贪心算法
1.概念:
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它所做出的仅仅是在某种意义上的局部最优解。贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性(即某个状态以后的过程不会影响以前的状态,只与当前状态有关。)
2.解题步骤:
1.将原问题分解为子问题;
2.找出贪心策略;
3.得到每一个子问题的最优解;
4.将所有的局部最优解的集合构成称为原问题的一个解;
3.注意事项:
1.一般会结合排序,即首先通过排序的方式处理数据;
2.题型多变;
3.得到的解可能不是最优解;
4.一些使用贪心算法解决的算法题
4.1 合并果子
题目描述:
现在有n堆果子,第i堆有Ai个果子。现在要把这些果子合并成一堆,每次合并的代价是两堆果子的总果子数。求合并所有果子的最小代价。
Sample Input : 5、8、3、2、6、1
Sample Output: 59
分析:我们要把果子合并成一堆,每一次都只能两两合并,且合并时耗费的体力是两堆果子个数之和。开始的时候我们并不知具体的合并策略,所以我们可以试着去猜测一下怎么合并。特殊地,我们可以每次选择最大的两个果子来进行合并;此外,我们还可以每次选择最小的两个果子来进行合并。结果如下:
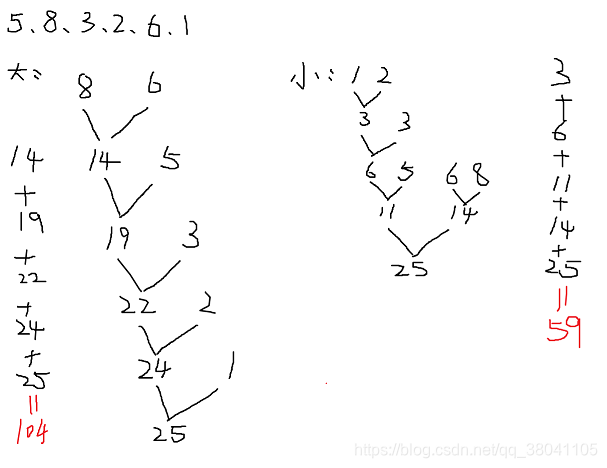
很明显,每次合并果子数最少的两个堆最后花费的体力最少(这里有点像一棵赫夫曼树)。所以,我们要每次挑果子数最少的两堆果子来合并。
代码如下:
//模拟6堆果子
int[] fruit = {5,8,3,2,6,1};
//合并果子
public int together_fruit(int[] fruit){
//使用优先队列存储果子
Queue<Integer> queue = new PriorityQueue<>();
for(int i=0;i<fruit.length;i++){
queue.add(fruit[i]);
}
//合并n堆果子需要有n-1次合并
int times = queue.size()-1;
//用于存储每次合并耗费的体力
int count = 0;
while(times-->0){
//每次出队两个元素,将两个元素的和入队
int A = queue.poll();
int B = queue.poll();
queue.add(A+B);
count += (A + B);
}
return count;
}
@Test
public void test5(){
System.out.println(together_fruit(fruit));
}
4.2 磁带的最优存储问题
问题描述:

分析:
由上面图中的读取程序i所需的时间tr我们可以看出,要读某个程序i,则读取程序i花费的时间是读取它前面的所有程序需要的时间加上读取它本身的时间。而一个程序本身的读取时间由这个程序的长度和频率决定,由上图我们知道这个关系是t = PL。故我们需要把每个程序PL计算出来,代表这个程序的读取时间,记为Ts(s为实际的意思)。
在操作系统的进程调度中我们知道短作业优先的调度方式,各进程的平均周转时间最短。故这道题很有可能是将Ts按照从小到大的顺序排列,能够使平均读取时间达到最短。
动态规划
1定义:
动态规划算法是通过拆分问题,定义问题状态和状态之间的关系,使得问题能够以递推(或者说分治)的方式去解决。
动态规划算法的基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
递归通常是将问题的规模从大往小。而动态规划是将原问题划分为小的子问题,通过解决一个个的子问题给大的问题提供信息,并一次解决问题。
基本思想与策略编辑:
由于动态规划解决的问题多数有重叠子问题这个特点,为减少重复计算,对每一个子问题只解一次,将其不同阶段的不同状态保存在一个二维数组中(精髓)。
2.动态规划算法题分析
2.1 选数字
从一组数中选出一个子序列满足以下条件:首先选出的数字不相邻;同时选出数字的和最大。如序列:4、1、1、9、1,
我们选9和4的时候和最大。
分析: 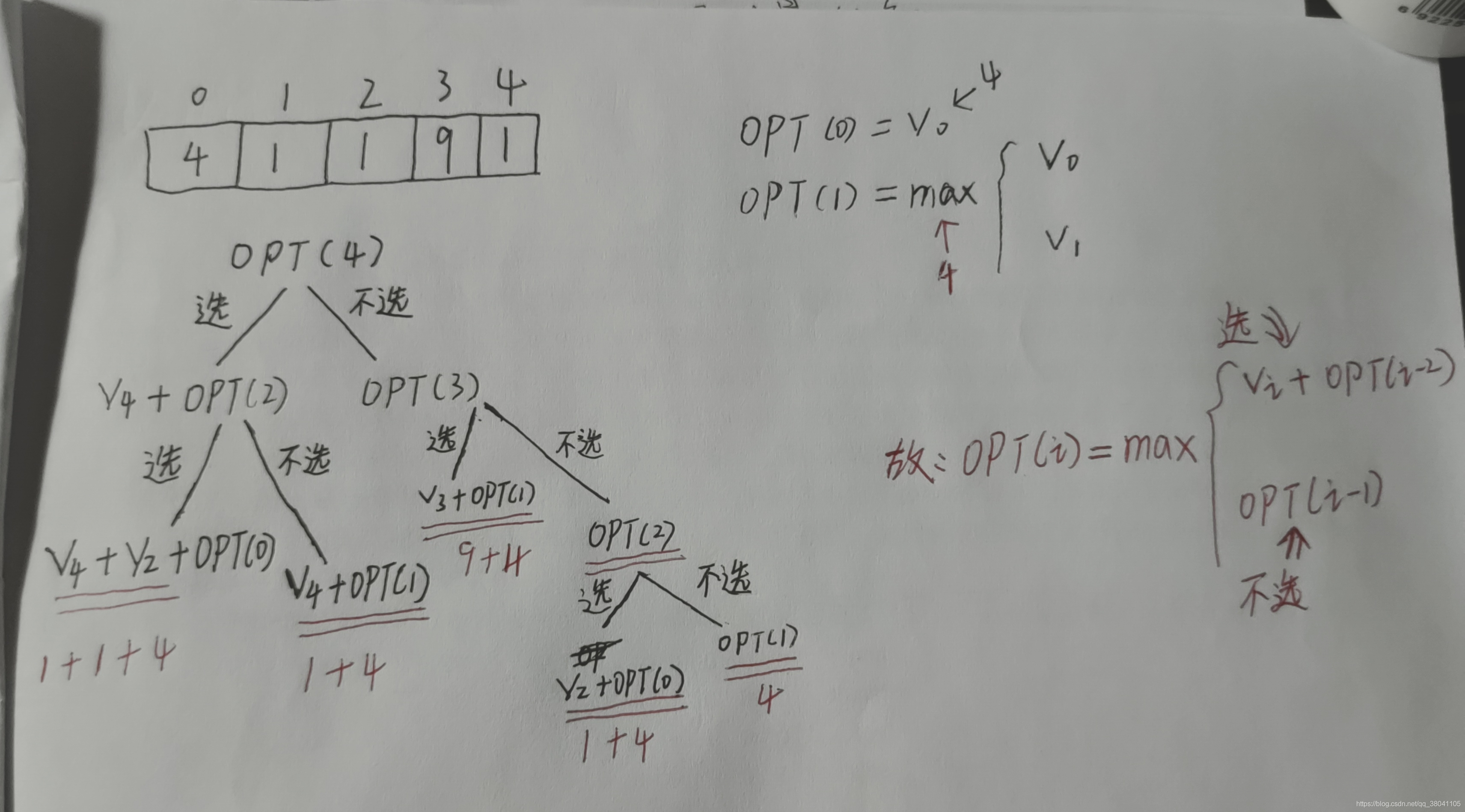 通过上面的分析很容易写出一个这道题的递归解法,代码如下:
通过上面的分析很容易写出一个这道题的递归解法,代码如下:
int[] nums = {1,2,4,1,7,8,3};
//递归的方式
public int rec_opt(int [] nums , int length){
//出口
if(length == 0){
return nums[0];
}
if(length == 1){
return Math.max(nums[0],nums[1]);
}
return Math.max(nums[length]+rec_opt(nums,length-2),rec_opt(nums,length-1));
}
需要注意的是上面方法的第二个参数length为nums.length-1,即最后一个数的数组下标。
但是递归做了很多无用的计算,如下图的OPT(2)有重复计算,在数据量较大的计算中这样会浪费很多的时间。
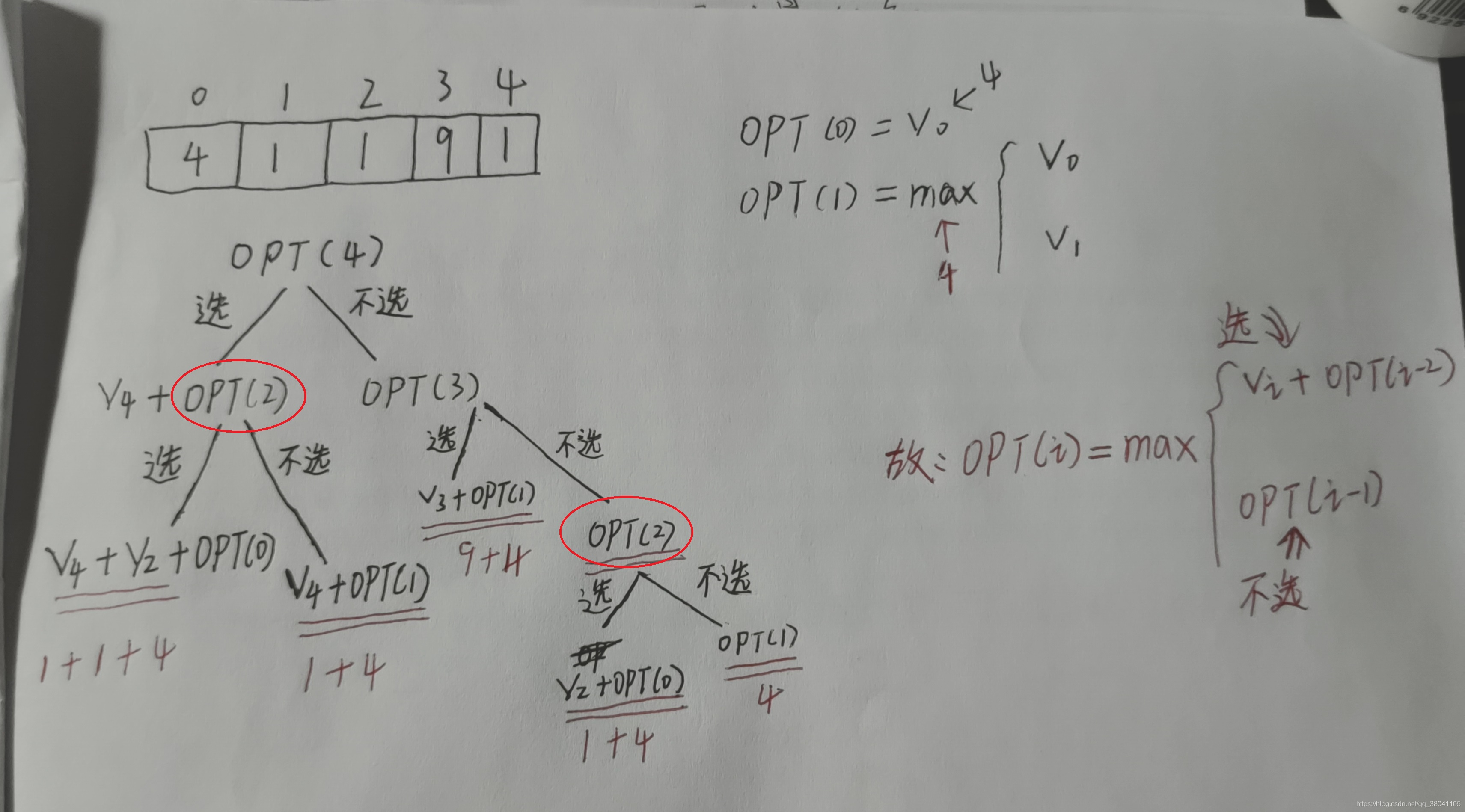 下面给出非递归实现的代码:
下面给出非递归实现的代码:
//非递归的方式
public int dp_opt(int[] nums){
//创建一个新数组
int[] opt =new int[nums.length];
opt[0] = nums[0];
opt[1] = Math.max(nums[0],nums[1]);
for(int i = 2;i<nums.length;i++){
opt[i] = Math.max(nums[i]+opt[i-2],opt[i-1]);
}
return opt[nums.length-1];
}
2.2 判断序列中能够拼出一个给定的值S
问题描述:给定一个序列arr,判断能否从序列中选出一个子序列,满足子序列中数字的和为给定的S。
例如:arr = { 3 , 34 , 4 , 12 , 5 , 2 },S=9 此时有子序列{ 4,5} 满足和为9,故返回true。
分析如下:
故很容易写出本题的递归代码:
int[] nums2 = {3,34,4,12,5,2};
public boolean rec_subset(int[] nums,int i,int S){
//1.S==0
if(S==0){
return true;
}
//i==0
else if(i==0){
//若最后一个数和S相等则返回true
if(nums[0] == S){
return true;
}else {
//否则,返回false
return false;
}
}
else if(nums[i]>S){
//此时不能选择i位置的值
return rec_subset(nums,i-1,S);
}
//即可选也可以不选,只有有一个满足即可
return rec_subset(nums,i-1,S) || rec_subset(nums,i-1,S-nums[i]);
}
同第一个题一样,递归的过程中有很多的重复计算,因此我们需要将其改为非递归的方式。前面说过,动态规划通常需要使用一个二维数组来保存之前子问题的相关信息,这道题的非递归方式实现就需要一个二维数组来存储相关信息。分析如下:
 当S=0时,我们可以直接返回true,对应上图就是第一列全为true;
当S=0时,我们可以直接返回true,对应上图就是第一列全为true;
当i=0时,只有nums[0] == S,才能返回T,对应上图就是(0,3)的位置为True,其余则都F。
知道了第0行和第0列,那么就可以根据之前的递推关系,把这个表填完整,具体代码如下:
public boolean subset(int[] nums,int S){
//构造二维数组
boolean[][] result = new boolean[nums.length][S+1];
//第0行除了nums[0] = i 的那一格为true,其余全为false
for(int i=0;i<S+1;i++){
if(nums[0] == i){
result[0][i] = true;
}else {
result[0][i] = false;
}
}
//第0列全为true
for(int j=0;j<nums.length;j++){
result[j][0] = true;
}
//为数组的后面部分赋值
for(int i=1;i<nums.length;i++){
for(int j=1;j<S+1;j++){
if(nums[i] > j){
result[i][j] = result[i-1][j];
}
else {
//不选
boolean A = result[i-1][j];
//选
boolean B = result[i-1][j-nums[i]];
result[i][j] = A || B;
}
}
}
调用结果:
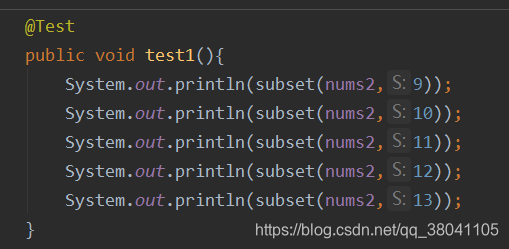
以上是我在学习贪心算法和动态规划时候的几个算法,如有错误,欢迎指正与讨论。
