内存
1 操作系统如何管理内存
1.1 计算机体系结构
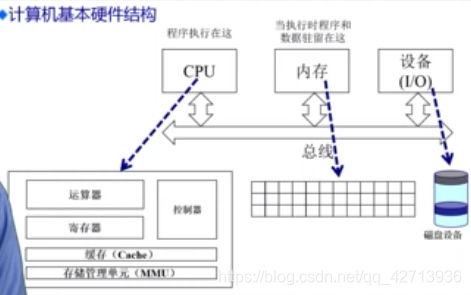
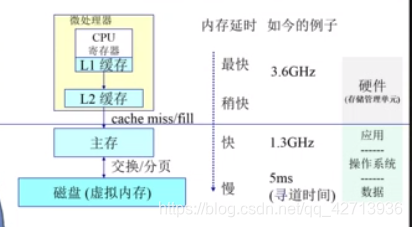
CPU可以访问管理cache和计算机,os不能管理他们,因为他们在CPU内部,他们速度快,容量小
主存(物理内存):容量大速度慢,os相关的放在这,掉电就没了
硬盘(虚拟内存):掉电后存储的东西不消失,速度更慢容量更大
操作系统在内存管理方面需重点完成的:
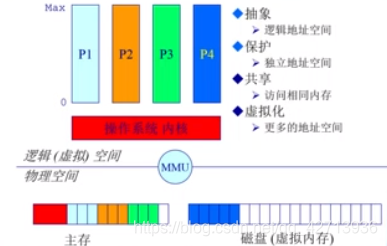
P1 P2 P3放在内存中,均可以轮流有效执行
P4因为需要等待某事件所有把所有数据都放在了磁盘,当满足了某事件后,就可以回到内存去执行

1.2 地址空间与地址生成
1.2.1. 地址空间定义
物理地址空间——硬件支持的地址空间
- 起始地址0,到地址MAXsys
- 包括主存和磁盘
逻辑地址空间——一个与你性的程序所需有的内存范围
- 起始地址0,到地址MAXprog
- z在程序中的地址从哪来?给出的是在程序地址空间中的逻辑地址,然后由os协调放在主存还是硬盘中
1.2.2 地址生成
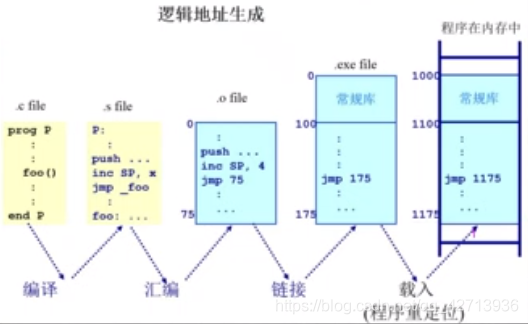
基于符号的地址空间(程序中的)找到逻辑地址(编译器等完成)
- c程序->汇编语言->机器语言->(llinker把多个程序变为一个单一的程序).exe file(可执行,放在硬盘中)->放在内存中运行(带有偏移量,依旧是逻辑地址)
- 不需要os,全程是应用程序、编译器等等
逻辑地址到物理地址(os完成)
-
CPU方面:
- 1、 运算器需要在逻辑地址的内存内容(ALU发出请求)
- 2、内存管理单元寻找在逻辑地址和物理地址之间的映射(在MMU查找映射,找到返回,未找到就去内存中找)
- 3、控制器从总线发送在物理地址的内存内容的请求
-
内存方面
- 4、内存发送物理地址内存的内容给CPU
-
操作系统方面
- 建立逻辑地址和物理地址间的映射
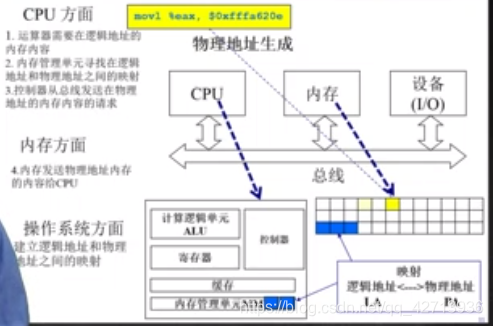
- 建立逻辑地址和物理地址间的映射
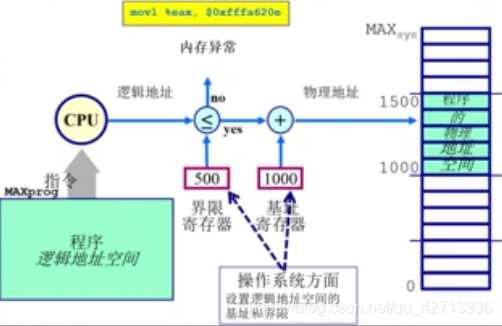
1.2.3 地址安全检查
操作系统要确保每个程序访问地址不受干扰,确保每个程序访问的地址空间是合法的。每次程序查这个map,他要访问的逻辑地址是否满足这个限制,满足继续执行,不满足发出一个内存异常,与操作系统再来处理
1.3 连续内存分配:内存碎片与分区的动态分配
1.3.1 内存碎片问题
- 空闲内存不能被利用
- 外部碎片
- 在分配单元
间的未使用内存
- 在分配单元
- 内部碎片
- 在分配单元
中的未使用内存(已经分配给了应用程序,但应用程序无法使用这些内存空间)
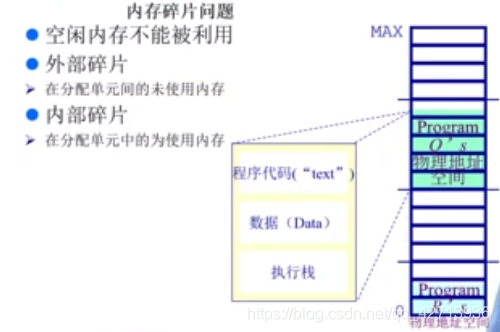
- 在分配单元
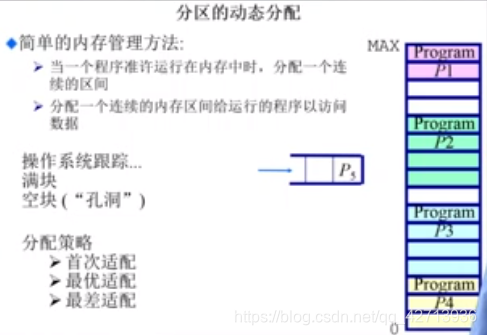
1.3.2 分区的动态分配
简单的内存管理方法:
- 当一个程序准许运行在内存中时(程序从硬盘加载到内存中),分配一个连续的空间
- 分配一个连续的内存区间给运行的程序以访问数据
第一适配
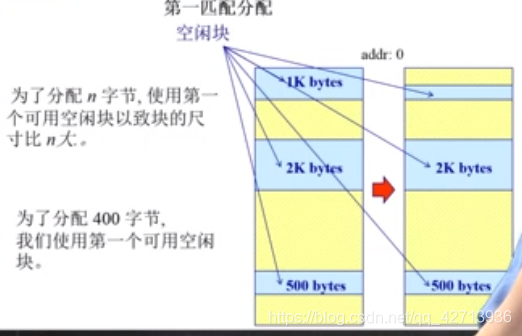
基本原理 & 实现:
- 简单实现
- 需求
- 按地址排序的空闲块列表
- 分配需要寻找一个合适的分区
- 重分配需要检查,看是否自由分区能合并于相邻的空闲分区(若有)
- (从低地址开始找,找到一个合适的就使用,期间还要关注地址空间的回收,若回收区域与相邻区域均为空闲分区,则合并)
优势
- 简单
- 易产生更大空闲块,向着地址空间的结尾(找到一个合适的就行,后面有更大的空间也不会因为被插入了个小的被浪费了)
劣势
- 外部碎片(两块之间的小碎片不易被使用)
- 不确定性(某些情况下会不适用)
最佳适配
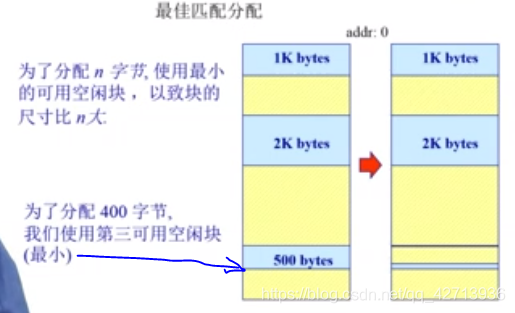
基本原理 & 实现
-
为了避免分隔大空闲块
-
为了最小化外部碎片产生的尺寸
-
需求:
- 按空闲块尺寸大小排列的空闲块列表
- 分配需要寻找一个合适的分区
- 重分配需要搜索及合并于相邻的空闲分区(若有)
-
优势
- 当大部分分配是小尺寸时非常有效
- 比较简单
-
劣势
- 外部碎片
- 重分配慢
- 易产生很多没用的微小碎片(不怎么好)
最差适配
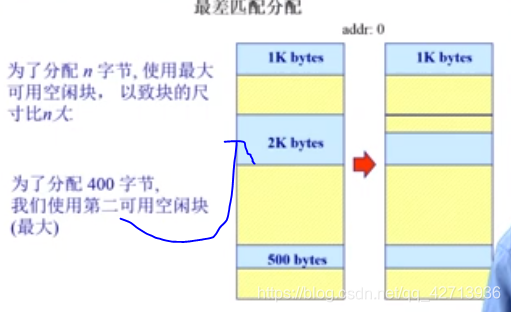
基本原理 & 实现
- 为了避免有太多微小的碎片
- 需求:
- 按尺寸排列的空闲块列表
- 分配很快(获得最大的分区)
- 重分配需要合并于相邻的空闲分区(若有),然后调整空闲块列表
优势
- 假如分配是中等尺寸效果最好(中大型地址空间最好)
劣势
- 重分配慢
- 外部碎片
- 易于破碎大的空闲块以致大分区无法被分配
- (请求大的地址空间,分配后,再次请求大的不容易被分配了)
没有一种算法是一直都使用的
接下来就要考虑如何更好的利用这些碎片化空间,使碎片减少或消失
1.4 连续内存分配:压缩式与交换式碎片整理
1.4.1 压缩式碎片整理
重置程序以合并空洞
要求所有程序是动态可重置的
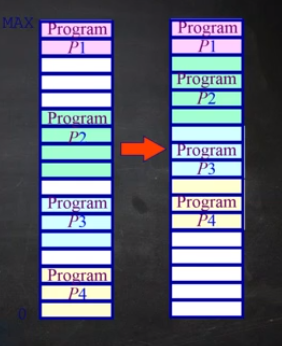
当有一个程序需要5个空闲块时,上左图不能满足,这时,就要考虑如何将程序拷贝,使每个程序之间不留内存空闲快
问题:
何时?
- 程序运行时不能,因为万一一挪,就有可能导致后续程序请求地址时找不到
- 程序等待使可以
开销 - 内存拷贝开销很大,纯靠软件开销较大
1.4.2 交换式碎片整理
运行程序需要更多的内存
抢占等待的程序 & 回收他们的内存
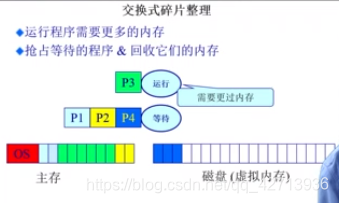
当P3正在运行时,P3需要占用更多的空间,而此时,内存空间已经被P1P2P3P4占满了,靠挪空间已无效果,此时,可以将正在等待的P4程序的数据等拷贝到磁盘中,空出的3个内存块给P3使用。当P4执行时,P3可能就不需要那么多内存了,再把P4拷回来
问题:
把那个程序拷出去
什么时候换入换出(程序较大时开销较大)
连续内存中换入换出的都是大的整个程序快,如何把这些换成小的块来换入换出话需要考虑
1.5 非连续内存分配(分段)
1.5.1 为什么需要非连续内存分配
连续内存分配的缺点:
- 分配给一个程序的物理内存是连续的
- 内存利用率较低
- 由外碎片、内碎片的问题
非连续分配的优点:
- 一个程序的物理地址空间是非连续的
- 更好的内存管理和利用
- 允许共享代码与数据(共享库等)
- 支持动态加载和动态链接
非连续分配的缺点:
- 如何建立虚拟地址和物理地址间的转换
- 软件方案
- 硬件方案
- 两种硬件方案:分段和分页
1.5.2 分段
程序的分段地址空间
在代码执行方面:有总程序、子程序、共享的库
数据有栈段、堆段、共享数据段
分段:更好的分离和管理
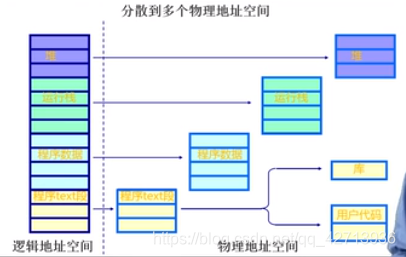
逻辑地址空间是连续的
物理地址空间是不连续的
中间需要映射机制
更有利于数据的共享和管理
又如:
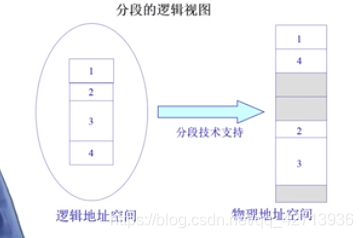
用软件来处理映射开销较大,所以考虑使用硬件
分段寻址方案
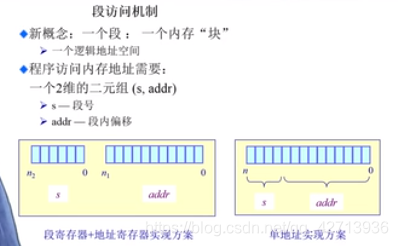
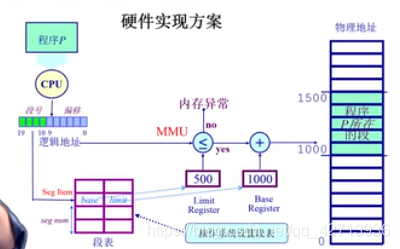
虚拟地址空间映射到物理地址空间,物理地址空间由段组成
把逻辑地址分为2块,上半部分是段号,下半部分是段内偏移
通过段号来找到物理地址的段号,使用的是段表,里面存了映射关系,即逻辑地址段号和物理地址段好的对应关系
每个段大小是不一样的,需要了解它的起始地址和长度(这是段表里比较重要的2个信息)
段表的索引(index,哪一项的位置)由段号来决定
查到后的地址和长度限制,CPU查看要访问的是否符合这个限制,不符合,异常,符合,则把起始地址加上偏移量形成物理地址,去除数据,CPU继续处理
段表由os在寻址之前建立
1.6 非连续内存分配(分页)
分段用的是比较少的,主要用分页
分页也有页号和业内偏移
分页与分段区别:分段的段的尺寸是可变的,页的大小是不变的
1.6.1 分页地址空间
- 划分物理内存至固定大小的帧(分成的每一个页)
- 大小是2的幂,如 512,4096,8192
- 划分逻辑地址空间至相同大小的页(页的大小)
- 大小是2的幂,如 512,4096,8192
- 建立方案 转换逻辑地址为物理地址(pages to frames)
- 页表
- MMU(CPU中)/TLB(快表完成对页表的缓存)
帧(Frame)
物理内存被分隔成大小相等的帧- 一个内存物理地址是一个二元组(f,o)
- f——帧号(F位,共有2F帧)
- o——帧内偏移(S位,每帧有2S字节)
- 物理地址=2s *f + o
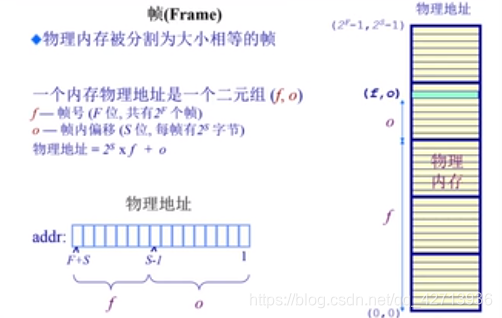
- 地址计算的实例
- 16bit的地址空间,9bit(512byte)大小的页帧,物理地址=(3,6),求?
- 9bit 用来表示帧内偏移,16bit-9bit=7bit用来表示帧号,则F=7,S=9
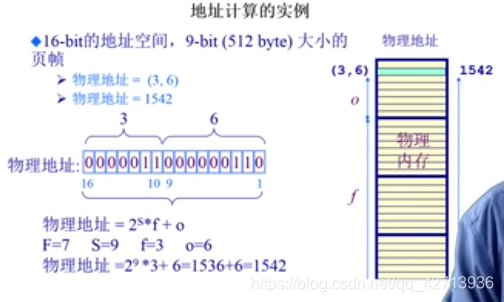
页
- 一个程序的
逻辑地址空间被划分为大小相等的页- 页内偏移大小=帧内偏移的大小(每一个页的大小和每一帧的大小同)
- 页号大小可能不等于帧号大小
- 一个逻辑地址是一个二元组(p,o)
- p —— 页号(P位,2P个页)
- o —— 页内偏移(S位,每页有2S字节)
- 虚拟地址=2S *p+o
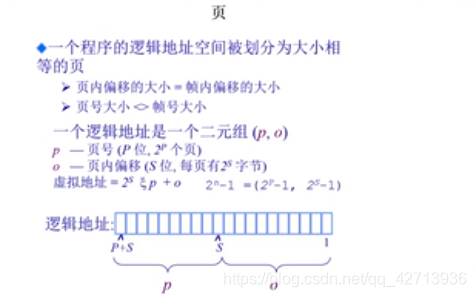
1.6.2 页寻址方案
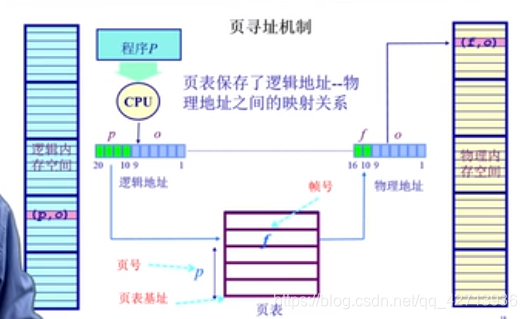
由逻辑地址中的页号作为一个索引去查页表(还需要知道从哪开始查,即页表基地址),查出该索引对应的页表项——帧号,把帧号和偏移量相加,得物理地址
页表由os建立
与段不同的地方:
页的逻辑地址和物理地址中的偏移量是一样的,所以不用像分段还要考虑大小不一致的问题
逻辑地址空间(连续)>物理地址空间(分散)
逻连续物理分散有助于减少
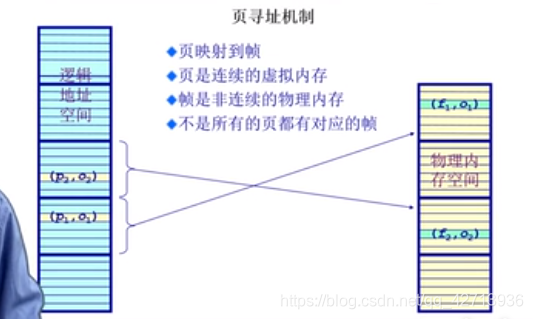
1.6.3 页表
概述
页表结构
- 每个运行的程序都有一个页表
- 属于程序运行状态,会动态变化
- PTBR:页表基址寄存器
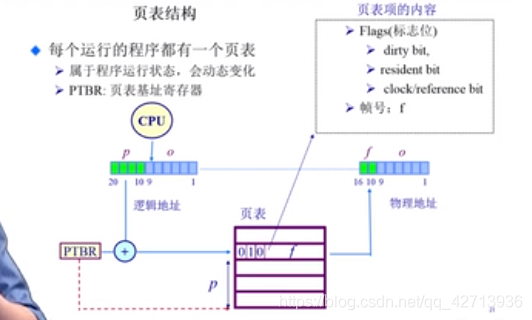
页表其实是一个大数组,它的索引,即页号,对应的页表项的内容为帧号
过程:
- CPU查出该页表的起始地址
- 通过页号(page index)算出帧号
- 帧号加偏移量得物理地址
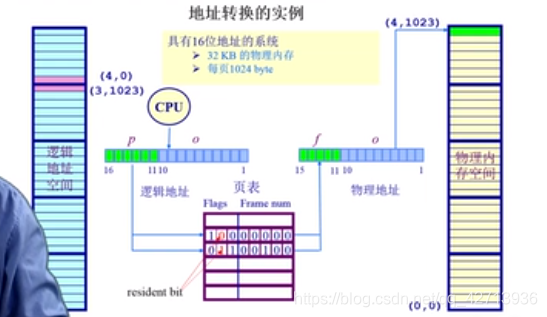
上图实例:
逻辑地址:26 =64K
物理地址:25 =32K(关于这的计算还需要再看看)
所以不是所有的逻辑地址都有对应的物理地址
逻辑地址(4,0)代表页号:4,偏移量:0,去查页表,从下往上数0,1,2,3,4第5个,它的resident bit(驻留位)为0(此逻辑地址无对应的物理地址)。内存访问异常,os继续处理,非法访问则将运行的程序杀死,(页表在程序运行前就已建立)
逻辑地址(3,1023)代表页号:3,偏移量:1023,去查页表,从下往上数0,1,2,3第4个,它的resident bit(驻留位)为1(此逻辑地址有对应的物理地址),取出帧号与偏移量相加,得物理地址(4,1023)
分页机制的性能问题(速度和空间开销)
-
页表可能非常大
- 64位机器如果每页1024字节,那么一个页表的大小会是多少
- 寻址空间:264
- 一页大小:1024字节=1k=210
- 一个页表的大小:264 /210 =254 (太大了)
- 如果每个程序都有一个页表,那么n个将会有n个页表,很耗空间
- 64位机器如果每页1024字节,那么一个页表的大小会是多少
-
页表很大的话,CPU放不下,就要放在内存,所以就会访问2次内存
- 问题:访问一个内存单元需要2次内存访问
- 一次用于获取页表项(访问页表)
- 一次用于访问数据(访问物理数据)
- 问题:访问一个内存单元需要2次内存访问
-
如何处理?(提示:大部分的计算问题可通过某些方式解决)
- 缓存(Caching):把最常用的大小放到离CPU最近的地方,如Cache,提升访问速度
- 间接(Indirection)访问:把很大的空间拆成很小的空间
TLB(时间解决方法,缓存)
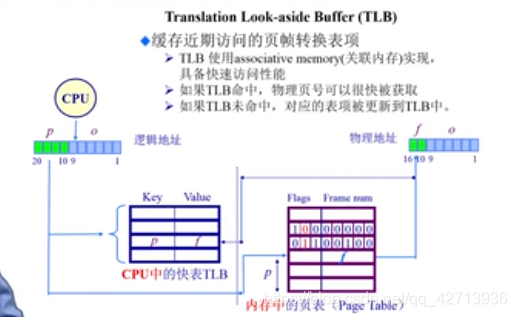
得到的p先去查快表,若有,则取出f直接与o相加;若没有,再去查页表
TLB缺失会不会很大?通常而言,32位系统,1个页4K,访问4K次才会导致TLB的缺失,通过某种机制使得这种缺失变小,这种机制就是写程序时尽量具有局部性,把平时的访问集中到一个区域
TLBmiss后,对于x86系统是通过硬件来从页表中取出到TLB中,而有的是通过os来实现的
多级的页表(解决空间效率问题)
二级页表
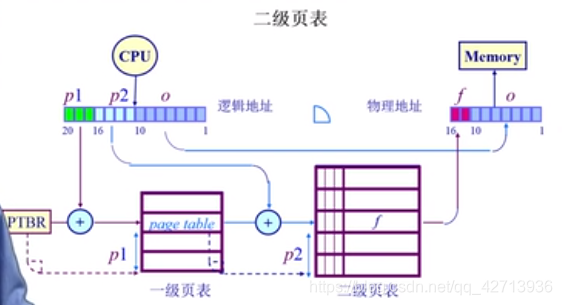
把单一的table分为2块,逻辑地址的p分为p1(对应1级页表页号),p2(对应2级页表页号),使得对大地址的寻址变为n个小的页表的寻址,而不是对很大的页表进行寻址。
首先,对于一级页表,它的起始地址CPU知道,所以加上p1,得到页表项(存的是2级页表的起始地址),与p2相加,得二级页表的页表项,即f
处理过程多了一次查找寻址处理,但使得某一些不存在映射关系的页表项就不会占用内存了,如p1指向的某一页表项不存在,则不需要在查二级页表,节省了空间
多级页表
时间来换空间
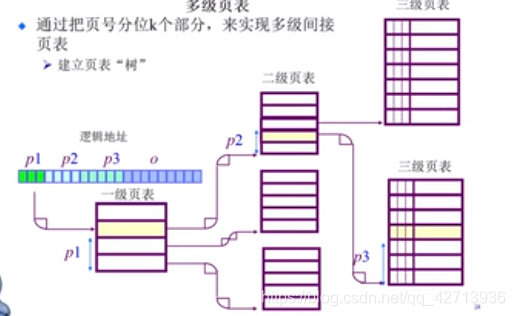
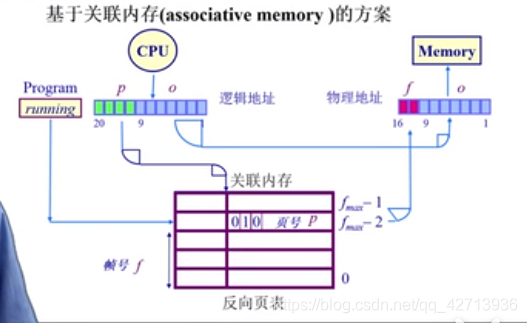
反向页表
逻辑地址空间越大,对应的页表越多
使得页表大小与逻辑地址无关,而与物理地址有关

帧号为索引,页表项为页号
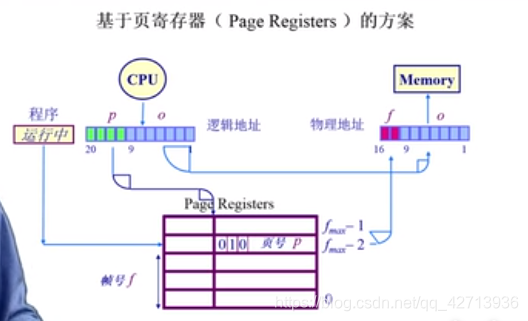
使用页寄存器
问题:怎么根据页号找到页帧号?


基于外联内存(associative memory)的方案
硬件逻辑很复杂
还需要放在CPU内
成本代价导致无法做的很大

基于哈希(hash)查找的方案
以上2者不够实用
哈希函数是数学计算方法,输入一个页号输出帧号,可用软件,也可硬件加速,采用硬件加速
加一个PID,当前运行程序的标识,PID加页号作为输入,算出对应的帧号
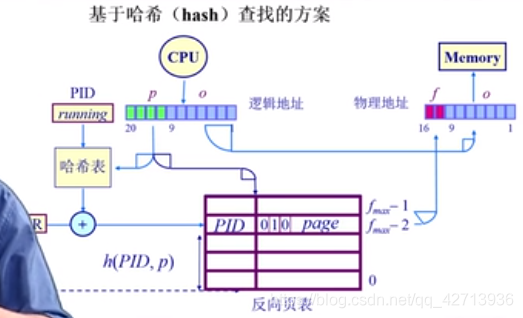
问题:
- 一个输入可能会有多个输出,要选出那个是真的帧号
- 做哈希计算,也需要到内存中取数,需要TLB

好处: - 不受制于逻辑地址空间,只跟物理地址空间有关,且较小
- 多级页表每个运行的程序都需要一个页表,而这个整个系统只需要1个页表
代价:
需要高速的哈希运算机制
