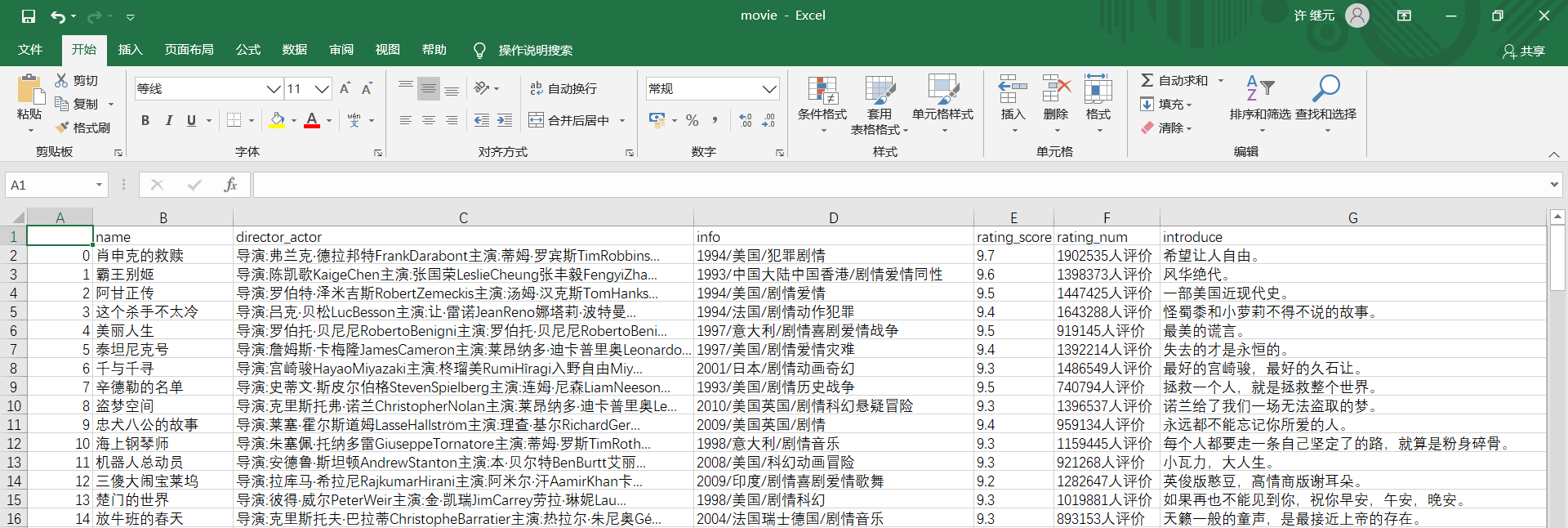
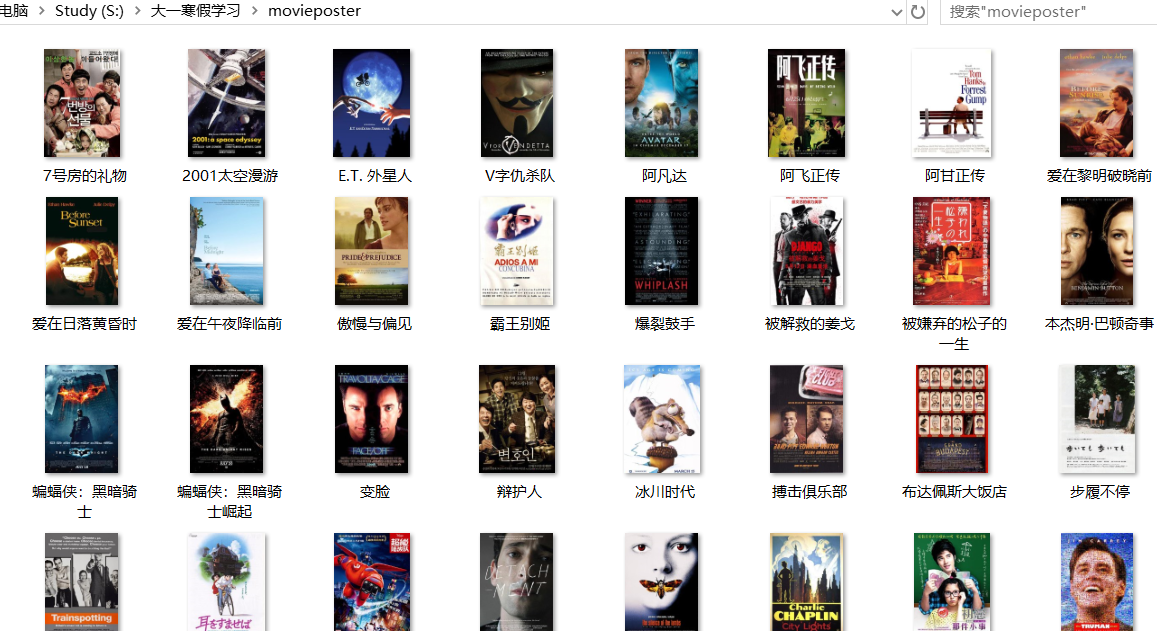
该项目大致分为以下步骤:
- 使用 requests库 获取页面
- 使用 lxml库 和 XPath 解析页面
- 爬取电影海报图片
- 使用 pandas库 将电影的相关信息存储为csv文件
- 添加循环,保存所有图片以及相关信息
首先,我们构建一个框架来获取豆瓣电影的HTML页面:
import requests
# 获取HTML页面
def get_html(url):
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
try:
html = requests.get(url, headers=headers)
html.encoding = html.apparent_encoding
if html.status_code == 200:
print("获取HTML页面成功!")
except Exception as e:
print("获取HTML页面失败,原因是:%s" % e)
return html.text
if __name__ == '__main__':
url = "https://movie.douban.com/top250"
html = get_html(url)
接下来,我们分析一下豆瓣电影的网页:
使用开发者工具(F12),经过分析,可以发现每一页的电影信息都是这些li标签:
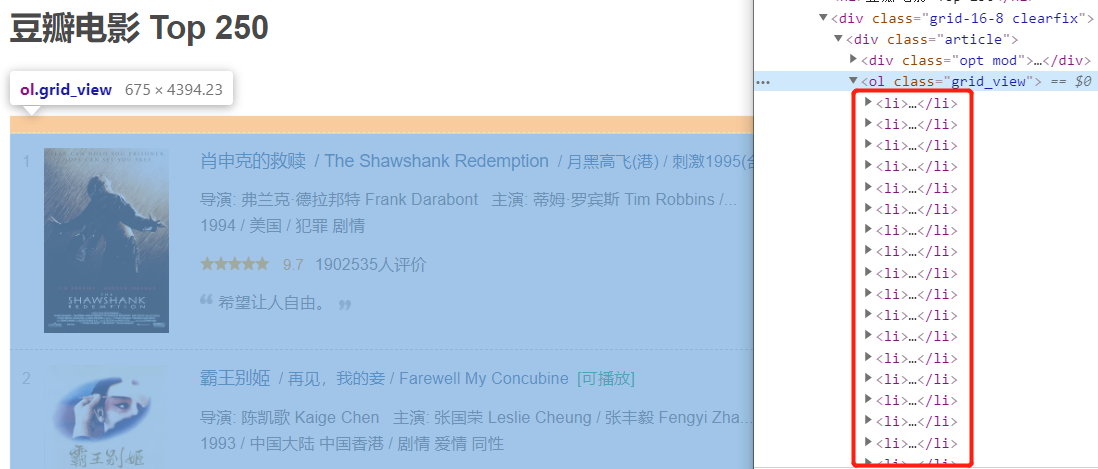
我们用 XPath Helper 获取这些li标签:
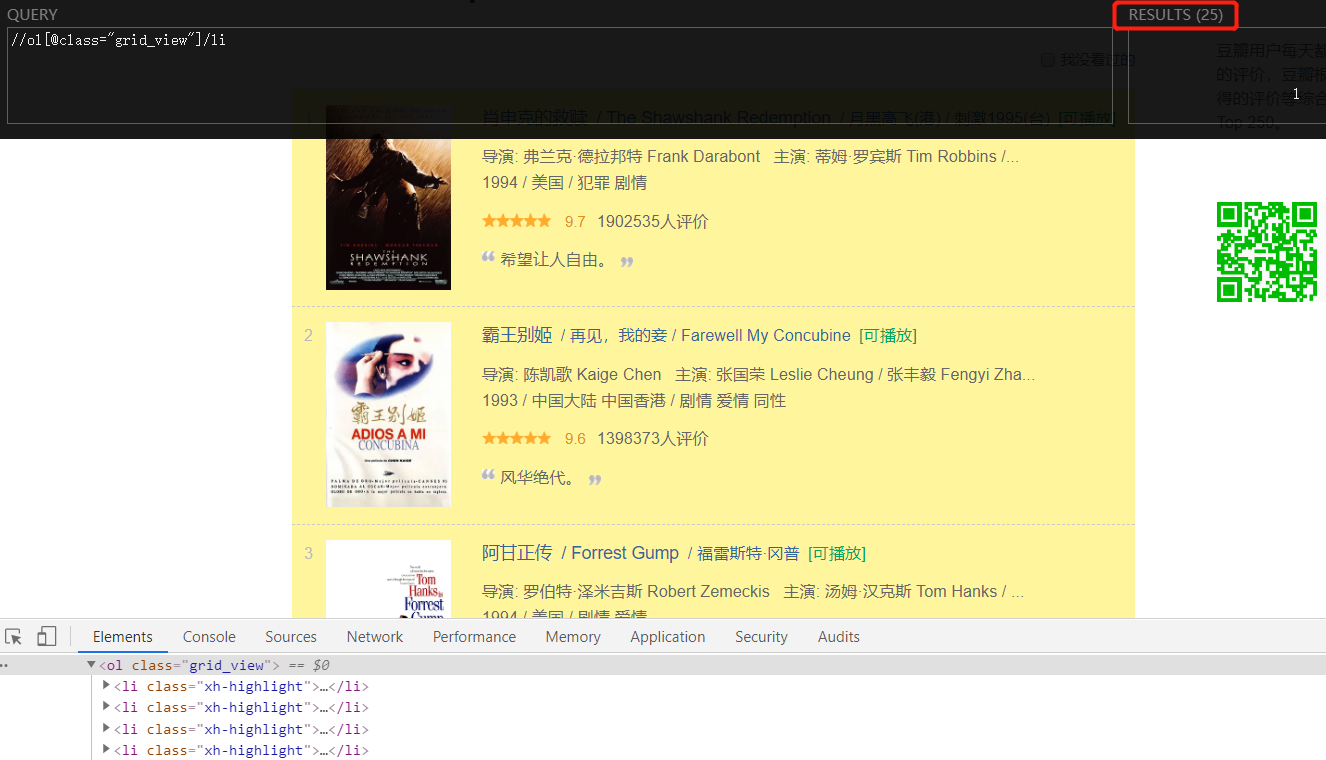
在刚才获取的li标签下继续分析电影相关信息:
首先是电影名字:
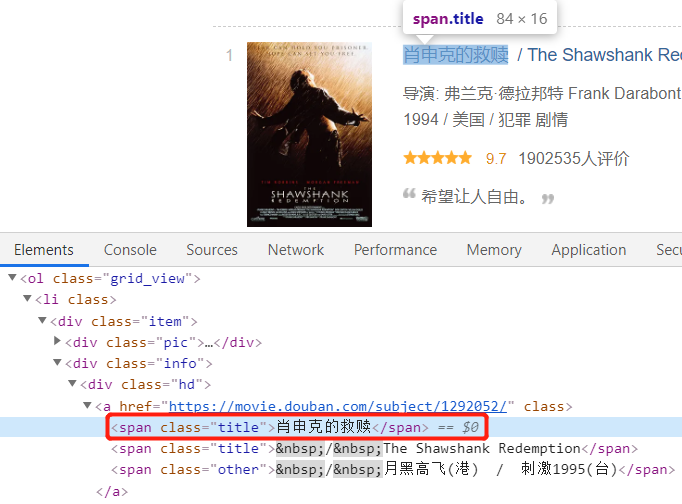
接下来是导演主演信息:
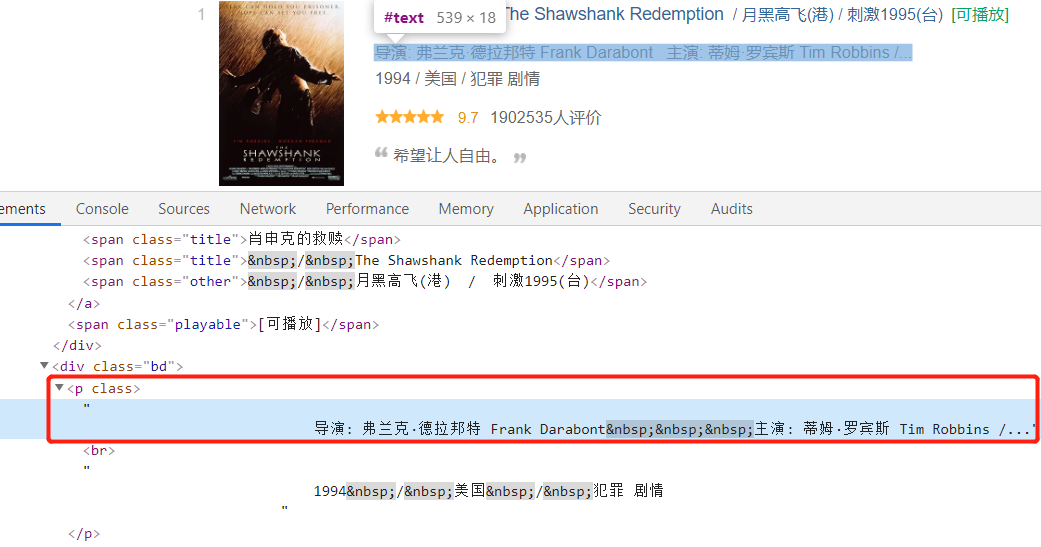
然后是年份、国家和电影类型:
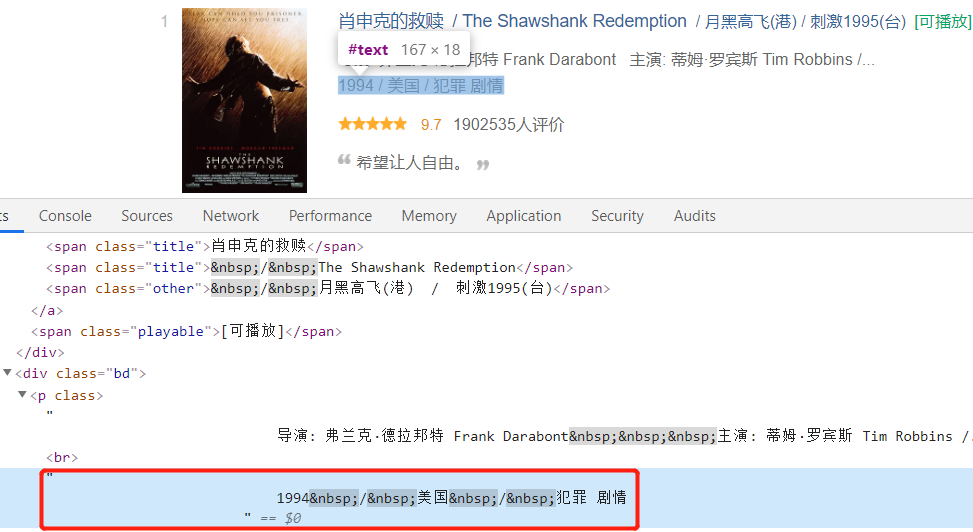
接下来是电影评分:
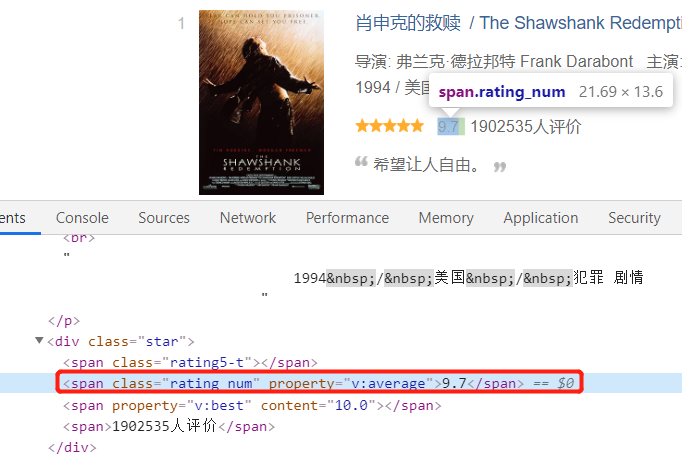
然后是评价人数:
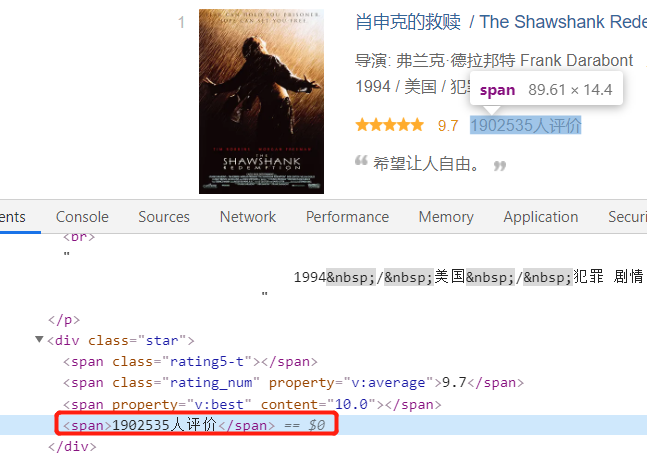
接下来是简介:
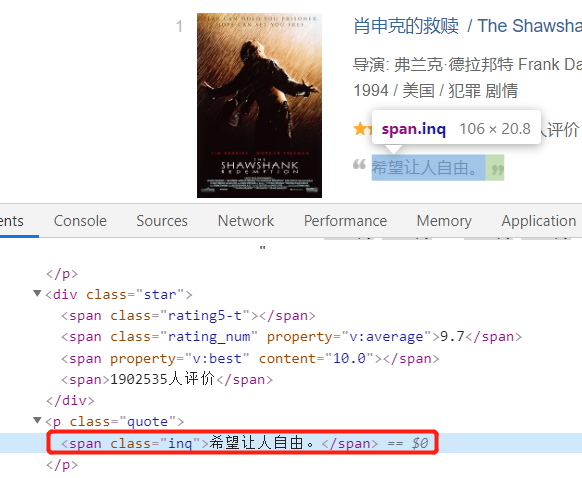
(这里发现Top 247的那部电影没有简介,所以后面需要处理一下)
最后是电影海报图片:
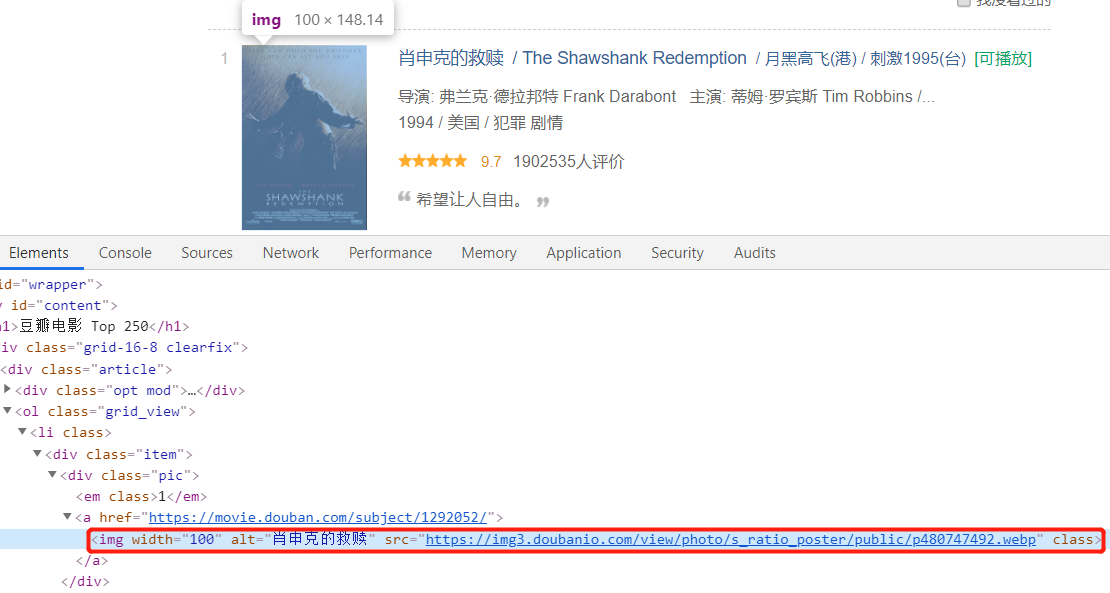
分析完页面之后,我们写一下解析页面的函数:
from lxml import etree # 解析HTML页面
# 解析HTML页面
def parse_html(html):
movies = [] # 存储电影的相关信息
imgurls = [] # 存储电影海报图片
html = etree.HTML(html)
lis = html.xpath("//ol[@class='grid_view']/li") # XPath返回列表对象
# 提取每一部电影的相关信息
for li in lis:
# 下面的XPath路径前面都要加上. 表示从li这个节点开始
name = li.xpath(".//a/span[@class='title'][1]/text()")[0] # 获取到的列表第0个元素才是电影名字
director_actor = li.xpath(".//div[@class='bd']/p/text()[1]")[0].replace(' ','').replace('\n','').replace('/','').replace('\xa0', '') # 去除字符串中的多余字符
info = li.xpath(".//div[@class='bd']/p/text()[2]")[0].replace(' ','').replace('\n','').replace('\xa0', '') # 去除字符串中的多余字符
rating_score = li.xpath(".//span[@class='rating_num']/text()")[0]
rating_num = li.xpath(".//div[@class='star']/span[4]/text()")[0]
introduce = li.xpath(".//p[@class='quote']/span/text()")
# 把提取的相关信息存入movie字典,顺便处理Top 247那部电影没有introduce的情况
if introduce:
movie = {'name': name, 'director_actor': director_actor, 'info': info, 'rating_score': rating_score,
'rating_num': rating_num, 'introduce': introduce[0]}
else:
movie = {'name': name, 'director_actor': director_actor, 'info': info, 'rating_score': rating_score,
'rating_num': rating_num, 'introduce': None}
movies.append(movie)
imgurl = li.xpath(".//img/@src")[0] # 提取图片URL
imgurls.append(imgurl)
return movies, imgurls
if __name__ == '__main__':
url = 'https://movie.douban.com/top250'
html = get_html(url)
movies = parse_html(html)[0]
imgurls = parse_html(html)[1]
测试时发现 director_actor 和 info 有 \xa0不间断空白符:
用.replace(’\xa0’, ‘’)语句去除。

接下来编写保存电影海报图片的函数:
import os
# 保存海报图片
def download_img(url, movie):
if 'movieposter' in os.listdir(r'S:\大一寒假学习'):
pass
else:
os.mkdir('movieposter')
os.chdir(r'S:\大一寒假学习\movieposter')
img = requests.get(url).content # 返回的是bytes型也就是二进制的数据
with open(movie['name'] + '.jpg', 'wb') as f:
f.write(img)
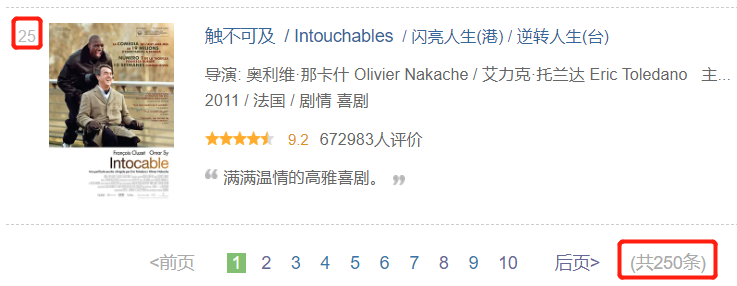
最后添加循环,爬取所有电影的海报图片以及相关信息:
每一页有25部电影,一共十页:
每一页的URL通过以下方式决定:
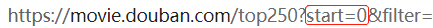
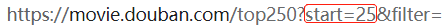
import pandas as pd
if __name__ == '__main__':
MOVIES = []
IMGURLS = []
for i in range(10):
url = "https://movie.douban.com/top250?start=" + str(i*25) + "&filter="
html = get_html(url)
movies = parse_html(html)[0]
imgurls = parse_html(html)[1]
MOVIES.extend(movies)
IMGURLS.extend(imgurls)
for i in range(250):
download_img(IMGURLS[i], MOVIES[i])
print("正在下载第" + str(i+1) + "张图片……")
os.chdir(r'S:\大一寒假学习') # 记得把路径换回来
moviedata = pd.DataFrame(MOVIES) # 把电影相关信息转换为DataFrame数据格式
moviedata.to_csv('movie.csv')
print("电影相关信息存储成功!")
运行代码: