文章目录
内存
内存以1Byte=8bits来作为存储单位。操作系统寻址最小单位为字节,一个字节为8bit。
一个整形int占4Byte.在计算机中占用内存如下:

0x01-0x04对应的内存存储的就是整体int a,所以我们可以看到这时把它当作一个整体来对待。
如果是char类型则把2个byte来当作一个整体来对待,因为char占用2个byte
所以基本数据类型就是告诉内存应该如何存储数据。
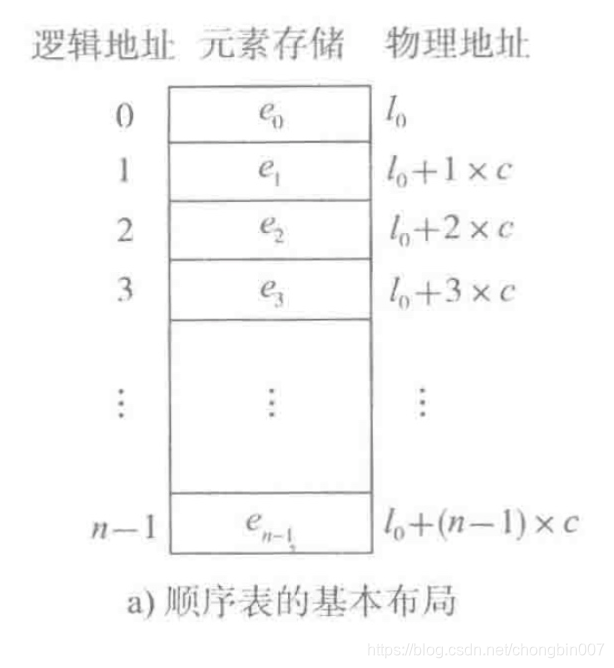
如果该数据结构是在内存中是连续存放的。则有如下结构

1. 顺序表的形式(元素内置vs外置)
元素内置与外置主要区分的是是否存在与同一块连续内存区而决定的存储元素类型是否相同。
元素内置
将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示。
下图表示的是顺序表的基本形式,数据元素本身连续存储,每个元素所占的存储单元大小固定相同。例如java中的array元素类型要相同。
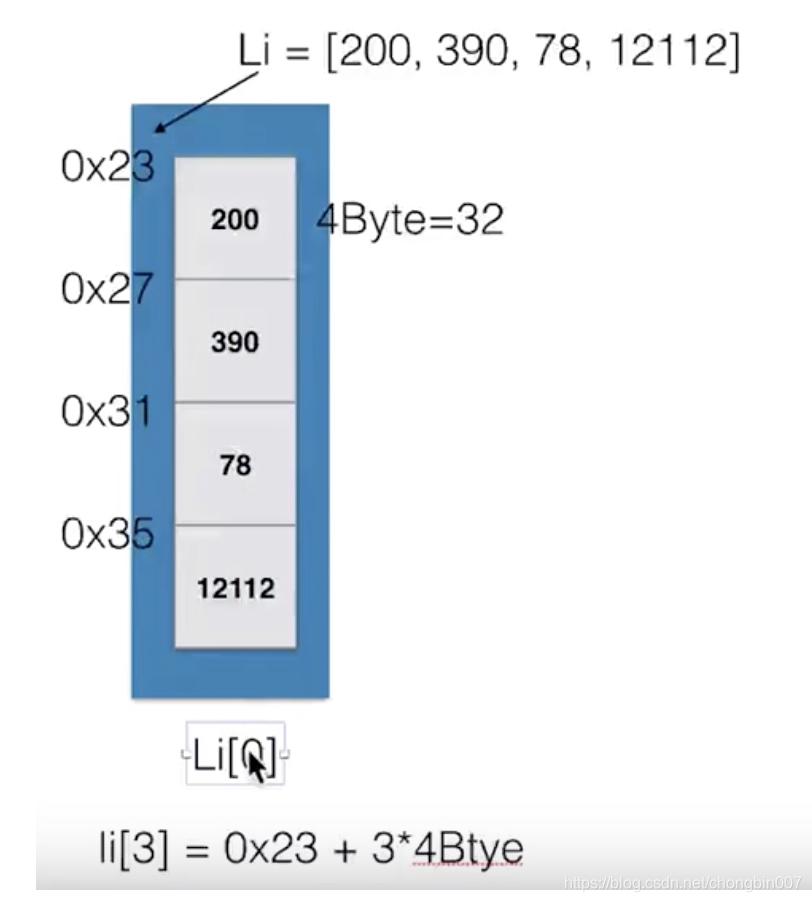
依次把这组数据存入内存,这组数据变量名为Li,Li其实代表的就是起始地址0x23;地址占用内存统一的为4Byte。
这时我想去读Li第0个元素为Li[0]。
而当我们要读Li[3],开始我们需要从头开始找0x23往后走3步也就是走到0x23+3*4Byte=0x35,到这个地址的时候就可以返回该地址存储的值了。
这时我们就知道为何数组存储要从Li[0]开始,这里的角标起始代表的就是偏移量,计算机通过偏移量来得到目标地址,如Li[3]就计算偏移量为3的地址。
故,访问指定元素时无需从头遍历,通过计算便可获得对应地址,其时间复杂度为O(1)。
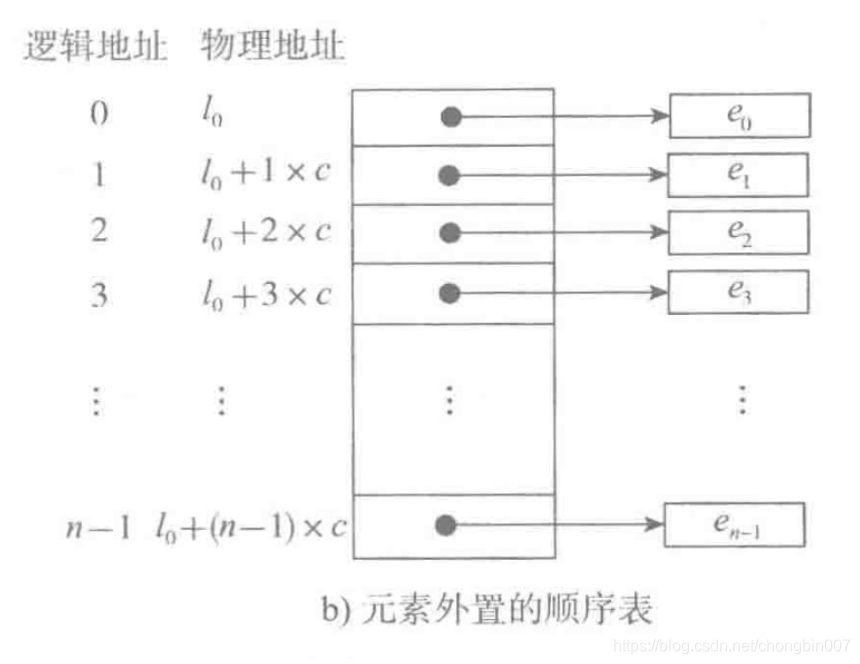
元素外置
如果元素的大小不统一如python中的list存储元素类型可以不同。则须采用图b的元素外置的形式,将实际数据元素另行存储,而顺序表中各单元位置保存对应元素的地址信息(即链接)。注意,图b中的c不再是数据元素的大小,而是存储一个链接地址所需的存储量,这个量通常很小与int型一样为4Byte。
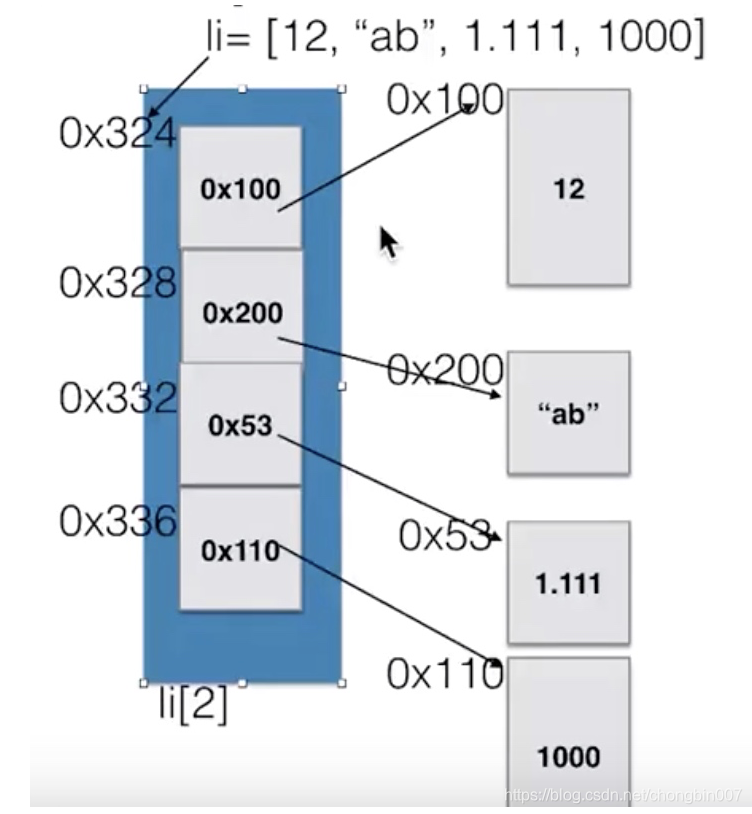
找一个位置把每个数据存起来,但是每个数据的地址可以不连续。
这时每个地址指向对应数据,而这时我们找一块连续的内存把每个数据的地址存储起来。
这块连续空间存储全部都是地址,每个地址指向一个数据内存。
这时Li[0]为0x324地址,然后找到该地址中的数据0x100然后找到0x100指向的内存空间为数据12。
也就是把数据存储到顺序表之外,元素外置,可以存储不同的数据类型。
图b这样的顺序表也被称为对实际数据的索引,这是最简单的索引结构。
2. 顺序表结构(一体式vs分离式)
一个顺序表的完整信息包括两部分,一部分是表中的元素存储区,另一部分为表头信息:主要包括元素存储区的容量和当前表中已存的元素个数。
一体式和分离式主要决定的是存储区大小是否为固定的。

一体式存储
表头信息和数据区一起存储

存储表信息的单元与元素存储区以连续的方式安排在一块存储区里,两部分数据的整体形成一个完整的顺序表对象。
一体式结构整体性强,易于管理。但是由于数据元素存储区域是表对象的一部分,顺序表创建后,元素存储区就固定了。比如java中的数组。大小是固定的
更换数据
所以若想更换数据区,则只能整体搬迁,即整个顺序表对象(指存储顺序表的结构信息的区域)改变了。
分离式存储
表头信息和存储区分开存储
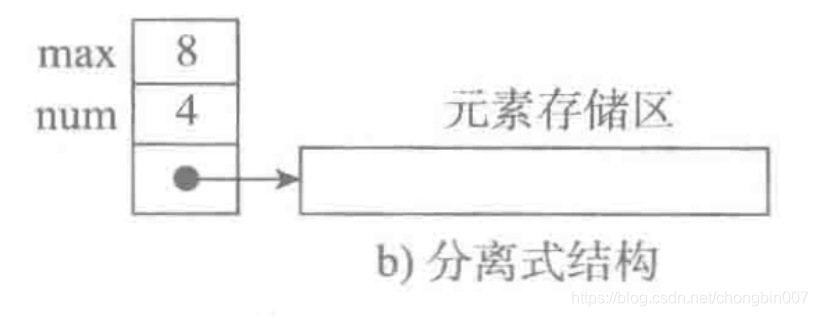
采用分离式间接访问,多了一次计算。
表对象里只保存与整个表有关的信息(即容量和元素个数),实际数据元素存放在另一个独立的元素存储区里,通过链接与基本表对象关联。类似于java的List
为了考虑数据动态变化,尽量使用分离式。
更换数据
若想更换数据区,只需将表信息区中的数据区链接地址更新即可,而该顺序表对象不变。
人们把采用这种技术实现的顺序表称为动态顺序表,因为其容量可以在使用中动态变化。
数据区扩充
当进行存储区扩充时,相当于新建一个存储区,但是新建这个存储区究竟要多大。
扩充的两种策略:
- 每次扩充增加固定数目的存储位置,如每次扩充增加10个元素位置,这种策略可称为线性增长。特点:节省空间,但是扩充操作频繁,操作次数多。
- 每次扩充容量加倍,如每次扩充增加一倍存储空间。特点:减少了扩充操作的执行次数,但可能会浪费空间资源。以空间换时间, 推荐的方式 。
3. 顺序表的操作
增加元素
当我们容量为8,现在数字为4,我们想添加一个元素111时:
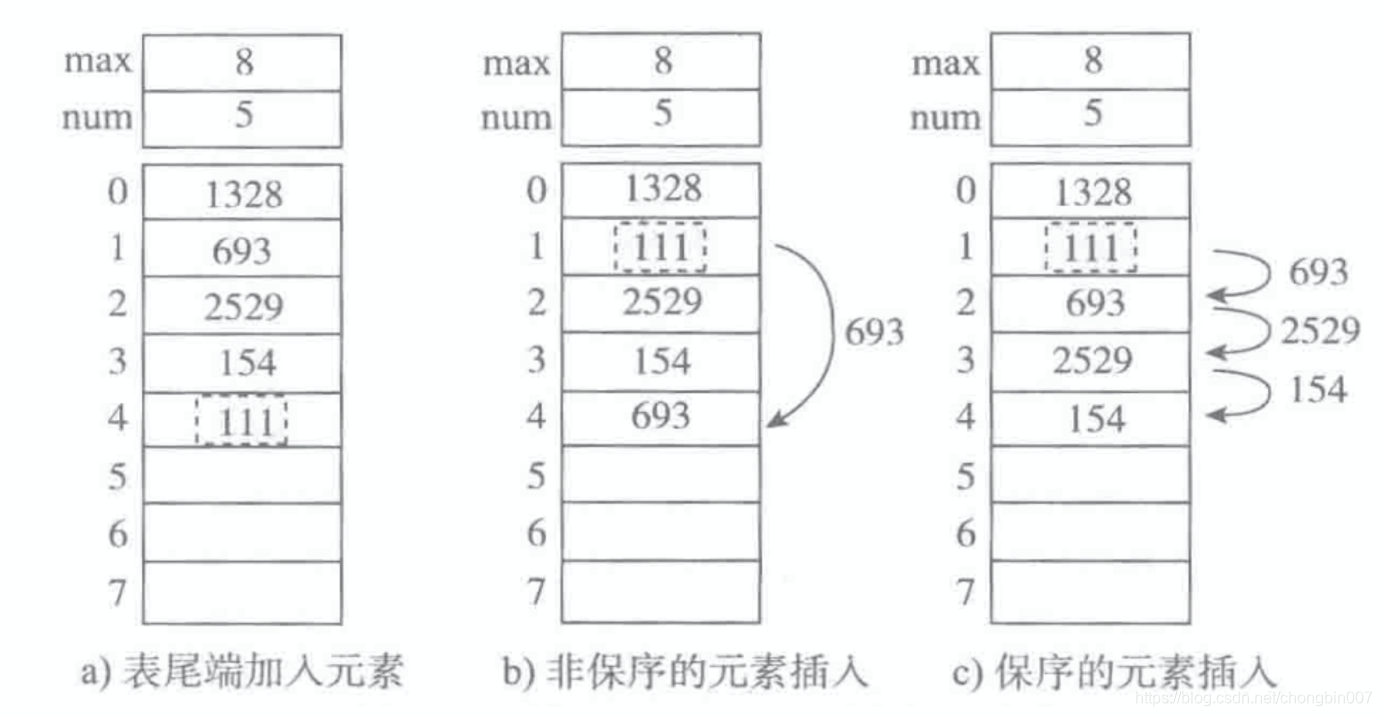
- 尾端加入元素,直接加,时间复杂度为O(1)
- 非保序的加入元素(不常见),时间复杂度为O(1)
- 保序的元素插入,插入到[1]到位置,我们需要把111放到位置[1],后面的元素都需要向后移一位。
比如我们要插入队头,那么后面元素都向后移一位,也就是操作n次,那么时间复杂度为O(n)。、
删除元素
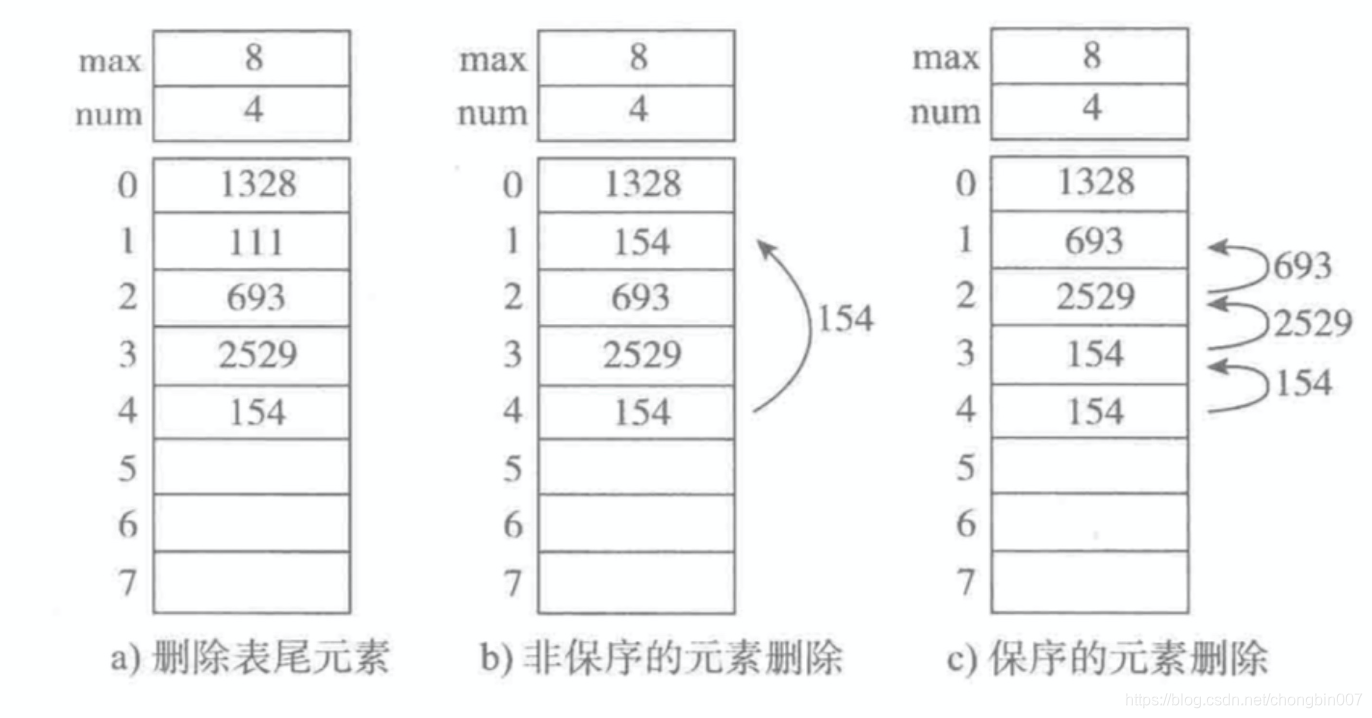
- 删除表尾元素,时间复杂度为O(1)
- 非保序的元素删除(不常见),时间复杂度为O(1)
- 保序的元素删除,表头删除之后,其他元素都向前提一位,时间复杂度为O(n)
4. python中的顺序表
Python中的list和tuple两种类型采用了顺序表的实现技术,tuple是不可变类型,即不变的顺序表,因此不支持改变其内部状态的任何操作,而其他方面,则与list的性质类似。
List的基本实现技术
Python标准类型list就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
- 基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);
为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中,采用元素外置。 - 允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。
为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时list对象的标识id不变,只能采用分离式实现技术。
在Python的官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方实现中,list实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。
