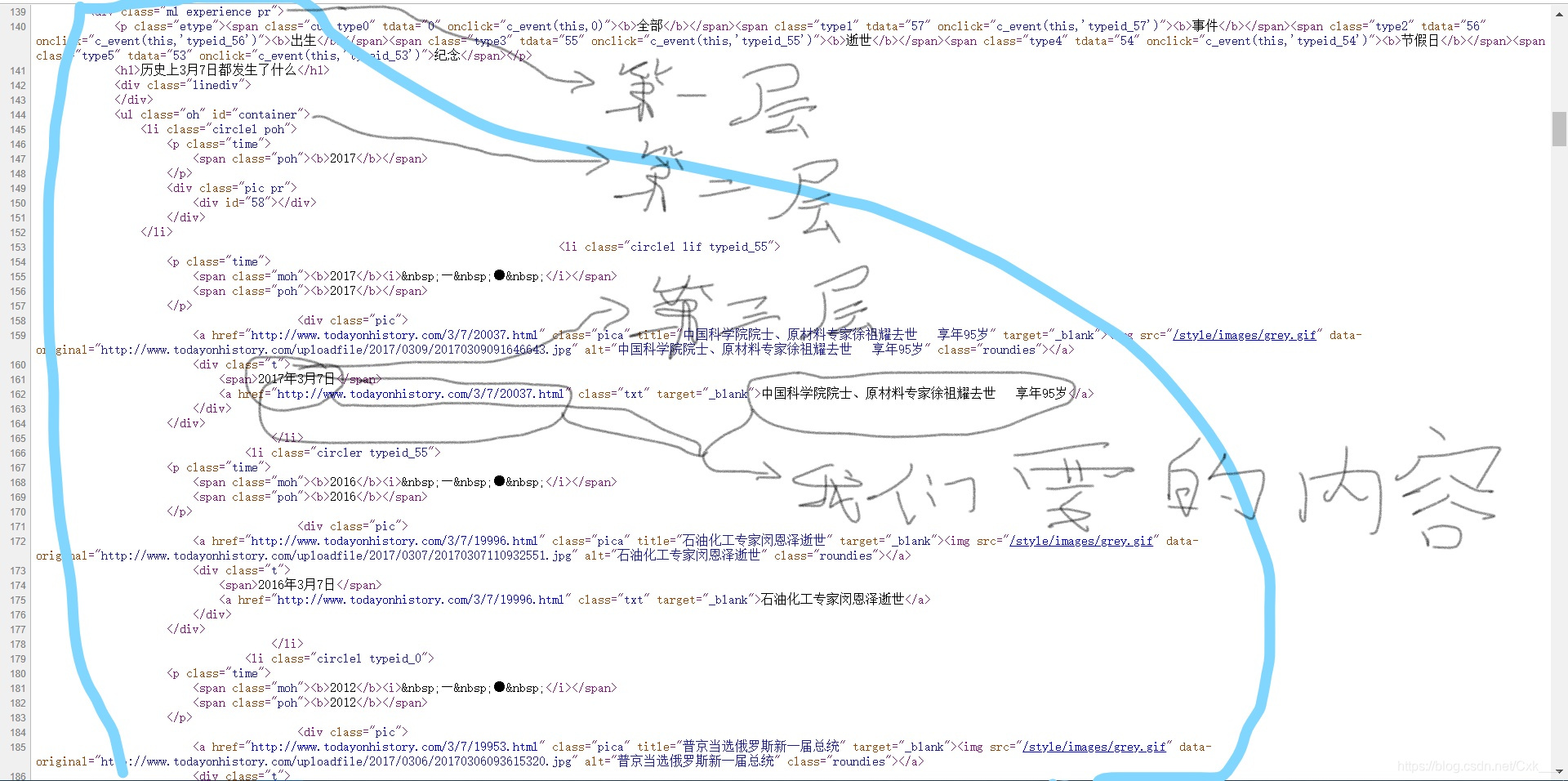
-
知道了布局我们就可以用xpath一句话来很好的获取到我们想要的内容:我们从第二层开始爬取
-
thing_list= parser.xpath("//ul[@class='oh']/li/div[@class='pic']/div[@class='t']")
-
然后他会返回一个列表,我们再遍历列表获取到画圈的内容标签外的文本我们用当前标签的text()方法获取,里面的连接我们就用@+内容索引获取,比如一个<a href=‘####’> 一二三 </a>标签 一二三 就是标签外的文本,href就是内容索引。
-
最后我们将遍历到的内容按自己想要的格式存下来,我这里先建立一个字典,然后将时间作为key,事件跟详情网址添加进一个列表作为value
def get_data(html_content):
metree = lxml.html.etree
parser = metree.HTML(html_content)
thing_list= parser.xpath("//ul[@class='oh']/li/div[@class='pic']/div[@class='t']")
all_thing={}
for i in thing_list:
temp=[]
temp.append(i.xpath("./a/text()")[0])
temp.append(i.xpath("./a/@href")[0])
all_thing[i.xpath("./span/text()")[0]]=temp
print(all_thing)
八道
这是一个很简单的爬取方式,但也很实用,就个人感觉Xpath比BeautifulSoup4比较好用,但是有时候动态网页就要用selenium模仿用户使用浏览器获取内容了。
但是我们想要将网站整年数据爬下来的话拼接网址并进行获取,如果不加限制ip瞬间会被封的,曾经懵懵懂懂的我被各大网站封了一天又一天,但是我们获取这些数据并没多大用处,练习一下就好了,我尝试过一秒获取2次数据并没什么限制,但如果往上我就不知了,我们可以用time.sleep(t)--t=秒数延时一下,百试百灵,比建立ip库好多的,就是时间有点久。
