distinct算子原理:
贴上spark源码:
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
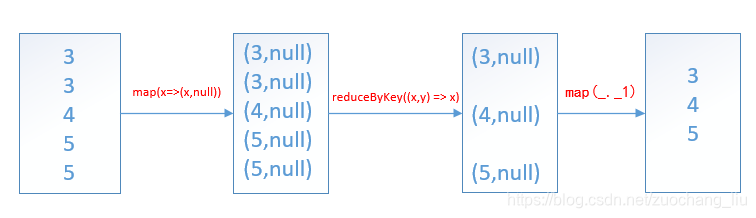
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}示例代码:
package com.wedoctor.utils.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object Test {
Logger.getLogger("org").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
//本地环境需要加上
System.setProperty("HADOOP_USER_NAME", "root")
val session: SparkSession = SparkSession.builder()
.master("local[*]")
.appName(this.getClass.getSimpleName)
.getOrCreate()
val value: RDD[Int] = session.sparkContext.makeRDD(Array(3,3,4,5,5))
value.distinct().foreach(println)
//等价于
value.map(x=>(x,null)).reduceByKey((x,y) => x).map(_._1).foreach(println)
session.close()
}
}