分类评价结果
我们使用分类算法将训练集进行分类后,我们怎么判定分类算法的好坏,就需要用到相关指标。
混淆矩阵
使用条件:对于极度偏斜的数据,是不能使用混淆矩阵的。比如99.9%的人都会患癌症等。
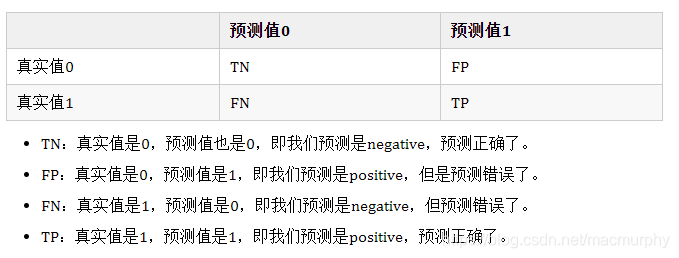
其中,
精准率=TP/(FP+TP),即预测值里面,准确的数据占比是多少。
召回率=TP/(FN+TP),即真实值里面,准确被预测的数据占比是多少。
那接下来的问题,两个指标中,在某个模型中,达到什么样的数据才是最好的?有没有可能混合成一个指标=两个指标的加权数值?
这种的话,就需要看需求进行评判了,当然能也有混合成一个指标的指标,即F1 SCORE,

sklearn调用方法:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_log_predict)
from sklearn.metrics import precision_score
precision_score(y_test, y_log_predict)
from sklearn.metrics import recall_score
recall_score(y_test, y_log_predict)
分类阈值:即预测中,超过多少才能被分成一类。
ROC曲线:
from sklearn.metrics import roc_curve
fprs, tprs, thresholds = roc_curve(y_test, decision_scores)
plt.plot(fprs, tprs)
plt.show()
AUC面积:
AUC是ROC曲线和X轴内的面积大小。

from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, decision_scores)
以上是对分类的评价。
线性回归
线性回归比较好理解,即做一条X自变量的Y应变量曲线,然后用R2来判定回归曲线的准确度。
sklearn调用方法:
from sklearn.metrics import r2_score
r2_score(y_test, y_predict)
拆分训练集和测试集方法
方法核心是将索引进行随机排序,然后再把索引对应到数组中进行取值。
